Word Embedding using Word2Vec (original) (raw)
Last Updated : 04 Oct, 2025
Word2Vec is a word embedding technique in natural language processing (NLP) that allows words to be represented as vectors in a continuous vector space. Researchers at Google developed word2Vec that maps words to high-dimensional vectors to capture the semantic relationships between words. It works on the principle that words with similar meanings should have similar vector representations. Word2Vec utilizes two architectures:
**1. CBOW (Continuous Bag of Words)
The CBOW model predicts the current word given context words within a specific window. The input layer contains the context words and the output layer contains the current word. The hidden layer contains the dimensions we want to represent the current word present at the output layer.
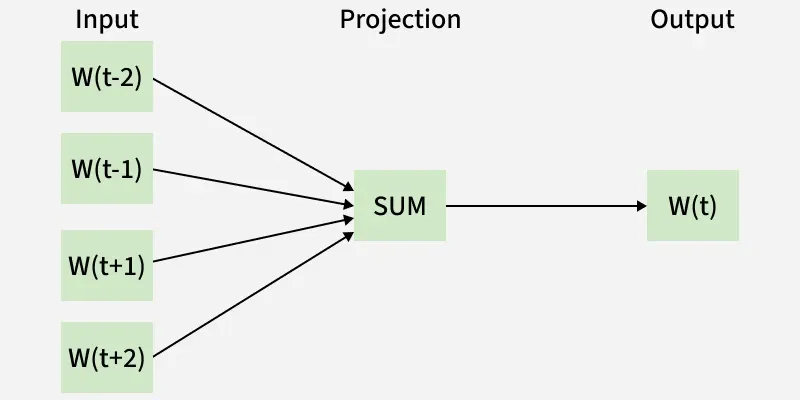
CBOW (Continuous Bag of Words)
**2. Skip Gram
TheSkip gram predicts the surrounding context words within specific window given current word. The input layer contains the current word and the output layer contains the context words. The hidden layer contains the number of dimensions in which we want to represent current word present at the input layer.
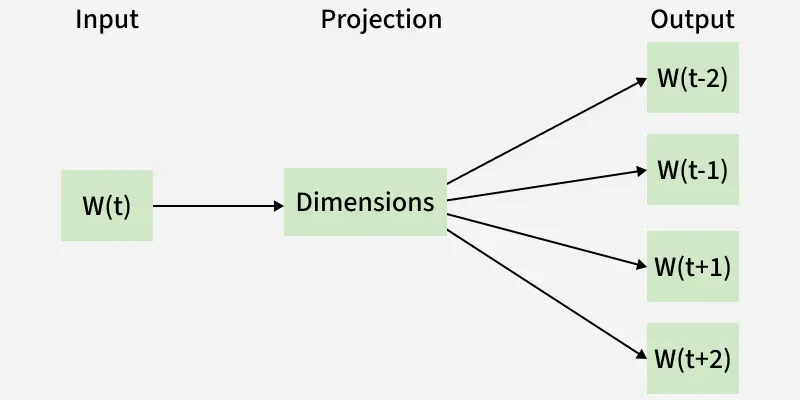
Skip Gram
Implementation of Word2Vec
We will implement word2vec using Python programming language.
You can download the text file used for generating word vectors from here.
1. Importing Required Libraries
We will import necessary NLTK and Gensim for building the Word2Vec model and processing text:
- **Word2Vec from **gensim to build the word vector model.
- **nltk.tokenize helps in splitting text into sentences and words.
- **warnings is used to suppress irrelevant warnings during execution. Python `
from gensim.models import Word2Vec import gensim from nltk.tokenize import sent_tokenize, word_tokenize nltk.download('punkt_tab') import warnings
warnings.filterwarnings(action='ignore')
`
2. Loading and Cleaning the Dataset
We will load the text data from a zip file, clean it by removing newline characters and prepare it for tokenization. We will replace newline characters (\n) with spaces to ensure the sentences are properly formatted.
- **zipfile.ZipFile: reads the zip file.
