Vectors and Vectorization Techniques in NLP (original) (raw)
Last Updated : 23 Jul, 2025
In Natural Language Processing (NLP), vectors play an important role in transforming human language into a format that machines can comprehend and process. These numerical representations enable computers to perform tasks such as sentiment analysis, machine translation and information retrieval with greater accuracy and efficiency.
- Vectors are numerical representations of words, phrases or entire documents. These vectors capture the semantic meaning and syntactic properties of the text, allowing machines to perform mathematical operations on them.
- Vectorization is the process of transforming words, phrases or entire documents into numerical vectors that can be understood and processed by machine learning models. These numerical representations capture the semantic meaning and contextual relationships of the text, allowing algorithms to perform tasks such as classification, clustering and prediction.
Importance of Vectors in NLP
- **Semantic Understanding: Vectors capture the meaning of words and their relationships enabling tasks like semantic search by focusing on meaning rather than keywords.
- **Dimensionality Reduction: Vectors reduce the complexity of sparse text data, making it easier for models to process and analyze large datasets efficiently.
- **Enhanced Performance: Proper vectorization improves the accuracy and speed of NLP tasks while contextual embeddings like BERT further enhance understanding of word usage.
- **Compatibility: Vectors provide a universal format for various machine learning models, making it easier to integrate NLP solutions across different applications.
Vectorization Techniques in NLP
**1. One-Hot Encoding
One-Hot Encoding is a technique where each word is represented by a vector with a high bit corresponding to the word’s index in the vocabulary with all other bits set to zero.
**Advantages of One-Hot Encoding:
- **Simplicity: Easy to implement and understand.
- **Interpretability: The vectors are easily interpretable and directly map to words.
- **Compatibility: Works well with most machine learning algorithms.
**Disadvantages of One-Hot Encoding:
- **High Dimensionality: Results in large, sparse vectors for large vocabularies.
- **Loss of Semantic Information: Does not capture word relationships or meaning.
- **Sparsity: Creates sparse vectors with mostly zero values, leading to inefficiency. Python `
from sklearn.preprocessing import OneHotEncoder import numpy as np import string
documents = [ "The cat sat on the mat.", "The dog sat on the log.", "Cats and dogs are pets." ]
words = [word.lower().strip(string.punctuation) for doc in documents for word in doc.split()] vocabulary = sorted(set(words))
encoder = OneHotEncoder(sparse_output=False) one_hot_vectors = encoder.fit_transform(np.array(vocabulary).reshape(-1, 1))
word_to_onehot = {vocabulary[i]: one_hot_vectors[i] for i in range(len(vocabulary))}
for word, vector in word_to_onehot.items(): print(f"Word: {word}, One-Hot Encoding: {vector}")
`
**Output:
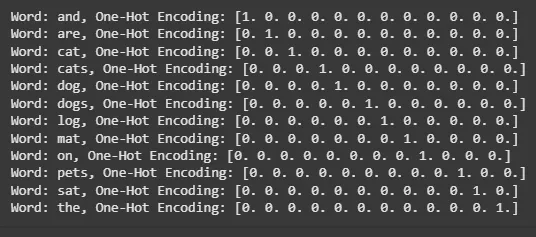
One-Hot Encoding
2. Bag of Words (BoW)
Bag of Words (BoW) converts text into a vector representing the frequency of words, disregarding grammar and word order. It counts the occurrences of each word in a document and generates a vector based on these counts.
**Advantages of Bag of Words (BoW)
- Simple and easy to implement.
- Provides a clear and interpretable representation of text.
**Disadvantages of Bag of Words (BoW)
- Ignores the order and context of words.
- Results in high-dimensional and sparse matrices.
- Fails to capture semantic meaning and relationships between words. Python `
from sklearn.feature_extraction.text import CountVectorizer
documents = [ "The cat sat on the mat.", "The dog sat on the log.", "Cats and dogs are pets." ]
vectorizer = CountVectorizer() X = vectorizer.fit_transform(documents)
print(X.toarray()) print(vectorizer.get_feature_names_out())
`
**Output:
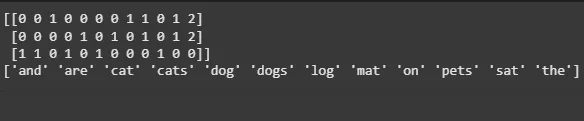
Bag of Words (BoW
3. Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF is an extension of BoW that weighs the frequency of words by their importance across documents.
**1. Term Frequency (TF): Measures the frequency of a word in a document.
TF(t,d) = \frac{\text{Number of times term } t \text{ appears in document } d}{\text{Total number of terms in document } d}
**2. Inverse Document Frequency (IDF): Measures the importance of a word across the entire corpus.
IDF(t) = \log \left( \frac{\text{Total number of documents}}{\text{Number of documents containing term } t} \right)
The TF-IDF score is the product of TF and IDF.
