Gradient Boosting in ML (original) (raw)
Last Updated : 3 Dec, 2025
Gradient Boosting is a **boosting algorithm and here each new model is trained to minimize the loss function such as mean squared error or cross-entropy of the previous model using gradient descent. In each iteration the algorithm computes the gradient of the loss function with respect to predictions and then trains a new weak model to predict this gradient. Predictions of the new model are then added to the ensemble (all models prediction) and the process is repeated until a stopping criterion is met.
**Shrinkage and Model Complexity
A key feature of Gradient Boosting is shrinkage which scales the contribution of each new model using **learning rate (denoted as \eta).
- **Smaller learning rates: mean the contribution of each tree is smaller which reduces the risk of overfitting but requires more trees to achieve the same performance.
- **Larger learning rates: mean each tree has a more significant impact but this can lead to overfitting.
There's a trade off between the learning rate and the number of estimators (trees) a smaller learning rate usually means more trees are required to achieve optimal performance.
Working of Gradient Boosting
**1. Sequential Learning Process
The ensemble consists of multiple trees each trained to correct the errors of the previous one. In the first iteration **Tree 1 is trained on the original data x and the true labels y. It makes predictions which are used to compute the errors.
**2. Residuals Calculation
In the second iteration **Tree 2 is trained using the feature matrix x and the errors from Tree 1 as labels. This means Tree 2 is trained to predict the errors of Tree 1. This process continues for all the trees in the ensemble. Each subsequent tree is trained to predict the errors of the previous tree.
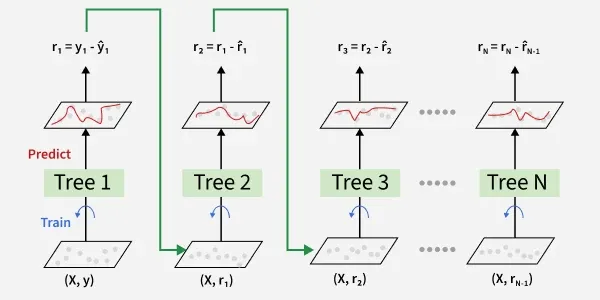
Gradient Boosted Trees
**3. Shrinkage
After each tree is trained its predictions are **shrunk by multiplying them with the learning rate η which ranges from 0 to 1. This prevents overfitting by ensuring each tree has a smaller impact on the final model.
Once all trees are trained predictions are made by summing the contributions of all the trees. The final prediction is given by the formula:
{\text y_{pred}} = y_1 + \eta \cdot r_1 + \eta \cdot r_2 + \cdots + \eta \cdot r_N
Where r_1, r_2, \dots, r_N are the errors predicted by each tree.
Difference between Adaboost and Gradient Boosting
Lets see difference between AdaBoost and gradient boosting which are as follows:
| Features | AdaBoost | Gradient Boosting |
|---|---|---|
| **Weight Update Strategy | Increase weights of misclassified sample so that the next learner focuses more on them. | Updates predictions by minimizing a loss function using the negative gradient |
| **Base learners | AdaBoost uses simple decision trees with one split known as the decision stumps of weak learners. | Gradient Boosting can use a wide range of base learners such as decision trees and linear models. |
| **Sensitivity to Noise | AdaBoost is more sensitive to noisy data and outliers due to aggressive weighting. | Gradient Boosting is less sensitive as it smooths updates using gradients. |
| **Optimization Technique | No explicit loss function i.e it focuses on classification error. | Explicitly minimizes a differentiable loss function. |
| **Boosting Mechanism | Learners are trained sequentially with sample reweighting. | Learners are trained sequentially with residual fitting (gradient descent). |
| **Interpretability | Easier to interpret due to simple weak learners. | Harder to interpret if complex models are used. |
| **Use case | Suitable for clean datasets with fewer outliers | Suitable for complex problems with varying loss function |
**Implementing Gradient Boosting for Classification and Regression
Here are two examples to demonstrate how Gradient Boosting works for both classification and regression. But before that let's understand gradient boosting parameters.
- **n_estimators: This specifies the number of trees (estimators) to be built. A higher value typically improves model performance but increases computation time.
- **learning_rate: This is the shrinkage parameter. It scales the contribution of each tree.
- **random_state: It ensures reproducibility of results. Setting a fixed value for random_state ensure that you get the same results every time you run the model.
- **max_features: This parameter limits the number of features each tree can use for splitting. It helps prevent overfitting by limiting the complexity of each tree and promoting diversity in the model.
Now we start building our models with Gradient Boosting.
**Example 1: Classification
We use Gradient Boosting Classifier to predict digits from Digits dataset.
- Import the necessary libraries
- Setting SEED for reproducibility
- Load the digit dataset and split it into train and test.
- Instantiate Gradient Boosting classifier and fit the model.
- Predict the test set and compute the accuracy score. Python `
from sklearn.ensemble import GradientBoostingClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.datasets import load_digits
SEED = 23
X, y = load_digits(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.25, random_state = SEED)
gbc = GradientBoostingClassifier(n_estimators=300, learning_rate=0.05, random_state=100, max_features=5 )
gbc.fit(train_X, train_y)
pred_y = gbc.predict(test_X)
acc = accuracy_score(test_y, pred_y) print("Gradient Boosting Classifier accuracy is : {:.2f}".format(acc))
`
**Output:
Gradient Boosting Classifier accuracy is : 0.98
**Example 2: Regression
We use Gradient Boosting Regressor on the Diabetes dataset to predict continuous values:
- Import the necessary libraries
- Setting SEED for reproducibility
- Load the diabetes dataset and split it into train and test.
- Instantiate Gradient Boosting Regressor and fit the model.
- Predict on the test set and compute RMSE. python `
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error from sklearn.datasets import load_diabetes
SEED = 23
X, y = load_diabetes(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.25, random_state = SEED)
gbr = GradientBoostingRegressor(loss='absolute_error', learning_rate=0.1, n_estimators=300, max_depth = 1, random_state = SEED, max_features = 5)
gbr.fit(train_X, train_y)
pred_y = gbr.predict(test_X)
test_rmse = mean_squared_error(test_y, pred_y) ** (1 / 2)
print('Root mean Square error: {:.2f}'.format(test_rmse))
`
**Output:
Root mean Square error: 56.39
Gradient Boosting is an effective and widely-used machine learning technique for both classification and regression problems. It builds models sequentially focusing on correcting errors made by previous models which leads to improved performance.