Pandas.pivot_table() Python (original) (raw)
Last Updated : 28 Apr, 2025
**pandas.pivot_table() function allows us to create a pivot table to summarize and aggregate data. This function is important when working with large datasets to analyze and transform data efficiently. In this article, we will see some examples to see how it works.
Lets see a example:
Python `
import pandas as pd df = pd.DataFrame({ 'A': ['John', 'Boby', 'Mina', 'Peter', 'Nicky'], 'B': ['Masters', 'Graduate', 'Graduate', 'Masters', 'Graduate'], 'C': [27, 23, 21, 23, 24] })
df table = pd.pivot_table(df, index=['A', 'B']) table
`
**Output:
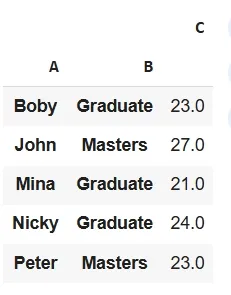
Basic Pivot Table
Here **pd.pivot_table(df, index=['A', 'B']) created a pivot table that groups data by columns 'A' and 'B' and aggregates their values by calculating their mean.
**Syntax:
DataFrame.pivot_table( values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True)
Parameters:
- **values: Columns to aggregate.
- **index: Columns to use as the new row index.
- **columns: Columns to use as the new column headers.
- **aggfunc: Aggregation functions like mean, sum, count etc. By default it is mean.
- **fill_value: Value to replace missing data.
- **margins: Whether to add totals, default is false.
- **dropna: Whether to exclude missing values from the DataFrame, default is True.
Returns: DataFrame
Example 1: Using the values and aggfunc Parameters
We can customize aggregation by specifying the **values parameter (column to aggregate) and the **aggfunc parameter (aggregation function). By default aggregation is mean but we can use functions like sum, count etc.
- **table = pd.pivot_table(df, values='C', index='C', columns='B', aggfunc='sum'): Creating a pivot table that groups data by column 'C' as rows and column 'B' as columns which helps in summing values in column 'C' for each combination of 'C' and 'B'. Python `
import pandas as pd import numpy as np df = pd.DataFrame({ 'A': ['John', 'Boby', 'Mina', 'Peter', 'Nicky'], 'B': ['Masters', 'Graduate', 'Graduate', 'Masters', 'Graduate'], 'C': [27, 23, 21, 23, 24] }) table = pd.pivot_table(df, values='C', index='C', columns='B', aggfunc='sum') print(table)
`
**Output:
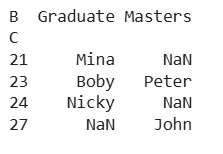
Pivot Table using aggfunc
Example 2: Handling Missing Data with fill_value
Using the **fill_value parameter to replace missing values in the pivot table. This is helpful when we don’t want missing data to appear as NaN.
- **table = pd.pivot_table(df, values='C', index=['A', 'B'], fill_value=0): Creating a pivot table that groups data by columns 'A' and 'B' and helps in aggregating values in column 'C' and it replaces any missing values with 0. Python `
import pandas as pd import numpy as np df = pd.DataFrame({ 'A': ['John', 'Boby', 'Mina', 'Peter', 'Nicky'], 'B': ['Masters', 'Graduate', 'Graduate', 'Masters', 'Graduate'], 'C': [27, 23, 21, 23, 0] }) table = pd.pivot_table(df, values='C', index=['A', 'B'], fill_value=0) table
`
**Output:
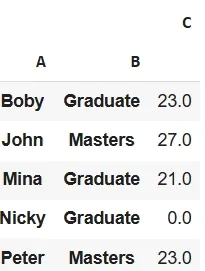
Pivot Table using fill_value
Example 3: Adding Totals with margins
The **marginsparameter adds total rows and columns to the pivot table. This is useful when we want to see overall totals for each row or column.
- **table = pd.pivot_table(df, values='C', index=['A', 'B'], aggfunc='mean', margins=True): Creating a pivot table that groups data by columns 'A' and 'B' and helps in calculating mean of values in column 'C' and adds a total row and column with the overall mean (using margins=True). Python `
import pandas as pd import numpy as np df = pd.DataFrame({ 'A': ['John', 'Boby', 'Mina', 'Peter', 'Nicky'], 'B': ['Masters', 'Graduate', 'Graduate', 'Masters', 'Graduate'], 'C': [27, 23, 21, 23, 24] }) table = pd.pivot_table(df, values='C', index=['A', 'B'], aggfunc='mean', margins=True) table
`
**Output:

Pivot Table with Margins
With **pandas.pivot_table() we can create customizable summaries of our data which is required for specific analysis needs.