Exploratory Data Analysis in R Programming (original) (raw)
Last Updated : 30 Apr, 2026
Exploratory Data Analysis (EDA) is a process for analyzing and summarizing the key characteristics of a dataset, often using visual methods. It helps to understand the structure, relationships and potential issues in data before conducting formal modeling. Key Aspects of EDA
- **Characteristics of the data: Understanding the variables and their distribution.
- **Relationships between variables: Investigating how variables correlate with each other.
- **Identifying key variables: Finding the most important variables that can be used in the analysis.
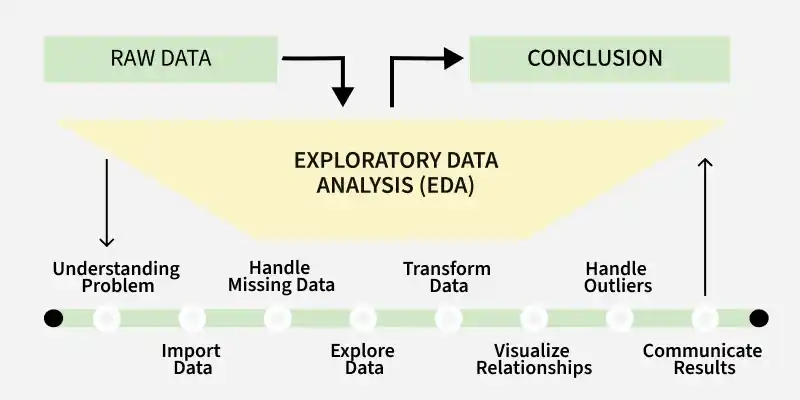
Exploratory Data Analysis
EDA is an iterative process that involves:
- **Generating questions about the data.
- **Searching for answers using visualization, transformation and modeling.
- **Refining the questions or generating new ones based on what has been learned.
In R, we perform EDA through two primary approaches:
- **Descriptive Statistics: Summarizing data using numerical methods such as mean, median and standard deviation.
- **Graphical Methods: Visualizing data through plots like histograms, box plots and scatter plots.
In this example, we will use the built-in iris dataset in R to show EDA techniques.
R `
data("iris") head(iris)
`
**Output:
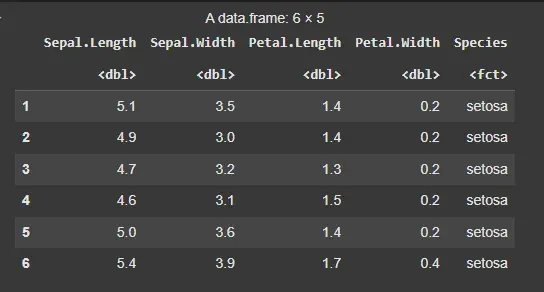
iris dataset
Descriptive Statistics for EDA
Descriptive statistics involve summarizing and describing the main features of a dataset through numerical measures like mean, median, mode, standard deviation, variance and range. These statistics help in understanding the central tendency, dispersion and overall distribution of the data,
Measures of Central Tendency
To summarize the data, we begin with measures of central tendency: the mean, median and mode of the numeric variables.
- **mean(): Calculates the average of a numeric variable.
- **median(): Finds the middle value of a numeric variable.
- **getmode(): Custom function to find the most frequent value (mode) of a variable. R `
getmode <- function(v) { uniqv <- unique(v) uniqv[which.max(tabulate(match(v, uniqv)))] }
cat("\n Mean Sepal Length: ",mean(iris$Sepal.Length)) cat("\n Median Sepal Length: ",median(iris$Sepal.Length)) cat("\n Mode Sepal Length: ",getmode(iris$Sepal.Length))
`
**Output:
Mean Sepal Length: 5.843333
Median Sepal Length: 5.8
Mode Sepal Length: 5
Measures of Dispersion
To understand the spread of the data, we calculate the variance, standard deviation, range and interquartile range (IQR).
