Text to text Transfer Transformer (T5) in Data Augmentation (original) (raw)
Last Updated : 31 Jul, 2025
Data augmentation in NLP is a technique used to create additional training data by slightly modifying existing text. This helps machine learning models perform better, especially when the original dataset is small. Whether we're building a model for text classification, summarization or question answering, data augmentation can make a big difference.
Some common techniques used for data augmentation in NLP include:
- Word Embeddings
- BERT-based methods
- Back Translation
- Text-to-Text Transfer Transformer (T5)
- Ensemble Approaches
In this article, we'll focus on how the **Text-to-Text Transfer Transformer (T5) can be used to generate new training data and improve NLP model performance.
Text to Text Transfer Transformer
Text-to-Text Transfer Transformer (T5) is a large transformer model trained on the Colossal Clean Crawled Corpus (C4). It was released as a pre-trained model capable of handling various NLP tasks such as translation, summarization, question answering and classification.
T5 treats every NLP task as a text-to-text problem. This means both the input and output are plain text, regardless of the task. For example:
**Example 1: For English-to-German translation, the input could be: "translate English to German: That is a book." then the output would be the translated sentence in German.
**Example 2: For sentiment analysis, the input might be: "sentiment analysis: I love this product." and the output would be: _"positive".
T5 allows training on multiple tasks by using different prefixes in the input to indicate the task type. This approach enables a single model to handle diverse NLP tasks effectively. It has shown strong performance across many benchmarks and is widely used for generating synthetic data in data augmentation workflows.
**How to use T5 for Data Augmentation
There are multiple ways to use the T5 (Text-to-Text Transfer Transformer) model for data augmentation in NLP tasks.
1. Using T5 Directly
Similar to back translation, T5 can be used without additional training by leveraging its pre-trained summarization capabilities. In this approach:
- The input is given in the format: "summarize: "
- T5 generates an abstractive summary, often rephrasing or using new words.
- This is useful for long-text NLP tasks like document classification or summarization.
- However, for short texts, the quality of augmented data may not be very effective.
2. Fine-Tuning T5 for Custom Data Augmentation
T5 can also be fine-tuned on specific tasks to generate high-quality synthetic data. Two effective strategies are:
1. Masked Span Prediction
- T5 can be fine-tuned similarly to BERT for masked language modeling.
- **Input format: "predict mask: The [MASK] barked at the stranger."
- **Output: "The dog barked at the stranger."
- You can mask multiple words (spans) to generate more diverse sentence structures.
- This helps produce augmented text with structural variations, mimicking BERT-style augmentation.

Fine Tuning Data on Masked word Prediction Task
2. Paraphrase Generation
- T5 can be fine-tuned to create paraphrases that retain meaning but vary in structure and wording.
- The PAWS dataset is commonly used for this task.
- Training involves formatting input as:
"generate paraphrase: <sentence>"and output as its paraphrase. - The model can generate multiple variations, helping expand and diversify NLP datasets.

