Neural Network Architectures (original) (raw)
Last Updated : 30 Jan, 2026
Neural network architectures define the structural design of deep learning models, shaping how they process information, learn patterns and make predictions. From simple feed‑forward networks to advanced architectures like CNNs, RNNs, Transformers and hybrid models, each architecture is tailored to specific types of data and tasks.
- Different architectures excel in vision, language, time‑series and generative tasks
- The choice of architecture directly impacts performance, efficiency and accuracy
1. Single-Layer Feed-Forward Network
A single-layer feed-forward network connects input neurons directly to output neurons through a single set of weights. It does not contain hidden layers or feedback connections and information flows only in the forward direction. This architecture is suitable only for linearly separable problems.
- Contains only one trainable weight layer.
- Information flows strictly in one direction.
- Computationally efficient and simple to implement.
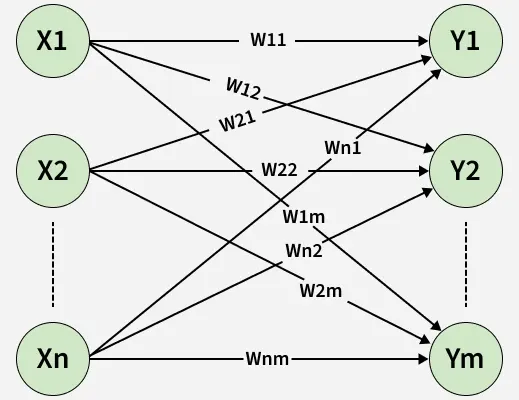
Single-Layer Feed-Forward Network
Working
- Input features are provided to the network.
- Each input is multiplied by its corresponding weight.
- A bias term is added to the weighted sum.
- The result passes through an activation function.
- The activated value produces the final output.
Use Cases
- **Binary Classification: Problems such as yes/no or true/false predictions.
- **Linear Regression Tasks: Predicting values with linear relationships.
- **Threshold-Based Decision Systems: Simple rule-based classifiers.
- **Educational Models: Demonstrating basic neural learning principles.
2. Multilayer Feed-Forward Network
A multilayer feed-forward network consists of an input layer, one or more hidden layers and an output layer. The presence of hidden layers with nonlinear activation functions enables learning of complex, non-linear mappings. Data propagation occurs strictly from input to output.
- Includes hidden layers with nonlinear activations.
- Learns hierarchical feature representations.
- Uses backpropagation for learning.
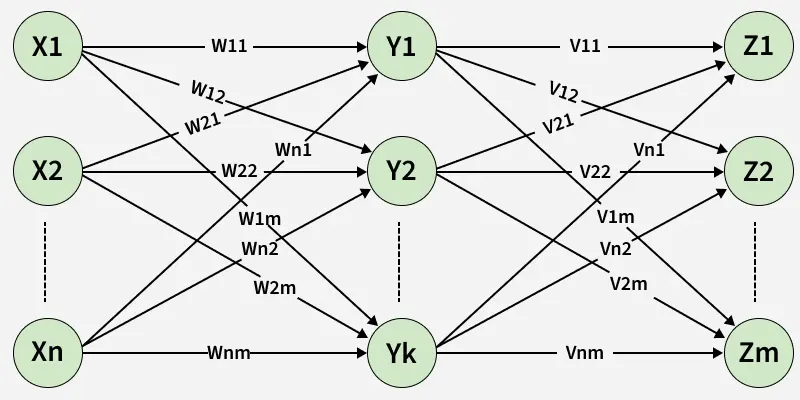
Multilayer Feed-Forward Network
Working
- Input data enters the input layer.
- Signals are forwarded to the first hidden layer.
- Each neuron computes a weighted sum and applies activation.
- Outputs flow sequentially through all hidden layers.
- The output layer generates the final prediction.
- Prediction error is computed.
- Error is propagated backward to update weights.
Use Cases
- **Image Classification: Identifying objects in images.
- **Medical Diagnosis: Disease prediction based on patient data.
- **Fraud Detection: Identifying abnormal financial behavior.
- **Pattern Recognition: Learning complex input-output mappings.
3. Single Node with Its Own Feedback
A single node with its own feedback is a simple recurrent structure where a neuron’s output is fed back as an input in the next time step. This feedback introduces a basic memory mechanism. The output depends on both current input and previous output.
- Simplest form of recurrence.
- Introduces temporal dependency.
- Maintains a single internal state.
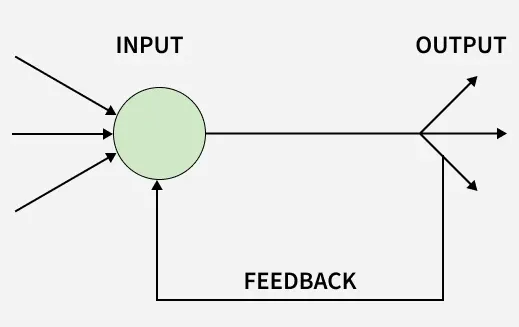
Single Node with Its Own Feedback
Working
- Input is combined with the previous output.