- **var(): Computes the variance, indicating data spread.
- **sd(): Computes the standard deviation, showing variation extent.
- **range(): Finds the minimum and maximum values.
- **IQR(): Calculates the interquartile range (spread between 25th and 75th percentiles). R `
cat("\n Variance: ", var(iris$Sepal.Length)) cat("\n Standard Deviation: ", sd(iris$Sepal.Length)) cat("\n Range: ", range(iris$Sepal.Length)) cat("\n Interquartile Range (IQR): ", IQR(iris$Sepal.Length))
`
**Output:
Variance: 0.6856935
Standard Deviation: 0.8280661
Range: 4.3 7.9
Interquartile Range (IQR): 1.3
Correlation
Next, we examine the relationships between numerical variables by computing the correlation matrix.
- **cor(): Computes the correlation matrix for a set of numeric variables, showing relationships between them. R `
cor(iris[, 1:4])
`
**Output:
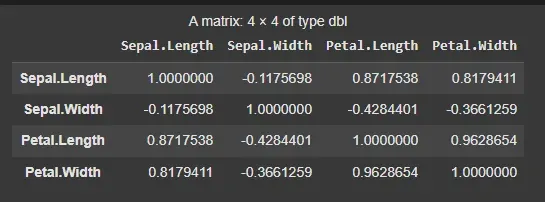
Correlation
Graphical Methods for EDA
Graphical methods involve visualizing the data using plots such as histograms, box plots, scatter plots and bar charts. These visualizations help in identifying patterns, trends, outliers and the distribution of data, making it easier to interpret and communicate insights. We will use the ggplot2 package for this purpose.
Distribution Histograms and Density Plots
We begin by plotting histograms to visualize the distribution of variables like Sepal Length.
- **ggplot(): Initializes a plot object in ggplot2, taking data and aesthetic mappings.
