Transformers in Machine Learning (original) (raw)
Last Updated : 10 Dec, 2025
Transformer is a neural network architecture used for performing machine learning tasks particularly in natural language processing (NLP) and computer vision. In 2017 Vaswani et al. published a paper " Attention is All You Need" in which the transformers architecture was introduced. The article explores the architecture, workings and applications of transformers.
Need For Transformers Model in Machine Learning
Transformer architecture uses an attention mechanism to process an entire sentence at once instead of reading words one by one. This is useful because older models work step by step and it helps overcome the challenges seen in models like RNNs and LSTMs.
- Traditional models like RNNs (Recurrent Neural Networks) suffer from the vanishing gradient problem which leads to long-term memory loss.
- RNNs process text sequentially meaning they analyze words one at a time.
**For example:
In the sentence: "XYZ went to France in 2019 when there were no cases of COVID and there he met the president of that country" the word "that country" refers to "France".
However RNN would struggle to link "that country" to "France" since it processes each word in sequence leading to losing context over long sentences. This limitation prevents RNNs from understanding the full meaning of the sentence.
While adding more memory cells in LSTMs (Long Short-Term Memory networks) helped address the vanishing gradient issue they still process words one by one. This sequential processing means LSTMs can't analyze an entire sentence at once.
**For example:
The word "point" has different meanings in these two sentences:
- "The needle has a sharp point." (Point = Tip)
- "It is not polite to point at people." (Point = Gesture)
Traditional models struggle with this context dependence, whereas Transformer model through its self-attention mechanism processes the entire sentence in parallel addressing these issues and making it significantly more effective at understanding context.
Core Concepts of Transformers
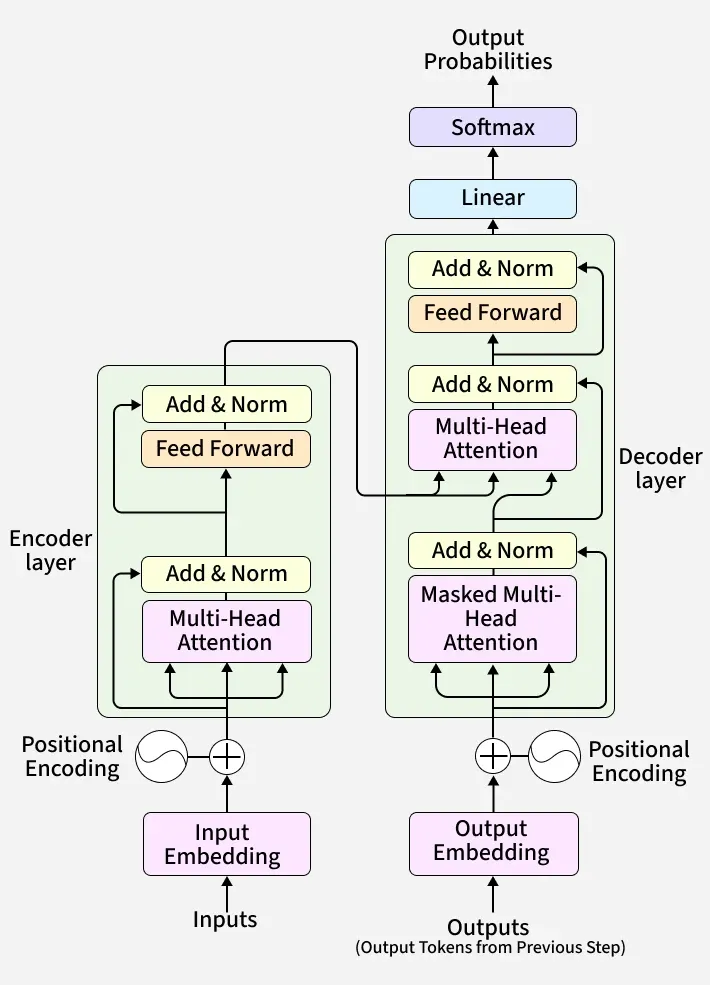
Architecture of Transformer
1. Self Attention Mechanism
The self attention mechanism allows transformers to determine which words in a sentence are most relevant to each other. This is done using a scaled dot-product attention approach:
Each word in a sequence is mapped to three vectors:
- **Query (Q)
- **Key (K)
- **Value (V)
Attention scores are computed as: \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V
These scores determine how much attention each word should pay to others.
2. Multi-Head Attention
Instead of one attention mechanism, transformers use multiple attention heads running in parallel. Each head captures different relationships or patterns in the data, enriching the model’s understanding.
3. Positional Encoding
Unlike RNNs, transformers lack an inherent understanding of word order since they process data in parallel. To solve this problem Positional Encodings are added to token embeddings providing information about the position of each token within a sequence.
4. Position-wise Feed-Forward Networks
The Feed-Forward Networks consist of two linear transformations with a ReLU activation. It is applied independently to each position in the sequence.
Mathematically:
\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
This transformation helps refine the encoded representation at each position.
5. Embeddings
Transformers cannot work with raw words as they need numbers. So, each input token (word or subword) is converted into a vector, called an embedding.
- Both encoder input tokens and decoder input tokens are converted into embeddings.
- These embeddings are trainable, meaning the model learns the best numeric representation for each token.
- The same weight matrix is shared for Encoder embeddings, Decoder embeddings and the final linear layer before softmax
- The embeddings are scaled by model to keep values stable before adding positional encoding.
Embeddings turn words into meaningful numeric vectors that the transformer can process.
6. Encoder-Decoder Architecture
The **encoder-decoder structure is key to transformer models. The encoder processes the input sequence into a vector, while the decoder converts this vector back into a sequence. Each encoder and decoder layer includes self-attention and feed-forward layers.
For example, a French sentence "Je suis étudiant" is translated into "I am a student" in English.
Transformers apply attention in three different places:
**1. Encoder Self-Attention
- Q, K, V all come from the encoder’s previous layer.
- Every word can attend to every other word in the input.
- This helps the encoder understand full context (long-range meaning).
**2. Decoder Self-Attention (Masked)
- Q, K, V all come from the decoder’s previous layer.
- Future tokens are masked (blocked), so each position only sees previous tokens.
- This keeps decoding auto-regressive i.e the model predicts one word at a time.
**3. Encoder–Decoder Attention
- Queries come from the decoder.
- Keys and Values come from the encoder output.
- This lets the decoder look at important parts of the input sentence while generating output.
Together, these three attention types allow the transformer to read the entire input at once and then generate outputs step-by-step with full context.
7. Softmax Layer for Output Prediction
After the decoder processes the sequence, it must predict the next token.
- The decoder output is passed through a linear layer (whose weights are shared with embeddings).
- Then the softmax function converts these scores into probabilities.
- The token with the highest probability becomes the predicted next word.
Intuition with Example
For instance in the sentence "The cat didn't chase the mouse, because it was not hungry" the word 'it' refers to 'cat'. The self-attention mechanism helps the model correctly associate 'it' with 'cat' ensuring an accurate understanding of sentence structure.
Applications
Some of the applications of transformers are:
- **NLP Tasks: Transformers are used for machine translation, text summarization, named entity recognition and sentiment analysis.
- **Speech Recognition: They process audio signals to convert speech into transcribed text.
- **Computer Vision: Transformers are applied to image classification, object detection and image generation.
- **Recommendation Systems: They provide personalized recommendations based on user preferences.
- **Text and Music Generation: Transformers are used for generating text like articles and composing music.