**Advantages of TF-IDF
- **Simple and Efficient: Easy to compute with minimal computational resources.
- **Importance Weighting: Highlights important words by reducing the influence of common words.
- **Effective for Information Retrieval: Improves document relevance ranking in search engines.
**Disadvantages of TF-IDF
- **Sparsity: Produces high-dimensional sparse vectors, increasing memory and computational cost.
- **No Context Capture: Does not account for word context or meaning.
- **Synonym Handling: Treats synonyms as separate which may reduce model accuracy. Python `
from sklearn.feature_extraction.text import TfidfVectorizer
documents = [ "The cat sat on the mat.", "The dog sat on the log.", "Cats and dogs are pets." ]
tfidf_vectorizer = TfidfVectorizer() X_tfidf = tfidf_vectorizer.fit_transform(documents)
print(X_tfidf.toarray()) print(tfidf_vectorizer.get_feature_names_out())
`
**Output:
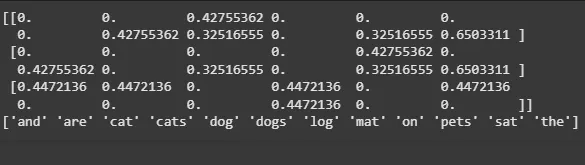
Term Frequency-Inverse Document Frequency (TF-IDF)
4. Count Vectorizer
Count Vectorizer is similar to BoW but focuses on counting the occurrences of each word in the document. It converts a collection of text documents to a matrix of token counts where each element represents the count of a word in a specific document.
**Advantages of Count Vectorizer
- **Simplicity: Easy to implement and understand.
- **Interpretability: Provides a straightforward representation of word frequencies in the document.
- **No Preprocessing Required: Requires minimal preprocessing making it quick to use.
**Disadvantages of Count Vectorizer
- **High Dimensionality: Generates large, sparse matrices especially for large vocabularies.
- **Sparsity: Results in sparse vectors, which can be inefficient in terms of memory and computation.
- **No Semantic Information: Fails to capture the meaning or relationships between words. Python `
from sklearn.feature_extraction.text import CountVectorizer
documents = [ "The cat sat on the mat.", "The dog sat on the log.", "Cats and dogs are pets." ]
count_vectorizer = CountVectorizer() X_count = count_vectorizer.fit_transform(documents)
print(X_count.toarray()) print(count_vectorizer.get_feature_names_out())
`
**Output:
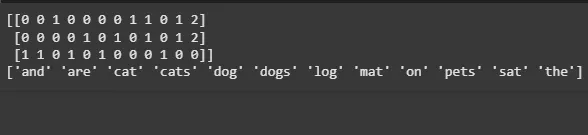
Count Vectorizer
Advanced Vectorization Techniques in Natural Language Processing (NLP)
1. Word Embeddings
Word embeddings are dense vector representations of words in a continuous vector space where semantically similar words are located closer to each other. These embeddings capture the context of a word, its syntactic role and semantic relationships with other words leading to better performance in various NLP tasks.
Word Embedding
**Advantages:
- Captures semantic meaning and relationships between words.
- Dense representations are computationally efficient.
- Handles out-of-vocabulary words especially with FastText.
**Disadvantages:
- Requires large corpora for training high-quality embeddings.
- May not capture complex linguistic nuances in all contexts.
2. Image Embeddings
Image embeddings transforms images into numerical representations through which our model can perform image search, object recognition and image generation.

Image embedding
**Advantages:
- **Semantic Representation: Captures meaningful features in a compact form.
- **Dimensionality Reduction: Reduces image complexity while maintaining important features.
- **Improved Performance: Enhances accuracy for downstream tasks.
**Disadvantages:
- **Dependency on Pre-trained Models: Embedding quality depends on the model used.
- **Complexity: Requires additional computational resources for embedding generation.
Comparison of Vectorization Techniques
Lets see a quick comparisonbetween different technique:
| Technique | Accuracy | Computation Time | Memory Usage | Applicability |
|---|---|---|---|---|
| **Bag of Words (BoW) | Low to Moderate | Low | High | Simple text classification tasks |
| **TF-IDF | Moderate | Moderate | High | Text classification, information retrieval, keyword extraction |
| **Count Vectorizer | Low to Moderate | Low | High | Tasks focusing on word frequency |
| **Word Embeddings | High | High | Moderate to High | Sentiment analysis, named entity recognition, machine translation |
| **Image Embeddings | High | High | Moderate to High | Image classification, object detection, image retrieval |
Choosing the right vectorization technique depends on the specific NLP task, available computational resources and the importance of capturing semantic and contextual information. Traditional techniques like BoW and TF-IDF are simpler and faster but may fall short in capturing the nuanced meaning of text. Advanced techniques like word embeddings and document embeddings provide richer, context-aware representations at the cost of increased computational complexity and memory usage.