- **geom_histogram(): Creates a histogram to visualize the distribution of a variable. R `
install.packages("ggplot2") library(ggplot2)
ggplot(iris, aes(x = Sepal.Length)) + geom_histogram(binwidth = 0.2, fill = "blue", color = "white", alpha = 0.7) + labs(title = "Histogram of Sepal Length", x = "Sepal Length", y = "Frequency") + theme_minimal()
`
**Output:
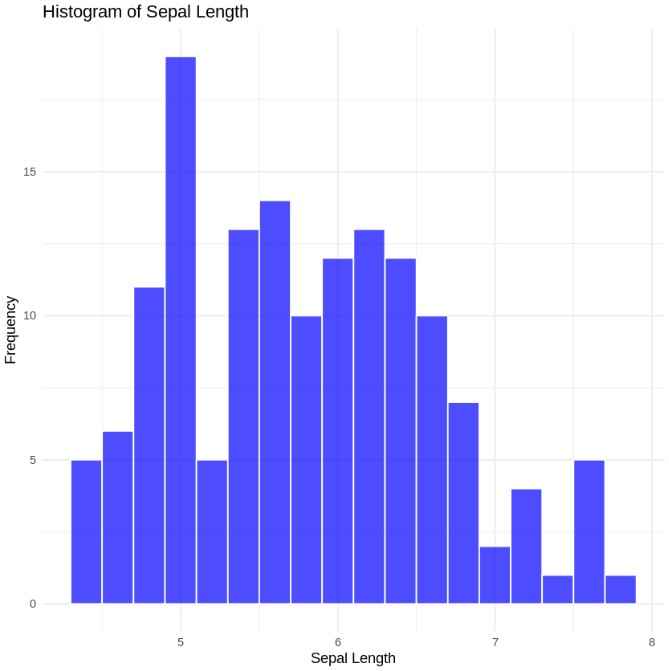
Histogram
Next, we can plot the density curve for Sepal Length:
- **geom_density(): Plots a smooth curve (kernel density estimate) to show the distribution of a continuous variable. R `
ggplot(iris, aes(x = Sepal.Length)) + geom_density(fill = "blue", alpha = 0.7) + labs(title = "Density Curve for Sepal Length", x = "Sepal Length", y = "Density") + theme_minimal()
`
**Output:
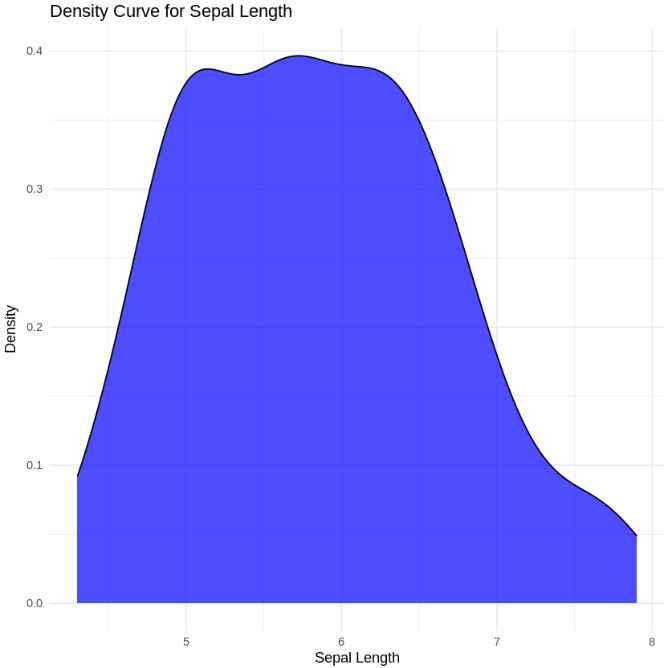
Density Plot
Box Plot
A box plot is useful to visualize the spread and potential outliers in the data.
- **geom_boxplot(): Generates a boxplot to show the distribution and detect outliers. R `
ggplot(iris, aes(x = Species, y = Sepal.Length, fill = Species)) + geom_boxplot() + labs(title = "Box Plot of Sepal Length by Species", x = "Species", y = "Sepal Length") + theme_minimal()
`
**Output:
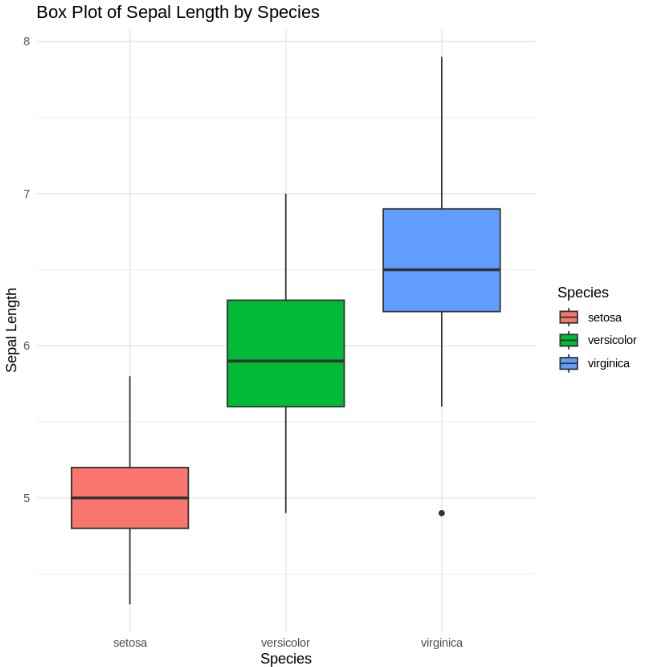
Boxplot
Scatter Plot
We can also examine the relationships between two numerical variables with scatter plots. For example, we’ll plot Sepal Length against Sepal Width.
