MultiHead Attention Mechanism (original) (raw)
Multi-Head Attention Mechanism
Last Updated : 4 Dec, 2025
The multi-head attention mechanism is a key component of the Transformer architecture, introduced in the seminal paper "Attention Is All You Need" by Vaswani et al. in 2017. It plays a crucial role in enhancing the ability of models to focus on different parts of an input sequence simultaneously, making it particularly effective for tasks such as machine translation, text generation and more.
**Understanding Attention Mechanism
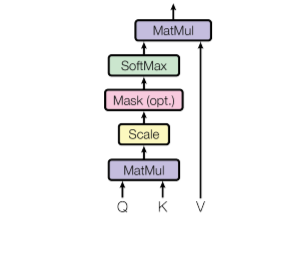
Before diving into multi-head attention, let’s first understand the standard **self-attention mechanism, also known as scaled dot-product attention.
Given a set of input vectors, self-attention computes attention scores to determine how much focus each element in the sequence should have on the others. This is done using three key matrices:
- **Query (Q): Represents the current word's relationship with others.
- **Key (K): Represents the words that are being compared against.
- **Value (V): Contains the actual word representations.
Self Attention
The self-attention is computed as:
\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V
What is Multi-Head Attention?
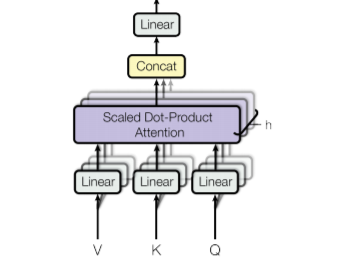
Multi-head attention extends self-attention by splitting the input into multiple heads, enabling the model to capture diverse relationships and patterns.
Instead of using a single set of Q, K, V matrices, the input embeddings are projected into multiple sets (heads), each with its own Q, K, V:
- **Linear Transformation: The input X is projected into multiple smaller-dimensional subspaces using different weight matrices.
Q_i = XW_i^Q, \quad K_i = XW_i^K, \quad V_i = XW_i^V
where i denotes the head index. - **Independent Attention Computation: Each head independently computes its own self-attention using the scaled dot-product formula.
- **Concatenation: The outputs from all heads are concatenated.
- **Final Linear Transformation: A final weight matrix is applied to transform the concatenated output into the desired dimension.
Multi-Head Attention
Mathematically, multi-head attention is expressed as:
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h) W^O
where:
\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
W^O is a final weight matrix to project the concatenated output back into the model’s required dimensions.
**Why Use Multiple Attention Heads?
Multi-head attention provides several advantages:
- **Captures different relationships: Different heads attend to different aspects of the input.
- **Improves learning efficiency: By operating in parallel, multiple heads allow for better learning of dependencies.
- **Enhances robustness: The model doesn’t rely on a single attention pattern, reducing overfitting.
**Multi-Head Attention in Transformers
Multi-head attention is used in several places within a Transformer model:
**1. Encoder Self-Attention: This allows the encoder to learn contextual relationships within the input sequence. Each word (or token) in the input attends to every other word, helping the model to understand dependencies regardless of their distance in the sequence.

Encoder Self-Attention
**2. Decoder Self-Attention: In the decoder, self-attention ensures that each position in the output sequence can attend only to previous positions (with a masking mechanism), preventing the decoder from “seeing” future tokens during training. This helps in generating sequences in an autoregressive manner while focusing on relevant parts of what has been generated so far.

Decoder Self Attention
**3. Encoder-Decoder Attention: This layer lets the decoder attend over the encoder's output. It helps the decoder to align and focus on the appropriate input tokens when generating each output token, enabling sequence-to-sequence tasks like translation.

