Multilingual Language Models in NLP (original) (raw)
Last Updated : 13 Jan, 2025
In today’s globalized world, effective communication is crucial, and the ability to seamlessly work across multiple languages has become essential. To address this need, Multilingual Language Models (MLMs) were introduced in Natural Language Processing. These models enable machines to understand, generate, and translate text and speech in different languages.
MLMs have played a key role in breaking down language barriers, fostering a more inclusive digital environment. Beyond being a technological advancement, they also serve as a social enabler, allowing machines to work with a variety of languages.
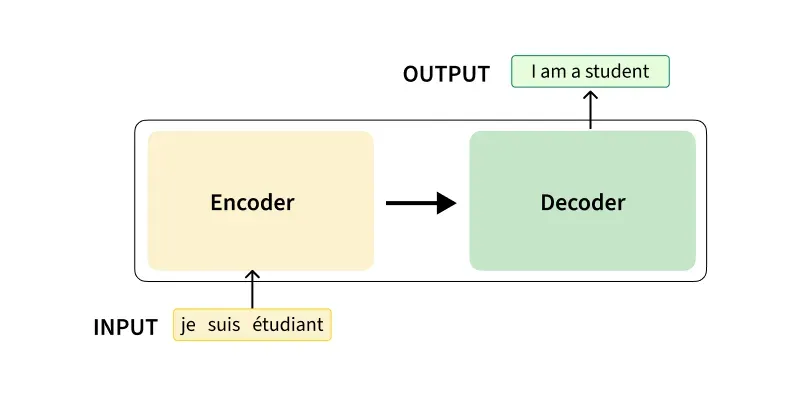
Popular Multilingual Models in NLP
- **mBERT (Multilingual BERT): Pretrained on 104 languages and it excels at NLP tasks. Its versatility makes it a popular choice for multilingual applications.
- **XLM-R (Cross-lingual RoBERTa): Optimised for cross-lingual understanding with improved data and architecture. It addresses challenges in low-resource languages by leveraging knowledge from high-resource languages.
- **mT5 (Multilingual T5): A text-to-text transformer trained on over 101 languages suitable for translation and generative tasks.
- **XLSR (Cross-lingual Speech Representations): Focuses on multilingual speech recognition and handling speech data across many languages. Its applications include voice assistants and transcription services.
Implementing Multilingual Language Model in Python
Here, we are going to perform **sentiment analysis on a list of **multilingual texts using a pre-trained **Multilingual BERT model from the Hugging Face transformers library. The key objectives of the code are:
- **Sentiment Analysis: To evaluate the sentiment (positive, negative, etc.) of various textual inputs in multiple languages (English, French, Spanish, German, Japanese).
- **Multilingual Support: To showcase the capability of the pre-trained model (
nlptown/bert-base-multilingual-uncased-sentiment) to handle texts written in different languages. - **Output Sentiment and Score: For each input text, the code outputs the predicted sentiment label (e.g., positive, negative) and the confidence score associated with the sentiment prediction. Python `
Import necessary libraries
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
Load a pre-trained multilingual model
model_name = "nlptown/bert-base-multilingual-uncased-sentiment" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name)
Create a sentiment analysis pipeline
sentiment_analyzer = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
Function to analyse sentiment of texts in different languages
def analyze_sentiment(texts): for text in texts: result = sentiment_analyzer(text) print(f"Text: {text}\nSentiment: {result[0]['label']}, Score: {result[0]['score']:.4f}\n")
Example multilingual texts
texts = [ "I love natural language processing!", # English "J'adore le traitement automatique du langage.", # French "Me encanta el procesamiento del lenguaje natural.", # Spanish "Ich liebe die Verarbeitung natürlicher Sprache.", # German "私は自然言語処理が大好きです!" # Japanese ]
Call the function with example texts
analyze_sentiment(texts)
`
**Output:
Text: I love natural language processing!
Sentiment: 5 stars, Score: 0.9823
Text: J'adore le traitement automatique du langage.
Sentiment: 5 stars, Score: 0.9745
Text: Me encanta el procesamiento del lenguaje natural.
Sentiment: 5 stars, Score: 0.9768
Text: Ich liebe die Verarbeitung natürlicher Sprache.
Sentiment: 5 stars, Score: 0.9694
Text: 私は自然言語処理が大好きです!
Sentiment: 5 stars, Score: 0.9801
Applications of Multilingual Language Models
- **Machine Translation: Accurate translations between different languages capturing idioms and cultural nuances. For example Google Translate rely on MLM for seamless interaction.
- **Sentiment Analysis: Detecting emotions in speech even if said in different languages enabling businesses to understand customer feedback on a global scale and can be useful for global brands monitoring their reputation.
- **Content Creation: Assisting in creating multilingual content for international audiences such as blogs, articles and marketing materials. MLMs help creators adapt their work in diverse languages and cultural.
- **Language Learning: Educational apps like Duolingo uses MLM's for translation, pronunciation and customized exercises for diverse learners.
Challenges
- **Accuracy: Achieving high accuracy in low-resource languages remains a significant challenge as we have limited data to train our model.
- **Bias: Addressing cultural and linguistic biases is important to ensure fair results without hurting anyone sentiments.
- **Resource Intensity: Developing lightweight models for deployment on less powerful hardware is needed so that anyone can use these models.
- **Complexity: Understanding and implementing these concept of NLP and deep learning are very difficult.