- **geom_point(): Creates a scatter plot to show the relationship between two variables. R `
ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point() + labs(title = "Scatter Plot of Sepal Length vs Sepal Width", x = "Sepal Length", y = "Sepal Width") + theme_minimal()
`
**Output:
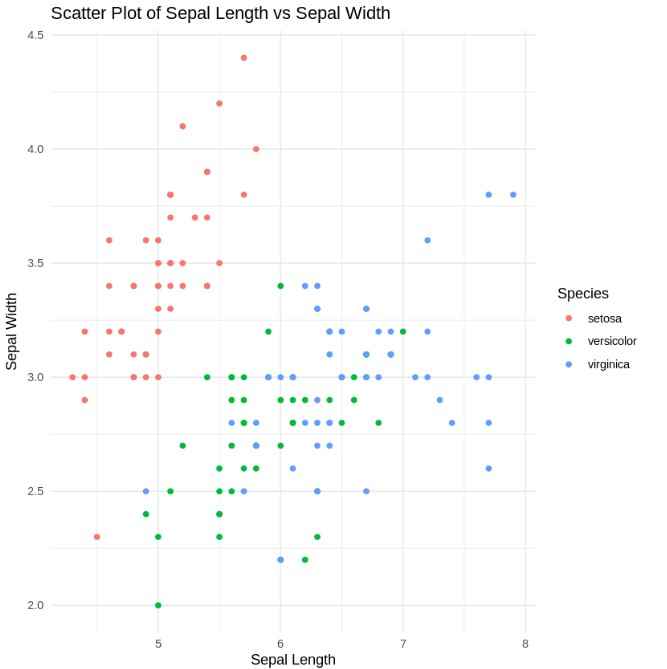
Scatterplot
Pairwise Plot
For more comprehensive visualization, a pairwise scatter plot (or pairs plot) can help us see all pairwise relationships between the numerical variables in the dataset.
- **pairs(): Creates a scatterplot matrix to visualize pairwise relationships between multiple variables
- **pch: Symbol used in the scatterplots (e.g., 1 for circles)
- **col: Color of points in the scatterplots R `
pairs(iris[, 1:4], col = iris$Species, pch = 21)
`
**Output:
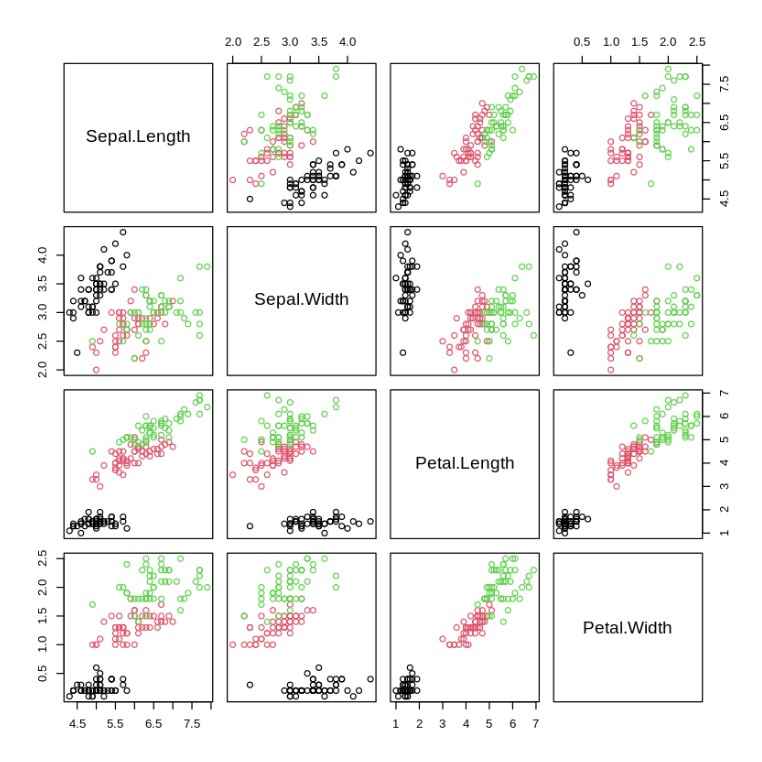
Pairwise Plot
You can download the source code from here.