Python | Pandas Merging, Joining and Concatenating (original) (raw)
When we're working with multiple datasets we need to combine them in different ways. Pandas provides three simple methods like merging, joining and concatenating. These methods help us to combine data in various ways whether it's matching columns, using indexes or stacking data on top of each other. In this article, we'll see these methods.
Concatenating DataFrames
Concatenating DataFrames means combining them either by stacking them on top of each other (vertically) or placing them side by side (horizontally). In order to Concatenate dataframe, we use different methods which are as follows:
1. Concatenating DataFrame using .concat()
To concatenate DataFrames, we use the pd.concat() function. This function allows us to combine multiple DataFrames into one by specifying the axis (rows or columns).
Here we will be loading and printing the custom dataset, then we will perform the concatenation using pd.concat().
Python `
import pandas as pd
data1 = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age': [27, 24, 22, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd']}
data2 = {'Name': ['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age': [17, 14, 12, 52], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Btech', 'B.A', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1, index=[0, 1, 2, 3])
df1 = pd.DataFrame(data2, index=[4, 5, 6, 7])
print(df, "\n\n", df1)
`
**Output:

output
Now we apply .concat function in order to concat two dataframe.
Python `
frames = [df, df1]
res1 = pd.concat(frames) res1
`
**Output:

output
**2. Concatenating DataFrames by Setting Logic on Axes
We can modify the concatenation by setting logic on the axes. Specifically we can choose whether to take the Union (join='outer') or Intersection (join='inner') of columns.
Python `
import pandas as pd
data1 = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age': [27, 24, 22, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]}
data2 = {'Name': ['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age': [22, 32, 12, 52], 'Address': ['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification': ['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary': [1000, 2000, 3000, 4000]}
df = pd.DataFrame(data1, index=[0, 1, 2, 3])
df1 = pd.DataFrame(data2, index=[2, 3, 6, 7])
print(df, "\n\n", df1)
`
**Output:

output
Now we set axes join = inner for intersection of dataframe which keeps only the common columns.
Python `
res2 = pd.concat([df, df1], axis=1, join='inner')
res2
`
**Output:

output
Now we set axes join = outer for union of dataframe which keeps all columns from both DataFrames.
Python `
res2 = pd.concat([df, df1], axis=1, sort=False)
res2
`
**Output:

output
3. **Concatenating DataFrames by Ignoring Indexes
Sometimes the indexes of the original DataFrames may not be relevant. We can ignore the indexes and reset them using the **ignore_index argument. This is useful when we don't want to carry over any index information.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]}
data2 = {'Name':['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age':[22, 32, 12, 52], 'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary':[1000, 2000, 3000, 4000]}
df = pd.DataFrame(data1,index=[0, 1, 2, 3])
df1 = pd.DataFrame(data2, index=[2, 3, 6, 7])
print(df, "\n\n", df1)
`
**Output:

output
Now we are going to apply ignore_index as an argument.
Python `
res = pd.concat([df, df1], ignore_index=True)
res
`
**Output:

output
4. **Concatenating DataFrame with group keys :
If we want to retain information about the DataFrame from which each row came, we can use the **keys argument. This assigns a label to each group of rows based on the source DataFrame.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
data2 = {'Name':['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age':[17, 14, 12, 52], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1,index=[0, 1, 2, 3])
df1 = pd.DataFrame(data2, index=[4, 5, 6, 7])
print(df, "\n\n", df1)
`
**Output:

output
Here we will use keys as an argument. The keys argument creates a hierarchical index where each row is labeled with the source DataFrame (df1 or df2).
Python `
frames = [df, df1 ]
res = pd.concat(frames, keys=['x', 'y']) res
`
**Output:

output
5. **Concatenating Mixed DataFrames and Series
We can also concatenate a mix of Series and DataFrames. If we include a Series in the list, it will automatically be converted to a DataFrame and we can specify the column name.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
df = pd.DataFrame(data1,index=[0, 1, 2, 3])
s1 = pd.Series([1000, 2000, 3000, 4000], name='Salary')
print(df, "\n\n", s1)
`
**Output:

output
Here we are going to mix Series and dataframe together.
Python `
res = pd.concat([df, s1], axis=1)
res
`
**Output:

output
Merging DataFrame
Merging DataFrames in Pandas is similar to performing SQL joins. It is useful when we need to combine two DataFrames based on a common column or index. The merge() function provides flexibility for different types of joins.
There are four basic ways to handle the join (inner, left, right and outer) depending on which rows must retain their data.
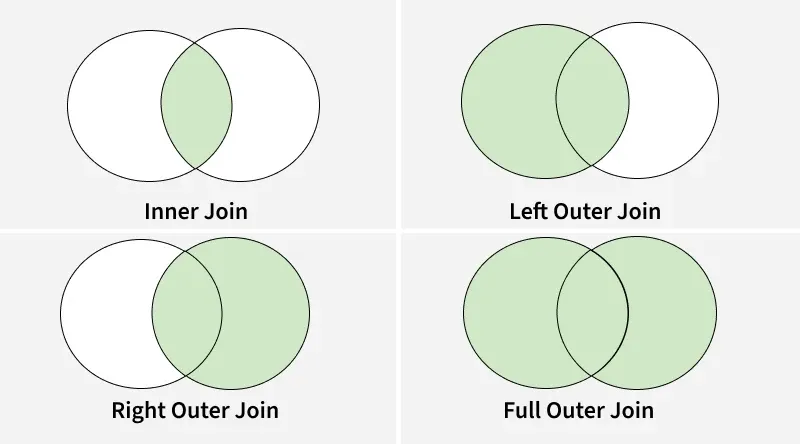
Joins
1. Merging DataFrames Using One Key
We can merge DataFrames based on a common column by using the on argument. This allows us to combine the DataFrames where values in a specific column match.
Python `
import pandas as pd
data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],}
data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1)
df1 = pd.DataFrame(data2)
print(df, "\n\n", df1)
`
**Output:

