Multiclass classification using scikitlearn (original) (raw)
Multiclass classification using scikit-learn
Last Updated : 13 Aug, 2025
Multiclass classification is a supervised machine learning task in which each data instance is assigned to one class from three or more possible categories. In scikit-learn, implementing multiclass classification involves preparing the dataset, selecting the appropriate algorithm, training the model and evaluating its performance. Common multiclass classifiers include Decision Tree, Support Vector Machine (SVM), K-Nearest Neighbors (KNN) and Naive Bayes, each offering a different approach for handling multiple class labels within the data. Real-world examples include digit recognition, species identification and product categorization.
- **Features: Measurable properties of instances (e.g., flower petal length).
- **Labels/Classes: Discrete categories (e.g., 'setosa', 'versicolor', 'virginica' in the Iris dataset).
Step-by-Step Implementation
Let's see the step-by-step implementation of Multiclass Classification along with various classifiers,
Step 1: Import Libraries
We will import the required libraries,
- **sklearn.datasets: Provides standard datasets (like iris) useful for testing and practicing ML methods.
- **sklearn.model_selection.train_test_split: This function splits arrays or matrices into random train and test subsets, enabling fair evaluation of models.
- **sklearn.metrics.accuracy_score, confusion_matrix: Tools for evaluating the correctness of model predictions; accuracy measures percent correct, confusion matrix details classification mistakes.
- **matplotlib.pyplot: A plotting library for creating static, interactive and animated visualizations in Python.
- **seaborn: A high-level data visualization library built on matplotlib; it helps produce visually appealing statistical graphics (like heatmaps). Python `
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns
`
Step 2: Load and Explore the Dataset
The Iris dataset is a famous collection of 150 flower samples, representing three Iris species, setosa, versicolor and virginica. Each sample has four numeric features: sepal length, sepal width, petal length and petal width.
- **iris.data is a 2D NumPy array of shape (150, 4), where each row represents a single flower’s measured features.
- **iris.target is a 1D array of length 150, where each entry is an integer (0, 1 or 2) that denotes the species label for the corresponding row in iris.data.
Step 3: Split the Data
We will split the data for training and testing,
- train_test_split separates the feature (X) and label (y) arrays into training and testing sets. Here, 70% of the data is used to train the models (X_train, y_train) and 30% is used to evaluate them (X_test, y_test).
- Setting random_state ensures we always get the same split, allowing reproducibility. Python `
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
`
Step 4: Model Training and Visualization
**1. Decision Tree Classifier: Decision Tree Classifier is a model that predicts class labels by learning simple decision rules arranged in a tree structure, where each node makes a decision based on a feature until a class label is assigned at the leaf.
- Instantiates the classifier object, setting a limit of 2 for tree depth.
- .fit(X_train, y_train) trains the model using the training data.
- .predict(X_test) generates predicted labels for the test data.
- accuracy_score(y_test, dtree_preds) computes how many test samples were correctly classified.
- confusion_matrix(y_test, dtree_preds) gives a table indicating, for each actual class, how many times the model predicted each possible class.
- The seaborn heatmap visualizes which classes the model predicts well or struggles with. Python `
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier(max_depth=2, random_state=0) dtree.fit(X_train, y_train) dtree_preds = dtree.predict(X_test) dtree_acc = accuracy_score(y_test, dtree_preds) dtree_cm = confusion_matrix(y_test, dtree_preds)
print("Decision Tree Accuracy:", dtree_acc)
plt.figure(figsize=(4, 3)) sns.heatmap(dtree_cm, annot=True, cmap="Blues", fmt="d") plt.title("Decision Tree Confusion Matrix") plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()
`
**Output:
Decision Tree Accuracy: 0.9111111111111111
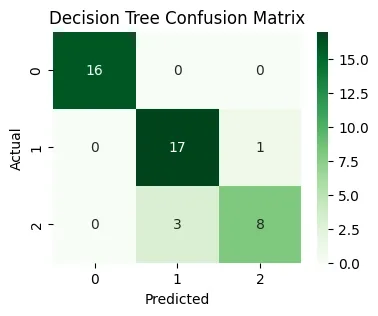
Decision Tree Classifier Confusion Matrix
**2. Support Vector Machine(SVM) Classifier: Support Vector Machine Classifier is a model that separates data into classes by finding the optimal hyperplane that maximizes the margin between different class groups in the feature space.