Fine Tuning T5 for Paraphrase Generation using PAWS Dataset
Model Variants and Considerations
T5 is available in multiple sizes:
T5-Small(60M parameters)T5-Base(220M)T5-Large(770M)T5-3B(3 billion)T5-11B(11 billion)
Larger models tend to produce better results but require more computational resources and training time. However, this is typically a one-time effort and the resulting model can be reused across various NLP tasks for effective data augmentation.
Implementation of Data Augmentation
1. Installation and Imports
- Installs and imports essential libraries like transformers, pytorch and pandas
- Sets up the T5 model for usage Python `
!pip install transformers torch datasets
import pandas as pd import numpy as np import torch from transformers import T5Tokenizer, T5ForConditionalGeneration
`
2. Setting Device for Computation
Automatically use GPU if available, otherwise fall back to CPU
Python `
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")
`
**Output:
Using device: cpu
3. Loading T5 Paraphrasing Model
- Loads a pretrained T5 paraphrasing model and tokenizer.
- Formats input with
"paraphrase:"prompt. - Encodes input and generates multiple diverse outputs using sampling.
- Decodes and returns unique paraphrased sentences. Python `
class T5Paraphraser: def init(self, model_name="ramsrigouthamg/t5_paraphraser"): self.tokenizer = T5Tokenizer.from_pretrained(model_name) self.model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
def paraphrase(self, text, num_return_sequences=3, max_length=128):
input_text = f"paraphrase: {text} </s>"
inputs = self.tokenizer.encode(input_text, return_tensors="pt", max_length=max_length, truncation=True).to(device)
outputs = self.model.generate(
inputs, max_length=max_length, num_return_sequences=num_return_sequences,
do_sample=True, top_k=50, top_p=0.95, temperature=0.8
)
return list(set(self.tokenizer.decode(output, skip_special_tokens=True) for output in outputs))`
4. Initialising Model
- Instantiate the model class
- Generate paraphrased variations of a few example sentences Python `
paraphraser = T5Paraphraser()
sample_sentences = [ "Python is a powerful language.", "Deep learning requires large datasets.", "Artificial intelligence is evolving rapidly." ]
for text in sample_sentences: print(f"\nOriginal: {text}") for i, p in enumerate(paraphraser.paraphrase(text), 1): print(f"Paraphrase {i}: {p}")
`
**Output:
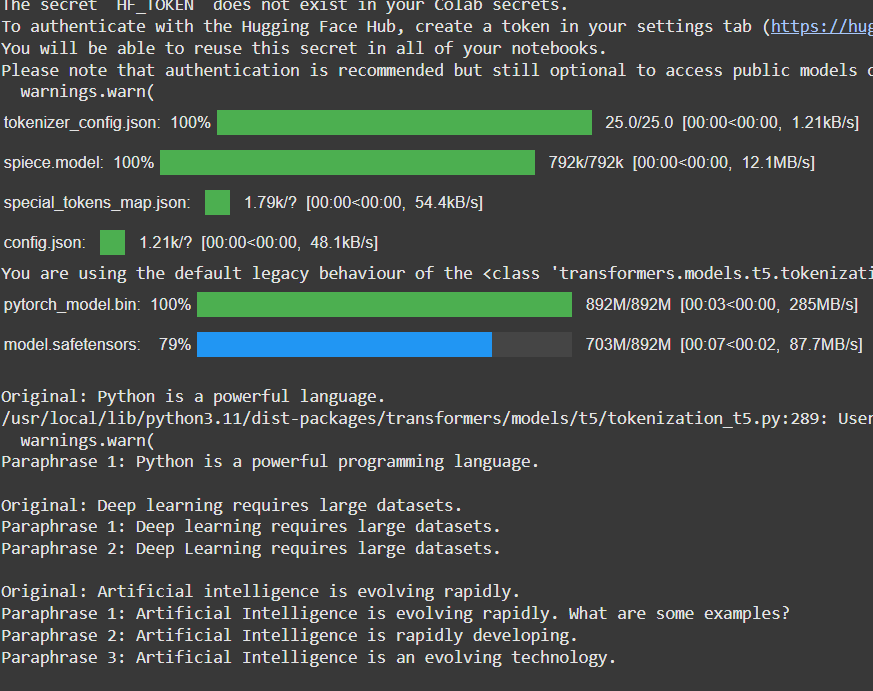
T5 Paraphraser
5. Augmented a Text Classification Dataset
- Created a mock dataset
- Used paraphrasing to add more examples for each label, increasing dataset size and diversity Python `
def get_sample_data(): return pd.DataFrame({ 'text': [ "Great product quality", "Fast delivery", "Excellent service", "Poor design", "Terrible support" ], 'label': ['positive', 'positive', 'positive', 'negative', 'negative'] })
def augment_dataset(df, text_col='text', label_col='label', ratio=0.5): augmented = []
for label in df[label_col].unique():
samples = df[df[label_col] == label].sample(frac=ratio)
for text in samples[text_col]:
for p in paraphraser.paraphrase(text, num_return_sequences=2):
augmented.append({text_col: p, label_col: label, 'source': 'augmented'})
df['source'] = 'original'
return pd.concat([df, pd.DataFrame(augmented)], ignore_index=True)df = get_sample_data() aug_df = augment_dataset(df)
print("\nAugmented Dataset:") print(aug_df.head())
`
**Output:

Augmentation on sample dataset
6. Batch Processing for Large Datasets
- Efficiently paraphrase large numbers of inputs in small batches
- Prevent memory overload during generation Python `
def batch_paraphrase(texts, batch_size=5, num_return=1): results = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
for text in batch:
results.append(text)
results.extend(paraphraser.paraphrase(text, num_return_sequences=num_return))
return resultsaugmented_batch = batch_paraphrase(sample_sentences, batch_size=2, num_return=2) print("\nBatch Paraphrased Output:") for text in augmented_batch: print(text)
`
**Output:

Batch paraphrased output
7. Analysis of Augmented Data
Show proportion of original vs. augmented data
Python `
def print_stats(df): print("\nSample Counts by Source:") print(df['source'].value_counts(normalize=True).apply(lambda x: f"{x*100:.1f}%"))
print_stats(aug_df)
`
**Output:
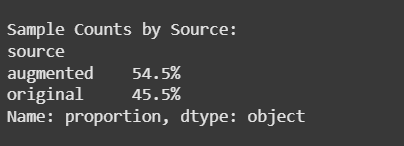
Augmentation and Original proportion
Here we can see that our model is working fine.