Repeated Kfold Cross Validation in R Programming (original) (raw)
Last Updated : 7 Jul, 2025
Repeated K-Fold Cross-Validation is a method used to evaluate machine learning models for both classification and regression tasks. It involves splitting the dataset into K equal parts, training the model on K−1 parts and testing it on the remaining part. This process is repeated K times so that each part is used once as a test set. The entire K-Fold process is then repeated multiple times with different random splits of the data. This helps provide a more reliable and consistent estimate of the model’s performance by reducing the impact of any single data split.
Steps in Repeated K-Fold Cross-Validation
- Randomly split the dataset into K equal subsets.
- Select one subset as the validation set.
- Use the remaining K−1 subsets to train the model.
- Evaluate the model on the validation set and calculate prediction error.
- Repeat steps 2–4 until each subset has been used once as the validation set.
- Calculate the average of all K prediction errors.
- Repeat steps 1–6 for a fixed number of repetitions with a new random split each time.
- Calculate the final model performance as the average of all repetition results.
Implementation of Repeated K-Fold Cross-Validation on Classification
We build and evaluate a classification model using the repeated K-Fold cross-validation method in R with the Naive Bayes algorithm.
1. Installing and loading the required packages and libraries
We install and then load the necessary libraries to handle data, import datasets and perform repeated K-Fold cross-validation.
- **install.packages("tidyverse"): installs the package for data manipulation and visualization.
- **install.packages("caret"): installs the package for training and evaluating models.
- **install.packages("ISLR"): installs the package containing the Smarket dataset.
- **library(tidyverse): loads the tidyverse package.
- **library(caret): loads the caret package.
- **library(ISLR): loads the ISLR package. R `
install.packages("tidyverse") install.packages("caret") install.packages("ISLR")
library(tidyverse) library(caret) library(ISLR)
`
2. Exploring the dataset
We assign the dataset to a variable and check its structure to ensure it is ready for training.
- **Smarket: built-in dataset containing stock market data.
- **complete.cases(): used to remove missing values.
- **glimpse(): used to display structure and data types.
- **table(): used to check class distribution in the target variable. R `
dataset <- Smarket[complete.cases(Smarket), ] glimpse(dataset) table(dataset$Direction)
`
**Output:
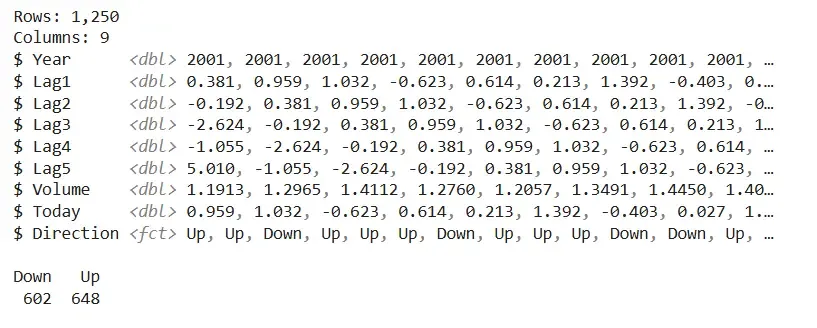
Output
3. Building the model with repeated K-Fold algorithm
We set up repeated K-Fold cross-validation and build a Naive Bayes model.
- **set.seed(): used to make results reproducible.
- **trainControl(): used to define method, number of folds and repeats.
- **train(): used to train the model with specified method and control. R `
set.seed(123) train_control <- trainControl(method = "repeatedcv", number = 10, repeats = 3) model <- train(Direction~., data = dataset, trControl = train_control, method = "nb")
`
4. Evaluating the accuracy of the model
We print the model summary to evaluate performance based on prediction error across folds.
- **print(): used to display the model performance and best parameters. R `
print(model)
`
**Output:

Output
Implementation of Repeated K-fold Cross-validation on Regression
We implement the repeated k-fold cross-validation technique on a regression model using R's inbuilt trees dataset. This method improves the robustness of model evaluation by running k-fold cross-validation multiple times with different random splits.
1. Installing Required Packages
We install the required packages for data manipulation and cross-validation.
- **tidyverse: Used to perform data manipulation and visualization.
- **caret: Used to compute cross-validation methods. R `
library(tidyverse) library(caret)
`
2. Loading and Inspecting the Dataset
We load the inbuilt trees dataset and inspect the first few records.
- **data(trees): Loads the dataset into memory.
- **head(trees): Displays the first few rows to understand the structure. R `
data(trees) head(trees)
`
**Output:
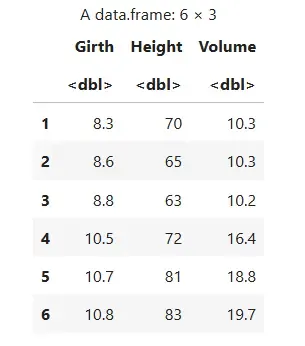
Output
3. Building the Model using Repeated K-fold Algorithm
We set the seed for reproducibility and define the control parameters for cross-validation.
- **set.seed(): Ensures reproducibility of the random sampling.
- **trainControl(): Defines the method as repeated cross-validation with 10 folds and 3 repeats.
- **train(): Trains a linear regression model using the defined control settings. R `
set.seed(125) train_control <- trainControl(method = "repeatedcv", number = 10, repeats = 3) model <- train(Volume ~., data = trees, method = "lm", trControl = train_control)
`
4. Evaluating the Accuracy of the Model
We print the model's performance metrics and cross-validation summary.
- **print(): Displays RMSE, R² and MAE for model evaluation. R `
print(model)
`
**Output:
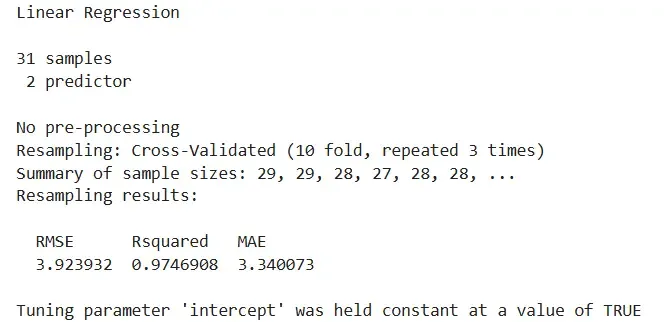
Output
Advantages of Repeated K-fold cross-validation
- A very effective method to estimate the prediction error and the accuracy of a model.
- In each repetition, the data sample is shuffled which results in developing different splits of the sample data.
Disadvantages of Repeated K-fold cross-validation
- A lower value of K leads to a biased model and a higher value of K can lead to variability in the performance metrics of the model. Thus, it is essential to use the correct value of K for the model(generally K = 5 and K = 10 is desirable).
- With each repetition, the algorithm has to train the model from scratch which means the computation time to evaluate the model increases by the times of repetition.