One Hot Encoding vs Label Encoding (original) (raw)
Last Updated : 22 Jan, 2026
Machine learning models require numerical input to make predictions but real-world datasets often contain categorical data such as countries, colours or severity levels. Encoding techniques convert these categorical variables into numerical formats that models can interpret effectively.
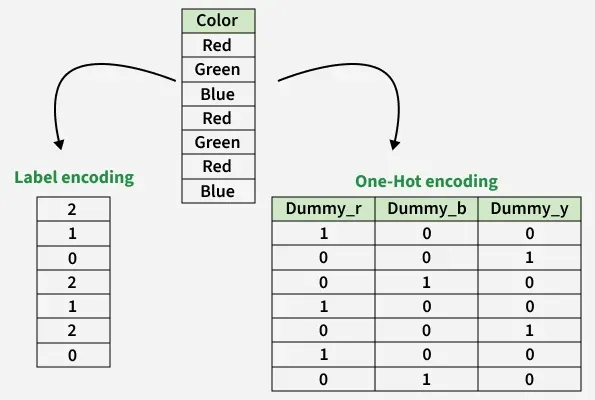
Label Encoding vs One-Hot Encoding
Understanding One-Hot Encoding
One-Hot Encoding converts each category of a categorical variable into a new binary column. Each column represents a unique category where a value of 1 indicates the presence of that category and 0 indicates its absence.
Features of One-Hot Encoding
- Best suited for nominal data where categories have no inherent order (e.g., colors, countries).
- Creates multiple binary features increasing the dimensionality of the dataset.
- Easy to interpret as each column directly represents a category.
- Works well with algorithms that do not assume ordinality such as logistic regression, neural networks and KNN.
- May lead to sparse data and higher memory usage if there are many unique categories.
When to use
- The categorical variable is nominal.
- The number of unique categories is relatively small.
- The algorithm does not assume an ordinal relationship.
- Avoid using it with high-cardinality features to prevent the curse of dimensionality.
Implementation of One-Hot Encoding
Here we do One-Hot Encoding using Pandas. It converts the categorical Country column into separate binary columns, where 1 indicates the presence of a country and 0 indicates its absence
Python `
import pandas as pd
countries = ['USA', 'Canada', 'India', 'USA', 'Canada'] df = pd.DataFrame({'Country': countries})
one_hot = pd.get_dummies(df['Country'], dtype=int) print(one_hot)
`
**Output:
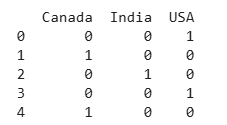
One-Hot Encoding
Understanding Label Encoding
Label Encoding assigns each category of a categorical variable a unique integer value. This converts the categorical column into a single numerical feature.
Features of Label Encoding
- Best suited for ordinal data, where categories have a natural order (e.g. "Low", "Medium", "High").
- Creates a single column keeping the feature space compact.
- Easier for tree-based models like Decision Trees and Random Forests which can handle ordinal relationships effectively.
- Can be misinterpreted by models that assume numeric relationships between categories where none exists.
- More memory-efficient than One-Hot Encoding.
When to use Label Encoding
- The categorical variable is ordinal.
- Preserving the order of categories is important.
- Using tree-based algorithms like Decision Trees, Random Forests or XGBoost.
- Memory efficiency is a priority.
Implementation of Label Encoding
Here we implement Label Encoding using scikit-learn. It converts the categorical Severity column into numeric values, assigning a unique integer to each category while preserving the ordinal relationship.
Python `
import pandas as pd from sklearn.preprocessing import LabelEncoder
severity = ['Low', 'Medium', 'High', 'Medium', 'Low'] df = pd.DataFrame({'Severity': severity})
label_encoder = LabelEncoder() df['Severity_encoded'] = label_encoder.fit_transform(df['Severity']) print(df)
`
**Output:

Label Encoding
One-Hot vs Label Encoding
Here we compare One-Hot Encoding with Label Encoding:
| **Aspect | **One Hot Encoding | **Label Encoding |
|---|---|---|
| **Nature of Data | Best for nominal data (no order) | Best for ordinal data (has a natural order) |
| **Number of Features Created | Creates multiple binary features per category | Creates a single integer-valued feature |
| **Model Interpretation | Easy to interpret, each column corresponds to a category | Harder to interpret, categories are replaced by integers |
| **Impact on Machine Learning | Suitable for algorithms that don't assume ordinality | Suitable for tree-based models that handle ordinal data |
| **Dimensionality | Increases dimensionality, leading to sparse data | Does not increase dimensionality, more compact |
| **Handling Unseen Categories | Can raise errors unless handled explicitly | Can assign arbitrary integers to unseen categories |
| **Memory and Computational Efficiency | Less memory efficient, increases computation | More memory efficient and computationally cheaper |