Random Forest Algorithm in Machine Learning (original) (raw)
Last Updated : 30 May, 2025
Random Forest is a machine learning algorithm that uses many decision trees to make better predictions. Each tree looks at different random parts of the data and their results are combined by voting for classification or averaging for regression. This helps in improving accuracy and reducing errors.
Working of Random Forest Algorithm
- **Create Many Decision Trees: The algorithm makes many decision trees each using a random part of the data. So every tree is a bit different.
- **Pick Random Features: When building each tree it doesn’t look at all the features (columns) at once. It picks a few at random to decide how to split the data. This helps the trees stay different from each other.
- **Each Tree Makes a Prediction: Every tree gives its own answer or prediction based on what it learned from its part of the data.
- **Combine the Predictions:
- For **classification we choose a category as the final answer is the one that most trees agree on i.e majority voting.
- For **regression we predict a number as the final answer is the average of all the trees predictions.
- **Why It Works Well: Using random data and features for each tree helps avoid overfitting and makes the overall prediction more accurate and trustworthy.
Random forest is also a ensemble learning technique which you can learn more about from: Ensemble Learning
**Key Features of Random Forest
- **Handles Missing Data: It can work even if some data is missing so you don’t always need to fill in the gaps yourself.
- **Shows Feature Importance: It tells you which features (columns) are most useful for making predictions which helps you understand your data better.
- **Works Well with Big and Complex Data: It can handle large datasets with many features without slowing down or losing accuracy.
- **Used for Different Tasks: You can use it for both **classification like predicting types or labels and **regression like predicting numbers or amounts.
Assumptions of Random Forest
- **Each tree makes its own decisions: Every tree in the forest makes its own predictions without relying on others.
- **Random parts of the data are used: Each tree is built using random samples and features to reduce mistakes.
- **Enough data is needed: Sufficient data ensures the trees are different and learn unique patterns and variety.
- **Different predictions improve accuracy: Combining the predictions from different trees leads to a more accurate final result.
Implementing Random Forest for Classification Tasks
Here we will predict survival rate of a person in titanic.
- Import libraries and load the Titanic dataset.
- Remove rows with missing target values ('Survived').
- Select features like class, sex, age, etc and convert 'Sex' to numbers.
- Fill missing age values with the median.
- Split the data into training and testing sets, then train a Random Forest model.
- Predict on test data, check accuracy and print a sample prediction result. Python `
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report import warnings warnings.filterwarnings('ignore')
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv" titanic_data = pd.read_csv(url)
titanic_data = titanic_data.dropna(subset=['Survived'])
X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']] y = titanic_data['Survived']
X.loc[:, 'Sex'] = X['Sex'].map({'female': 0, 'male': 1})
X.loc[:, 'Age'].fillna(X['Age'].median(), inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
y_pred = rf_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred) classification_rep = classification_report(y_test, y_pred)
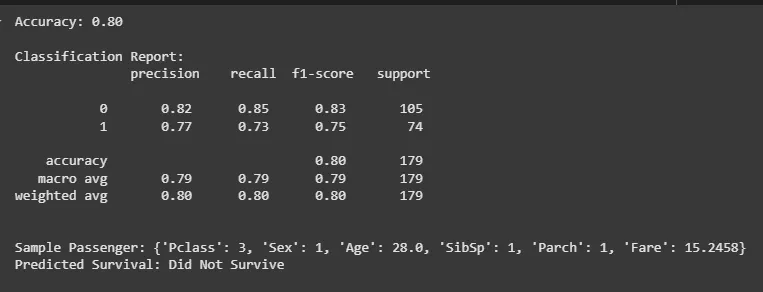
print(f"Accuracy: {accuracy:.2f}") print("\nClassification Report:\n", classification_rep)
sample = X_test.iloc[0:1] prediction = rf_classifier.predict(sample)
sample_dict = sample.iloc[0].to_dict() print(f"\nSample Passenger: {sample_dict}") print(f"Predicted Survival: {'Survived' if prediction[0] == 1 else 'Did Not Survive'}")
`
**Output:
Random Forest for Classification Tasks
We evaluated model's performance using a classification report to see how well it predicts the outcomes and used a random sample to check model prediction.
Implementing Random Forest for Regression Tasks
We will do house price prediction here.
- Load the California housing dataset and create a DataFrame with features and target.
- Separate the features and the target variable.
- Split the data into training and testing sets (80% train, 20% test).
- Initialize and train a Random Forest Regressor using the training data.
- Predict house values on test data and evaluate using MSE and R² score.
- Print a sample prediction and compare it with the actual value. Python `
import pandas as pd from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score
california_housing = fetch_california_housing() california_data = pd.DataFrame(california_housing.data, columns=california_housing.feature_names) california_data['MEDV'] = california_housing.target
X = california_data.drop('MEDV', axis=1) y = california_data['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
rf_regressor.fit(X_train, y_train)
y_pred = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred) r2 = r2_score(y_test, y_pred)
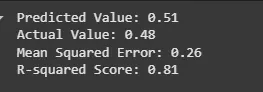
single_data = X_test.iloc[0].values.reshape(1, -1) predicted_value = rf_regressor.predict(single_data) print(f"Predicted Value: {predicted_value[0]:.2f}") print(f"Actual Value: {y_test.iloc[0]:.2f}")
print(f"Mean Squared Error: {mse:.2f}") print(f"R-squared Score: {r2:.2f}")
`
**Output:
Random Forest for Regression Tasks
We evaluated the model's performance using Mean Squared Error and R-squared Score which show how accurate the predictions are and used a random sample to check model prediction.
Advantages of Random Forest
- Random Forest provides very accurate predictions even with large datasets.
- Random Forest can handle missing data well without compromising with accuracy.
- It doesn’t require normalization or standardization on dataset.
- When we combine multiple decision trees it reduces the risk of overfitting of the model.
Limitations of Random Forest
- It can be computationally expensive especially with a large number of trees.
- It’s harder to interpret the model compared to simpler models like decision trees.