- The combined signal is weighted and summed.
- An activation function produces the current output.
- The output is stored as feedback.
- Feedback is used in the next time step’s computation.
Use Cases
- **Dynamic System Modeling: Representing systems that evolve over time.
- **Signal Filtering: Smoothing fluctuating signals.
- **Control Systems: Adaptive decision mechanisms.
- **Introductory Temporal Models: Learning basic time-dependent behavior.
4. Single-Layer Recurrent Network
A single-layer recurrent network contains one layer of neurons with feedback connections. These connections allow the network to maintain a hidden state across time steps. It is primarily used for modeling sequential and time-dependent data.
- Feedback connections create temporal memory.
- Processes data step-by-step in time.
- Hidden state stores past information.
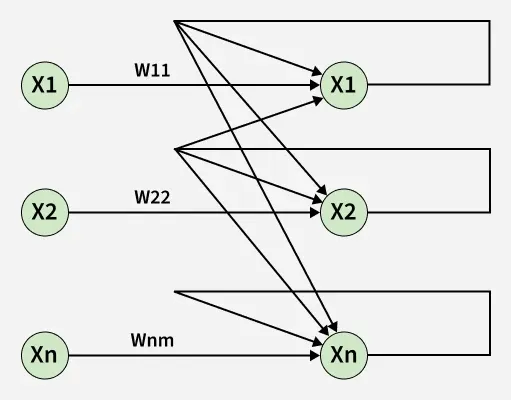
Single-Layer Recurrent Network
Working
- Input at the current time step is received.
- Previous hidden state is retrieved.
- Current input and past state are combined.
- Weighted sum and activation update the hidden state.
- Output is generated for the current time step.
- Hidden state is passed to the next time step.
Use Cases
- **Time-Series Prediction: Forecasting stock prices or weather.
- **Sequential Pattern Learning: Detecting temporal trends.
- **Speech Processing: Modeling speech signals.
- **Sensor Data Analysis: Processing streaming data.
5. Multilayer Recurrent Network
A multilayer recurrent network consists of multiple recurrent layers stacked together. Each layer processes temporal information while passing its hidden state to the next layer. This structure enables learning of complex and long-term temporal dependencies.
- Each layer maintains its own temporal state.
- Learns hierarchical sequence representations.
- Handles long and complex sequences effectively.
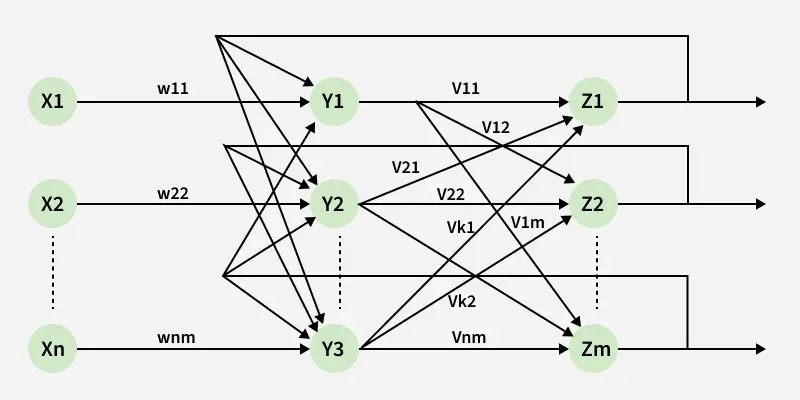
Multilayer Recurrent Network
Working
- Input sequence enters the first recurrent layer.
- Temporal patterns are learned at the first layer.
- Hidden states are passed to the next recurrent layer.
- Higher layers capture abstract temporal features.
- Final recurrent layer produces output.
- Errors are propagated backward through time.
- Weights are updated across all layers.
Use Cases
- **Natural Language Processing: Text generation and translation.
- **Speech Recognition: Converting speech to text.
- **Video Sequence Analysis: Understanding motion patterns.
- **Financial Forecasting: Long-term market trend analysis.
Comparison of Neural Network Architectures
Let's compare the various types of architectures:
| Aspect | Single-Layer Feed-Forward | Multilayer Feed-Forward | Single Node with Feedback | Single-Layer Recurrent | Multilayer Recurrent |
|---|---|---|---|---|---|
| Presence of Hidden Layers | No hidden layers | One or more hidden layers | No hidden layers | One recurrent layer | Multiple recurrent layers |
| Feedback Connections | Absent | Absent | Self-feedback only | Present within layer | Present across layers |
| Memory Capacity | No memory | No memory | Very limited memory | Short-term memory | Short- and long-term memory |
| Training Complexity | Very low | Moderate | Very low | High | Very high |
| Parameter Count | Minimal | Moderate to high | Minimal | Moderate | Very high |
| Parallel Processing Ability | Fully parallel | Fully parallel | Limited | Limited | Very limited |