Reproducibility in Machine Learning (original) (raw)
Last Updated : 13 Apr, 2026
Reproducibility in machine learning means being able to run the same experiment again and get the same results. For ML this means using the same code, data and settings and making sure the model performs the same way each time. Reproducibility helps in debugging, comparing models, sharing work with others and deploying reliable systems in the real world. When experiments are reproducible teams can trust each other’s work, improve on existing models, compare results fairly and avoid unexpected behavior during deployment.
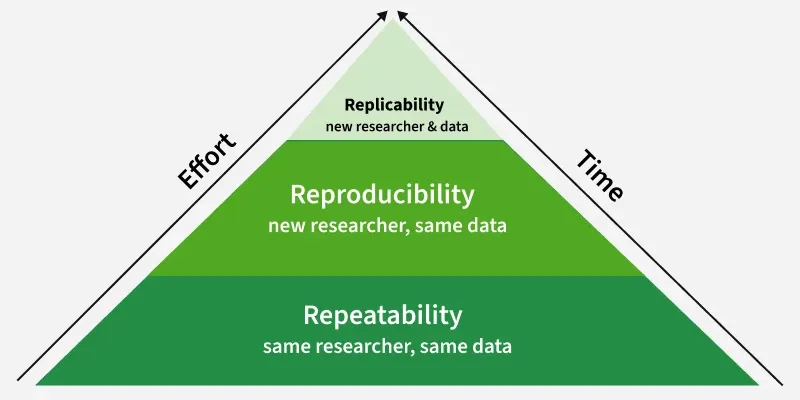
Reproducibility in Machine Learning
Key Features
- **Consistent Results: Reproducibility ensures that running the same code with the same data always leads to the same output. This builds confidence in the results and avoids unexpected behavior in production.
- **Experiment Tracking: Tracking tools log model settings, training time, hyperparameters and performance metrics. This helps compare models, understand what worked and revisit past experiments easily.
- **Data and Model Versioning: Every change to the dataset or trained model is tracked and saved. This ensures that even if data or models are updated later, previous results can still be reproduced.
- **Environment Control: Reproducibility depends on consistent environments same Python version, same libraries, same hardware. Tools like Docker or Conda help maintain this consistency.
Steps to achieve Reproducibility
Step 1: Set Random Seeds
Set seeds for all libraries that use randomness to make results consistent.
Python `
import random import numpy as np import torch
random.seed(42) np.random.seed(42) torch.manual_seed(42) torch.cuda.manual_seed_all(42)
`
Step 2: Fix Library Versions
Use a requirements.txt or environment.yml file to pin the versions of libraries.
Python `
pip freeze > requirements.txt
`
Step 3: Use Deterministic Algorithms
Many deep learning libraries have non-deterministic operations (especially on GPU). Use deterministic versions when available.
Python `
torch.use_deterministic_algorithms(True)
`
Step 4: Log Everything
Track model configs, parameters, training logs, metrics etc. using tools like:
- Weights and Biases (wandb)
- MLflow
- TensorBoard
Step 5: Save and Version Data
Ensure your training, validation and test data is fixed and not randomly split every time. Save preprocessed datasets and use version control for datasets if they change over time.
Step 6: Use Virtual Environments or Docker
Use virtualenv, conda or Docker to isolate your environment. Docker ensures your code runs the same way regardless of machine.
Step 7: Track Code with Version Control (Git)
Use Git to version control your codebase. Always commit the exact version used to train a model.
Step 8: Save and Reload Models Properly
Save model weights, optimizer states and configurations.
Python `
torch.save(model.state_dict(), 'model.pth')
`
Step 9: Document the Pipeline
Clearly document preprocessing steps, training configs and dependencies. Anyone should be able to follow your process from data to model.
1. Code and Version Control
- **Git: Track changes in code and collaborate with teams.
- **GitHub / GitLab / Bitbucket: Host code repositories and manage issues, CI/CD.
2. Data and Model Versioning
- **DVC (Data Version Control): Tracks datasets, models and experiments using Git like commands.
- **Pachyderm: Data lineage and versioning with built in pipelines.
- **LakeFS: Git like branching/versioning on data lakes.
3. Environment and Dependency Management
- **Conda / Pip + Virtualenv: Manage Python environments.
- **Docker: Package the entire project into containers for consistent environments across systems.
- **Poetry / Pipenv: Manage Python dependencies with lock files for reproducibility.
4. Experiment Tracking
- **MLflow: Logs experiments, parameters, metrics and artifacts.
- **Weights and Biases: Tracks experiments, hyperparameters and visualizations.
- **Comet.ml: Experiment logging with collaboration tools.
- **Sacred + Omniboard: Lightweight experiment tracking.
5. Pipeline Orchestration
- **Kedro: Structure ML pipelines with modularity and reproducibility.
- **Kubeflow: Scalable ML pipelines with Kubernetes.
- **Airflow: Schedule and monitor workflows (with ML extensions).
- **Metaflow: Netflix's framework for pipeline management and reproducibility.
6. Configuration Management
- **Hydra: Manage complex configuration files, overrides and experiments.
- **Gin config: Lightweight configuration tool for ML experiments.
Advantages
- **Easier Debugging: Helps identify errors by reproducing exact conditions.
- **Reliable Results: Ensures consistent outputs when experiments are repeated.
- **Better Collaboration: Enables teams to share and build on each other’s work.
- **Fair Comparison: Allows accurate comparison between different models and approaches.
- **Production Stability: Reduces unexpected behavior during deployment.
Limitations
- **Environment Differences: Variations in libraries, hardware or OS can affect results.
- **Randomness in Training: Some operations introduce non-deterministic behavior.
- **Data Management Issues: Changing or untracked datasets make reproduction difficult.
- **High Effort: Requires proper tracking of code, data, and configurations.
- **Scalability Concerns: Large models and datasets are harder to reproduce efficiently.