Pandas Introduction (original) (raw)
Last Updated : 5 Dec, 2025
Pandas is an open-source Python library used for data manipulation, analysis and cleaning. It provides fast and flexible tools to work with tabular data, similar to spreadsheets or SQL tables.
Pandas is used in data science, machine learning, finance, analytics and automation because it integrates smoothly with other libraries such as:
- NumPy: numerical operations
- Matplotlib and Seaborn: data visualization
- SciPy: statistical analysis
- Scikit-learn: machine learning workflows
With Pandas, you can load data, clean it, transform it, analyze it, visualize it all in just a few lines of code.
Pandas Basic Operations
Installation
Before using Pandas, make sure it is installed:
pip install pandas
After the Pandas have been installed in the system we need to import the library. This module is imported using:
import pandas as pd
**Note: pd is just an alias for Pandas. It’s not required but using it makes the code shorter when calling methods or properties.
Data Structures in Pandas
Pandas provides two data structures for manipulating data which are as follows:
1. Pandas Series
A Pandas Series is one-dimensional labeled array capable of holding data of any type (integer, string, float, Python objects etc.). The axis labels are collectively called **indexes. Series is created by loading the datasets from existing storage which can be a SQL database, a CSV file or an Excel file.
Python `
import pandas as pd import numpy as np
s = pd.Series() print("Pandas Series: ", s) data = np.array(['g', 'e', 'e', 'k', 's'])
s = pd.Series(data) print("Pandas Series:\n", s)
`
**Output

Pandas Series
2. Pandas DataFrame
Pandas DataFrame is a two-dimensional data structure with labeled axes (rows and columns). It is created by loading the datasets from existing storage which can be a SQL database, a CSV file or an Excel file. It can be created from lists, dictionaries, a list of dictionaries etc.
Python `
import pandas as pd
df = pd.DataFrame() print(df) lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks']
df = pd.DataFrame(lst) print(df)
`
**Output:

Pandas DataFrame
Operations in Pandas
Pandas provides essential operations for working with structured data efficiently. The sections below introduce the most commonly used functionalities with short explanations and simple examples.
**1. Loading Data: This operation reads data from files such as CSV, Excel or JSON into a DataFrame.
Python `
import pandas as pd
df = pd.read_csv("data.csv") print(df.head())
`
**Output
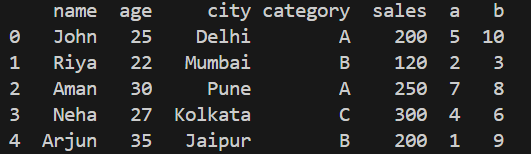
Output of Loading Dataset
**Explanation: pd.read_csv("data.csv") reads the CSV file and loads it into a DataFrame and **df.head() shows the first 5 rows of the data.
**2. Viewing and Exploring Data: After loading data, it is important to understand its structure and content. This methods allow you to inspect rows, summary statistics and metadata.
Python `
print(df.info())
`
**Output
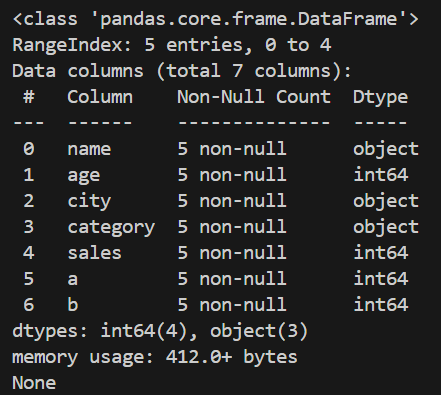
Output of df.info()
**3. Handling Missing Data: Datasets often contain empty or missing values. Pandas provides functions to detect, remove or replace these values.
Python `
print(df.isnull().sum()) df = df.fillna(0)
`
**Output
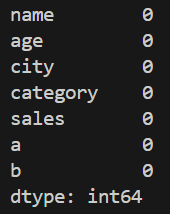
No Columns have NAN value
**Explanation: df.fillna(0) replaces missing values with 0.
**4. Selecting and Filtering Data: This operation retrieves specific columns, rows or records that match a condition. It allows precise extraction of required information.
Python `
ages = df[df['age'] > 25] print(ages)
`
**Output
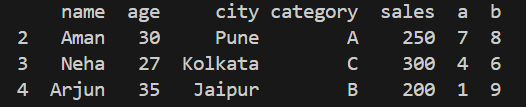
Output of Filtering Data
**Explanation df[df['age'] > 25] returns rows where the "age" value is greater than 25.
**5. Adding and Removing Columns: You can create new columns based on existing ones or delete unwanted columns from the DataFrame.
Python `
df['total'] = df['a'] + df['b'] print(df.head())
`
**Output
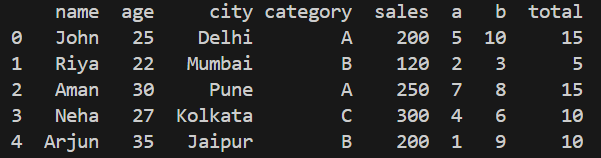
Adding new column "total"
**Explanation: df['total'] = df['a'] + df['b'] creates a new column named "total".
**6. Grouping Data (GroupBy): Grouping allows you to organize data into categories and compute values for each group for example, sums, counts or averages.
Python `
res = df.groupby('category')['sales'].sum() print(res)
`
**Output
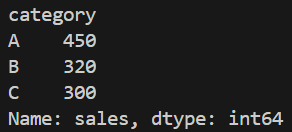
Grouping Data
**Explanation: df.groupby('category') divides the dataset based on the "category" column.
To learn Pandas from basic to advanced refer to Pandas tutorial