What is Mixture of Experts (MoE)? (original) (raw)
Last Updated : 23 Jul, 2025
Mixture of experts (MoE) is a machine learning approach that divides a machine learning model into separate sub networks or experts where each of these experts specialize in a subset of the input data to jointly perform a task. This approach helps to increase efficiency of the model while keeping the computational cost low.
For example:
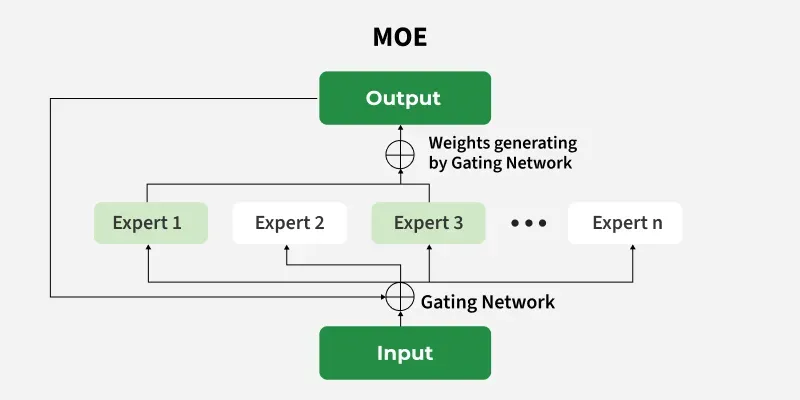
Mixture of Experts
- **Input: This is the data you want the machine learning model to handle.
- **Experts: These are smaller sub networks of the model where each is trained to be really good at a specific part of the problem.
- **Gating network: This is like a manager who decides which expert or sub network is best suited for each part of the problem.
- **Output: This is the final solution that the machine learning model produces after the experts have done their work.
How does MOE works?
MOE works in two phases:
- Training phase
- Inference phase
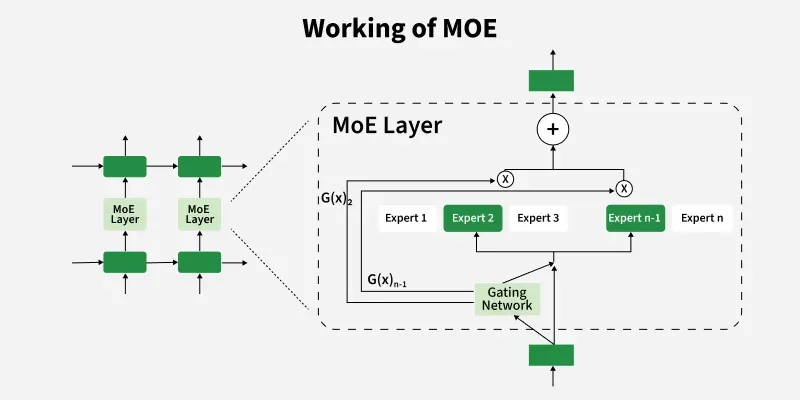
Working architecture of MOE
Training phase
1. Training the Experts
- Each expert is trained on a specific part of the data or a specific problem our model wants to solve.
- Each expert learns by itself using the usual training method and try to reduce its own errors.
2. Training the Gating Network
- The gating network is like a traffic controller which looks at the input and decides which expert should handle it.
- While the experts are being trained, the gating network also learns to assign probabilities to each expert who is most likely to give the best output.
- The gating network computes scores G(x)1........G(x)n
- The gating network is trained to make better decisions over time by checking how well the chosen experts perform.
3. Joint Training
- At this stage the experts and the gating network are trained together
- They work as a team as the model tries to reduce the total error from both the experts and the gating network and updates are made to improve the whole system not just individual parts.
- This makes sure that the gating network picks the right experts and that the experts give good outputs.
Inference phase
1. Input routing
- When a new input comes in the gating network decides which experts should handle it.
- It looks at the input and gives probabilities scores to each expert and based on these scores it sends the input to the most suitable experts which helps the system use the right expert for each task.
2. Expert selection
- Instead of using all experts MOE models picks only one based on who got the highest probabilities scores from the gating network.
- This saves time and computing power while using the experts that are best suited for that task.
3. Output Combination
- After the chosen experts do their work, their answers are combined into one final result.
- This is usually done using weighted averaging where the expert with the highest probability score has more influence.
- The goal is to get a more accurate and balanced answer by using the strengths of each expert.
Applications
- **Natural language processing (NLP): In traditional models the entire model is used every time you give it input even if it is not needed which takes a lot of time and computing power. Whereas inn an MoE model experts are used based on what the input needs. This is called sparsity and it helps the model work faster and use less power without losing accuracy.
- **Computer vision: MOE models does not look at the whole image at once they split the image into small patches and these patches go through a gating network which decides which expert should handle each patch. This helps the model be more accurate and efficient.
- **Recommendation systems: MOE's are popular in recommendation system because they can break a large problem into smaller tasks, each handled by a simple expert which makes training faster and works well for large scale systems.
Advantages
- **Flexibility: The diversity of tasks between experts make MOE models highly flexible.
- **Fault tolerance: MoE’s use 'divide and conquer' approach where tasks are executed separately which enhances the model's resilience to failures.
- **Scalability: MOE's decompose complex problems into smaller and more manageable tasks which helps MoE models handle increasingly complicated inputs.
Disadvantages
- **Complexity in training phase: training MOE models can be tricky because it requires coordination between the experts and the gating network which is hard to achieve.
- **Low Inference efficiency: The gating network needs to run for each input to determine the right experts which adds extra computation and running multiple experts in parallel can be challenging in environments with limited computational resources.
- **Increased model size: Storing multiple expert networks and the gating network increases the overall storage of the model and deploying such models is harder due to their size and complexity.