Encoder-Decoder Attention
Implementing Multi-head Attention using PyTorch
Step 1: Imports
Importing all necessary libraries for tensor manipulations and neural network building.
Python `
import torch import torch.nn as nn import torch.nn.functional as F import math
`
Step 2: Scaled Dot-Product Attention Function
This is the core of self-attention:
\mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left( \frac{Q K^\top}{\sqrt{d_k}} \right) V
- Q, K, V are queries, keys, values derived from the same source in self-attention.
- It results in values i.e the weighted sum for each position and head.
- Softmax ensures the attention weights sum to 1.
- If masking, irrelevant positions (like future tokens or padding) get large negative values in logits, so after softmax attention there is 0. Python `
def scaled_dot_product(q, k, v, mask=None): d_k = q.size()[-1] # (batch, heads, seq_len, head_dim) @ (batch, heads, head_dim, seq_len) --> (batch, heads, seq_len, seq_len) scaled = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k) if mask is not None: scaled += mask attention = F.softmax(scaled, dim=-1) # (batch, heads, seq_len, seq_len) @ (batch, heads, seq_len, head_dim) --> (batch, heads, seq_len, head_dim) values = torch.matmul(attention, v) return values, attention
`
Step 3: Multi-Head Attention Class
Every step mimics the original Transformer:
- Project to QKV,
- Reshape for multiple heads,
- Split into Q, K, V,
- Compute attention,
- Concatenate heads,
- Linear output. Python `
class MultiheadAttention(nn.Module): def init(self, input_dim, d_model, num_heads): super().init() self.input_dim = input_dim # Input embedding size self.d_model = d_model # Model embedding size (output of self-attention) self.num_heads = num_heads # Number of parallel attention heads self.head_dim = d_model // num_heads # Dimensionality per head
# For efficiency, compute Q, K, V for all heads at once with a single linear layer
self.qkv_layer = nn.Linear(input_dim, 3 * d_model)
# Final projection, combines all heads' outputs
self.linear_layer = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, sequence_length, input_dim = x.size()
print(f"x.size(): {x.size()}") # Input shape
# Step 1: Project x into concatenated q, k, v for ALL heads at once
qkv = self.qkv_layer(x)
print(f"qkv.size(): {qkv.size()}") # Shape: (batch, seq_len, 3 * d_model)
# Step 2: reshape into (batch, seq_len, num_heads, 3 * head_dim)
qkv = qkv.reshape(batch_size, sequence_length, self.num_heads, 3 * self.head_dim)
print(f"qkv.size(): {qkv.size()}")
# Step 3: Rearrange to (batch, num_heads, seq_len, 3 * head_dim)
qkv = qkv.permute(0, 2, 1, 3)
print(f"qkv.size(): {qkv.size()}")
# Step 4: Split the last dimension into q, k, v (each get last dimension of head_dim)
q, k, v = qkv.chunk(3, dim=-1) # Each: (batch, num_heads, seq_len, head_dim)
print(f"q size: {q.size()}, k size: {k.size()}, v size: {v.size()}")
# Step 5: Apply scaled dot product attention to get outputs (contextualized values) and attention weights
values, attention = scaled_dot_product(q, k, v, mask)
print(f"values.size(): {values.size()}, attention.size: {attention.size()}")
# Step 6: Merge the heads (permute before reshape)
values = values.permute(0, 2, 1, 3) # (batch, seq_len, heads, head_dim)
values = values.reshape(batch_size, sequence_length, self.num_heads * self.head_dim)
print(f"values.size(): {values.size()}")
# Step 7: Final linear projection to match d_model
out = self.linear_layer(values)
print(f"out.size(): {out.size()}")
return out`
4. Example: Run With Printouts
Python `
Model/inputs setup
input_dim = 1024 # Input feature size per token d_model = 512 # Embedding/model size (must divide num_heads) num_heads = 8 batch_size = 30 sequence_length = 5
Create random input
x = torch.randn((batch_size, sequence_length, input_dim))
Instantiate MultiheadAttention class and run
model = MultiheadAttention(input_dim, d_model, num_heads) output = model.forward(x)
`
**Output:

Output
Notebook link : Multi Head Self Attention
**Applications of Multi-Head Attention
Multi-head attention is widely used in various domains:
**1. **Natural Language Processing
- Machine translation (e.g., Google Translate)
- Text summarization
- Chatbots and conversational AI
**2. **Computer Vision: Vision Transformers (ViTs) for image recognition
**3. **Speech Processing: Speech-to-text models (e.g., Whisper by OpenAI)
The multi-head attention mechanism is one of the most powerful innovations in deep learning. By attending to multiple aspects of the input sequence in parallel, it enables better representation learning, enhanced contextual understanding and improved performance across NLP, vision and speech tasks.