output
Now here we are using .merge() with one unique key combination.
Python `
res = pd.merge(df, df1, on='key')
res
`
**Output:

output
**2. Merging DataFrames Using Multiple Keys
We can also merge DataFrames based on more than one column by passing a list of column names to the on argument.
Python `
import pandas as pd
data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],}
data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1)
df1 = pd.DataFrame(data2)
print(df, "\n\n", df1)
`
**Output:

output
Now we merge dataframe using multiple keys.
Python `
res1 = pd.merge(df, df1, on=['key', 'key1'])
res1
`
**Output:

output
**3. Merging DataFrames Using the how Argument
We use **how argument to merge specifies how to find which keys are to be included in the resulting table. If a key combination does not appear in either the left or right tables, the values in the joined table will be NA. Here is a summary of the how options and their SQL equivalent names:
| MERGE METHOD | JOIN NAME | DESCRIPTION |
|---|---|---|
| **left | LEFT OUTER JOIN | Use keys from left frame only |
| **right | RIGHT OUTER JOIN | Use keys from right frame only |
| **outer | FULL OUTER JOIN | Use union of keys from both frames |
| **inner | INNER JOIN | Use intersection of keys from both frames |
Python `
import pandas as pd
data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],}
data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1)
df1 = pd.DataFrame(data2)
print(df, "\n\n", df1)
`
**Output:

output
Now we set how = 'left' in order to use keys from leftframe only. In this it includes all rows from the left DataFrame and only matching rows from the right.
Python `
res = pd.merge(df, df1, how='left', on=['key', 'key1'])
res
`
**Output:

output
Now we set how = 'right' in order to use keys from rightframe only. In this it includes all rows from the right DataFrame and only matching rows from the left.
Python `
res1 = pd.merge(df, df1, how='right', on=['key', 'key1'])
res1
`
**Output:

output
Now we set how = 'outer' in order to get **union of keys from dataframes. In this it combines all rows from both DataFrames, filling missing values with NaN.
Python `
res2 = pd.merge(df, df1, how='outer', on=['key', 'key1'])
res2
`
**Output:

output
Now we set how = 'inner' in order to get intersectionof keys from dataframes. In this it only includes rows where there is a match in both DataFrames.
Python `
res3 = pd.merge(df, df1, how='inner', on=['key', 'key1'])
res3
`
**Output:

output
Joining DataFrame
The .join() method in Pandas is used to combine columns of two DataFrames based on their indexes. It's a simple way of merging two DataFrames when the relationship between them is primarily based on their row indexes. It is used when we want to combine DataFrames along their indexes rather than specific columns.
1. Joining DataFrames Using .join()
If both DataFrames have the same index, we can use the .join() function to combine their columns. This method is useful when we want to merge DataFrames based on their row indexes rather than columns.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]}
data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3'])
df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4'])
print(df, "\n\n", df1)
`
**Output:

output
Now we are using .join() method in order to join dataframes
Python `
res = df.join(df1)
res
`
**Output:

output
Now we use how = 'outer' in order to get union
Python `
res1 = df.join(df1, how='outer')
res1
`
**Output:

output
**2. Joining DataFrames Using the "on" Argument
If we want to join DataFrames based on a column (rather than the index), we can use the on argument. This allows us to specify which column(s) should be used to align the two DataFrames.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Key':['K0', 'K1', 'K2', 'K3']}
data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1)
df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4'])
print(df, "\n\n", df1)
`
**Output:

output
Now we are using .join with “on” argument.
Python `
res2 = df.join(df1, on='Key')
res2
`
**Output:

output
**3. Joining DataFrames with Different Index Levels (Multi-Index)
In some cases, we may be working with DataFrames that have multi-level indexes. The .join() function also supports joining DataFrames that have different index levels by specifying the index levels.
Python `
import pandas as pd
data1 = {'Name':['Jai', 'Princi', 'Gaurav'], 'Age':[27, 24, 22]}
data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kanpur'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']}
df = pd.DataFrame(data1, index=pd.Index(['K0', 'K1', 'K2'], name='key'))
index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'), ('K2', 'Y2'), ('K2', 'Y3')], names=['key', 'Y'])
df1 = pd.DataFrame(data2, index= index)
print(df, "\n\n", df1)
`
**Output:

output
Now we join singlyindexed dataframe with multi-indexed dataframe.
Python `
result = df.join(df1, how='inner')
result
`
**Output:

output
What is the result of using pd.merge(df1, df2, on='ID')?
- Concatenates two DataFrames
- Merges two DataFrames based on the 'ID' column
- Joins two DataFrames with an outer join
- Joins two DataFrames with a left join
Explanation:
The pd.merge() function merges two DataFrames based on a common column (here, 'ID').
Which of the following types of joins can be specified in pd.merge()?
- Inner join
- Left join
- Right join
- All of the above
Explanation:
You can specify different types of joins in pd.merge() including inner, left, right, and outer joins.
If df1 has a column 'ID' and df2 has a column 'UserID', what should you do to merge them based on these columns?
- pd.merge(df1, df2, on='ID')
- pd.merge(df1, df2, left_on='ID', right_on='UserID')
- df1.merge(df2, left='ID', right='UserID')
- Both b and c
Explanation:
To merge on different column names, you can specify left_on and right_on, as shown in options b and c.

Quiz Completed Successfully
Your Score : 2/3
Accuracy : 0%
Login to View Explanation
1/3
1/3 < Previous Next >