- **open(file_name): extract the content of the first file inside the zip and decode it. Python `
import zipfile
with zipfile.ZipFile("/content/Gutenburg.zip", 'r') as zip_ref: file_name = zip_ref.namelist()[0] with zip_ref.open(file_name) as file: content = file.read().decode('utf-8', errors='ignore') cleaned_text = content.replace("\n", " ") print("File loaded")
`
Output:
File loaded
3. Text Tokenization
We will tokenize the cleaned text into sentences and words. We will append these tokenized words into a list, where each sentence is a sublist.
- **sent_tokenize(): Splits the text into sentences.
- **word_tokenize(): Tokenizes each sentence into words.
- ****.lower():** Converts each word into lowercase to ensure uniformity. Python `
data = []
for i in sent_tokenize(cleaned_text): temp = []
# tokenize the sentence into words
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)`
4. Building Word2Vec Models
We will build a Word2Vec model using both CBOW and Skip-Gram architecture one by one.
**4.1. Using CBOW Model
We will be using the CBOW architecture:
- **min_count=1: Includes words that appear at least once.
- **vector_size=100: Generates word vectors of 100 dimensions.
- **window=5: Considers a context window of 5 words before and after the target word.
- **sg=0: Uses CBOW model (default setting). Python `
model1 = gensim.models.Word2Vec(data, min_count=1, vector_size=100, window=5)
`
**4.2. Using Skip-Gram Model
We will be using the Skip-Gram architecture for this model.
- **min_count=1: Includes words that appear at least once.
- **vector_size=100: Generates word vectors of 100 dimensions.
- **window=5: Considers a context window of 5 words.
- **sg=1: Enables the Skip-Gram model (predicts context words given a target word). Python `
model2 = gensim.models.Word2Vec(data, min_count=1, vector_size=100, window=5, sg=1)
`
6. Evaluating Word Similarities
We will compute the cosine similarity between word vectors to assess semantic similarity. Cosine similarity values range from -1 (opposite) to 1 (very similar), showing how closely related two words are in terms of meaning.
- **model.wv.similarity(word1, word2): Computes the cosine similarity between word1 and word2 based on the trained model. Python `
print("Cosine similarity between 'alice' " + "and 'wonderland' - CBOW : ", model1.wv.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " + "and 'machines' - CBOW : ", model1.wv.similarity('alice', 'machines'))
`
**Output :

Cosine similarity between words
Output indicates the cosine similarities between word vectors ‘alice’, ‘wonderland’ and ‘machines' for different models. One interesting task might be to change the parameter values of ‘size’ and ‘window’ to observe the variations in the cosine similarities.
**Applications of Word Embedding:
- **Text classification: Using word embeddings to increase the precision of tasks such as topic categorization and sentiment analysis.
- **Named Entity Recognition (NER): Using word embeddings semantic context to improve the identification of entities such as names and locations.
- **Information Retrieval: To provide more precise search results, embeddings are used to index and retrieve documents based on semantic similarity.
- **Machine Translation: The process of comprehending and translating the semantic relationships between words in various languages by using word embeddings.
- **Question Answering:Increasing response accuracy and understanding of semantic context in Q&A systems.
What is the main principle behind Word2Vec?
- Words with similar meanings appear in similar contexts
- Words are stored as one-hot encoded vectors
- Words are ranked based on frequency only
- Words are grouped alphabetically
Explanation:
Word2Vec uses distributional semantics — words occurring in similar contexts get similar vector representations.
In the CBOW architecture of Word2Vec, what is predicted?
- The context words from the target word
- The target word from the context words
- Word frequency across documents
- The position of a word in a sentence
Explanation:
CBOW predicts the current (target) word using the surrounding context words.
Which parameter setting in Gensim’s Word2Vec specifies the Skip-Gram model?
- sg=0
- sg=1
- window=10
- vector_size=200
Explanation:
In Gensim, sg=0 means CBOW, while sg=1 enables Skip-Gram.
What metric does Word2Vec typically use to compute similarity between two words?
- Cosine Similarity
- Euclidean Distance
- Jaccard Similarity
- Manhattan Distance
Explanation:
Word2Vec vectors are compared using cosine similarity, which measures orientation (not magnitude) between vectors.

Quiz Completed Successfully
Your Score : 2/4
Accuracy : 0%
Login to View Explanation
1/4
1/4 < Previous Next >