- Creates a linear SVC (Support Vector Classifier) object.
- Fits the model with training data.
- Predicts test set labels.
- Calculates accuracy and confusion matrix.
- Visualizes the confusion matrix, showing per-class predictions. Python `
from sklearn.svm import SVC
svm = SVC(kernel='linear', C=1, random_state=0) svm.fit(X_train, y_train) svm_preds = svm.predict(X_test) svm_acc = accuracy_score(y_test, svm_preds) svm_cm = confusion_matrix(y_test, svm_preds)
print("SVM Accuracy:", svm_acc)
plt.figure(figsize=(4, 3)) sns.heatmap(svm_cm, annot=True, cmap="Blues", fmt="d") plt.title("SVM Confusion Matrix") plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()
`
**Output:
SVM Accuracy: 0.9777777777777777

SVM Confusion Matrix
**3. K-Nearest Neighbors(KNN) Classifiers: k-Nearest Neighbors Classifier is a model that classifies a data point by looking at the majority class among its k-nearest neighbors, based on distance in feature space.
- Sets up a KNN classifier to consider 7 neighbors.
- Models the training data (essentially, stores it).
- Predicts the labels by 'voting' among the nearest neighbors.
- Derives accuracy and confusion statistics.
- Plots the confusion matrix to visualize strengths and errors in class assignment. Python `
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=7) knn.fit(X_train, y_train) knn_preds = knn.predict(X_test) knn_acc = accuracy_score(y_test, knn_preds) knn_cm = confusion_matrix(y_test, knn_preds)
print("KNN Accuracy:", knn_acc)
plt.figure(figsize=(4, 3)) sns.heatmap(knn_cm, annot=True, cmap="Blues", fmt="d") plt.title("KNN Confusion Matrix") plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()
`
**Output:
KNN Accuracy: 0.9777777777777777
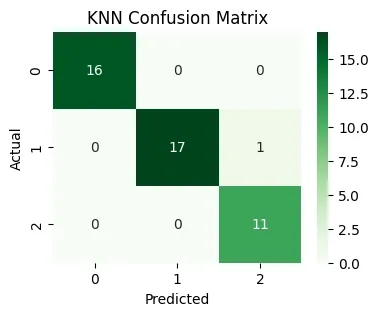
KNN Confusion Matrix
**4. Naive Bayes Classifier: Naive Bayes Classifier is a probabilistic model based on Bayes' theorem, which assumes that features are independent given the class and predicts the most probable class for new data.
- Instantiates a Gaussian Naive Bayes classifier.
- Fits the model to the training data, calculating class-conditional mean and variance for each feature.
- Predicts class labels for test samples based on probability.
- Computes overall accuracy and structured confusion data.
- Plots the confusion matrix, providing an at-a-glance assessment of classification quality for each true class. Python `
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB() nb.fit(X_train, y_train) nb_preds = nb.predict(X_test) nb_acc = accuracy_score(y_test, nb_preds) nb_cm = confusion_matrix(y_test, nb_preds)
print("Naive Bayes Accuracy:", nb_acc)
plt.figure(figsize=(4, 3)) sns.heatmap(nb_cm, annot=True, cmap="Blues", fmt="d") plt.title("Naive Bayes Confusion Matrix") plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()
`
**Output:
Naive Bayes Accuracy: 1.0
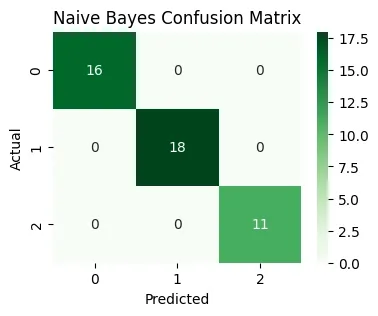
Naive Bayes Confusion Matrix