Recommendation System in Python (original) (raw)
Last Updated : 22 Sep, 2025
A recommendation system is an intelligent algorithm designed to suggest items such as movies, products, music or services based on a user’s past behavior, preferences or similarities with other users. These systems help users discover relevant content in vast environments making them crucial for industries like e-commerce, streaming and food delivery.
Types of Recommendation Systems
Recommendation systems can broadly be divided into two categories:
**1. Content-Based Filtering: Suggests items similar to those a user has already liked.
- **How it works: Uses item features like movie genre, director or actors and matches them with a user’s profile.
- **Example: If a user enjoys Inception, the system may recommend Interstellar because both share genres and the same director.
**2. Collaborative Filtering: Recommends items by analyzing the behavior of many users.
- **How it works: Assumes that users with similar tastes will like similar items.
- **Example: If two users often rate the same movies highly, one user may receive recommendations based on the other’s preferences.
Building a Movie Recommendation System in Python
Let's build a movie recommendation system:
The dataset can be downloaded from here.
Step 1: Import Libraries
We will import the required libraries such as numpy, pandas, sklearn, matplotlib and seaborn.
Python `
import numpy as np import pandas as pd import sklearn import matplotlib.pyplot as plt import seaborn as sns
`
Step 2: Loading Dataset
We will load our dataset,
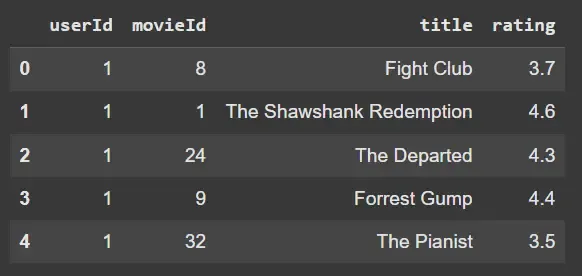
- **Columns: userId, movieId, title, rating.
- **head(): shows first 5 rows for a quick check. Python `
ratings = pd.read_csv("ratings.csv") ratings.head()
`
**Output:
Dataset
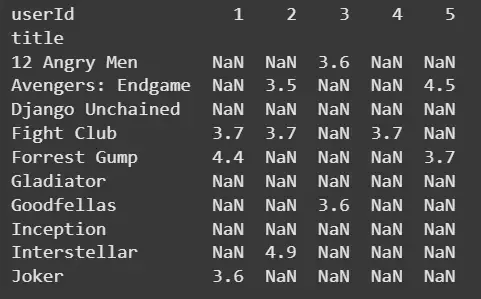
Step 3: Create the User-Item Matrix
We create the user-item sparse matrix,
- **user_mapper: maps user IDs: matrix index.
- **movie_mapper: maps movie IDs: matrix index.
- **movie_inv_mapper: reverse lookup (index: movieId).
- **Rows = Movies
- **Columns = Users
- **Values = Ratings Python `
def create_matrix(df): user_mapper = {uid: i for i, uid in enumerate(df['userId'].unique())} movie_mapper = {mid: i for i, mid in enumerate(df['movieId'].unique())} movie_inv_mapper = {i: mid for mid, i in movie_mapper.items()}
user_index = df['userId'].map(user_mapper)
movie_index = df['movieId'].map(movie_mapper)
X = csr_matrix((df["rating"], (movie_index, user_index)),
shape=(len(movie_mapper), len(user_mapper)))
return X, movie_mapper, movie_inv_mapperX, movie_mapper, movie_inv_mapper = create_matrix(ratings)
user_item_matrix = ratings.pivot_table( index="title", columns="userId", values="rating") print(user_item_matrix.iloc[:10, :5])
`
**Output:
Matrix
Step 4: Define the Recommendation Function
We need to define the function which will be used for recommendation,
- **movie_id: get ID of the given movie.
- **movie_idx: find its row index in matrix.
- **NearestNeighbors: finds k nearest movies by cosine similarity. Python `
def recommend_similar(movie_title, df, X, movie_mapper, movie_inv_mapper, k=5): movie_id = df[df['title'] == movie_title]['movieId'].iloc[0] movie_idx = movie_mapper[movie_id] movie_vec = X[movie_idx]
model = NearestNeighbors(metric='cosine', algorithm='brute')
model.fit(X)
distances, indices = model.kneighbors(movie_vec, n_neighbors=k + 1)
neighbor_ids = [movie_inv_mapper[i] for i in indices.flatten()[1:]]
recommendations = df[df['movieId'].isin(neighbor_ids)]['title'].unique()
print(f"\nBecause you liked **{movie_title}**, you might also enjoy:")
for rec in recommendations:
print(f"- {rec}")`
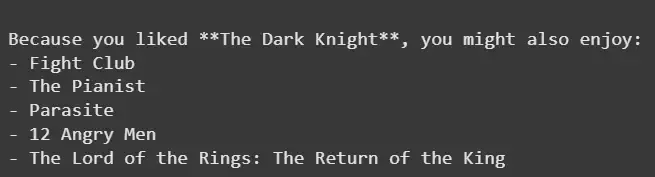
Step 5: Test and Get Result
We will test our system:
Python `
recommend_similar("The Dark Knight", ratings, X, movie_mapper, movie_inv_mapper, k=5)
`
**Output:
Result
Applications
Recommendation systems have various use cases:
- **E-commerce (Amazon, Flipkart): Suggest products based on browsing/purchase history.
- **Streaming platforms (Netflix, Spotify, YouTube): Recommend movies, music or videos tailored to user taste.
- **Social media (Instagram, Twitter/X): Personalized content feed and friend/page suggestions.
- **Online learning (Coursera, Udemy): Suggest relevant courses based on interests and progress.
- **Healthcare: Personalized treatment suggestions and drug recommendations.
Advantages
- **Personalization: Delivers tailored experiences for each user.
- **Increased engagement: Keeps users on platforms longer which helps in generating revenue and giving good expereience to user.
- **Boosts sales & revenue: Drives cross-selling and upselling of products.
- **Helps discovery: Users find new content/items they wouldn’t search for.
- **Competitive edge: Differentiates businesses with smarter user experiences.
Limitations
- **Data sparsity: Many items remain unrated, reducing accuracy.
- **Bias & filter bubble: Over-personalization limits exposure to diverse content.
- **Scalability issues: Handling millions of users/items requires huge computation.
- **Privacy concerns: Collecting and analyzing personal data raises ethical risks.