Pandas dataframe.aggregate() | Python (original) (raw)
Last Updated : 11 Apr, 2025
Dataframe.aggregate() function is used to apply some aggregation across one or more columns. Aggregate using callable, string, dict or list of string/callables.
The most frequently used aggregations are:
- **sum: Return the sum of the values for the requested axis
- **min: Return the minimum of the values for the requested axis
- **max: Return the maximum of the values for the requested axis
Syntax
DataFrame.aggregate(func, axis=0, *args, **kwargs)
**Parameters:
- **func : callable, string, dictionary or list of string/callables. Function to use for aggregating the data. If a function, must either work when passed a DataFrame or when passed to DataFrame.apply. For a DataFrame, can pass a dict, if the keys are DataFrame column names.
- **axis : (default 0) {0 or ‘index’, 1 or ‘columns’} 0 or ‘index’: apply function to each column. 1 or ‘columns’: apply function to each row.
**Return Type: Returns Aggregated DataFrame.
Importing Pandas and Reading CSV File
For link to CSV file Used in Code, click
Python `
importing pandas package
import pandas as pd
making data frame from csv file
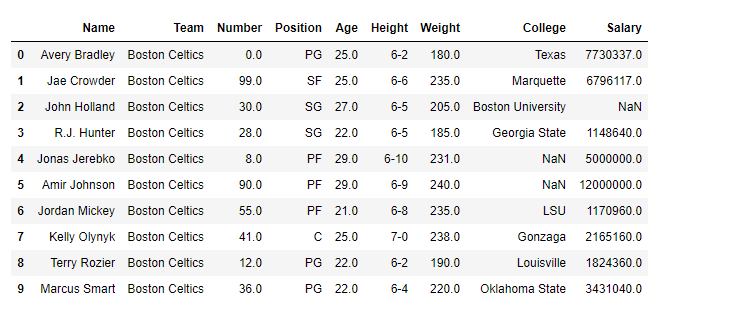
df = pd.read_csv("nba.csv")
printing the first 10 rows of the dataframe
df[:10]
`
**Output :
Examples of dataframe.aggregate()
Below, we are discussing how to add values of Excel in Python using Pandas
Example 1: Aggregating Data Across All Numeric Columns
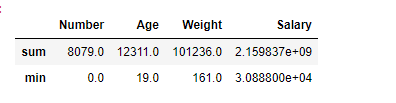
We can Aggregate data across all numeric columns using built-in functions such as ‘sum’ and ‘min’.
Python `
df.select_dtypes(include='number').aggregate(['sum', 'min'])
`
**Output:
For each column which are having numeric values, minimum and sum of all values has been found. For Pandas Dataframe df , we have four such columns Number, Age, Weight, Salary.
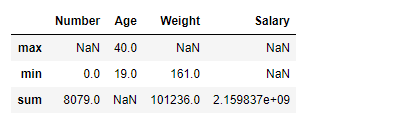
Example 2: Aggregating Specific Columns
In Pandas, we can also apply different aggregation functions across different columns. For that, we need to pass a dictionary with key containing the column names and values containing the list of aggregation functions for any specific column.
Python `
df.aggregate({"Number":['sum', 'min'],
"Age":['max', 'min'],
"Weight":['min', 'sum'],
"Salary":['sum']})
`
**Output:
Separate aggregation has been applied to each column, if any specific aggregation is not applied on a column then it has NaN value corresponding to it.