Introduction of Holdout Method (original) (raw)
Last Updated : 17 Sep, 2025
The Holdout Method is a fundamental validation technique in machine learning used to evaluate the performance of a predictive model. In this method, the available dataset is split into two mutually exclusive subsets:
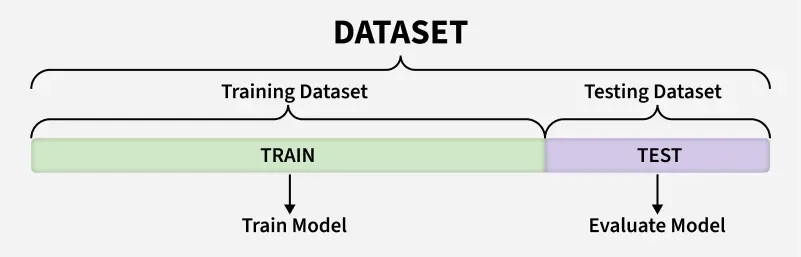
Visualizing Holdout Method
- The dataset is commonly divided into training set and test set.
- Typical split ratios include 70:30, 80:20 or 60:40 depending on dataset size.
- A larger training set helps the model learn better patterns.
- A larger test set provides a more reliable estimate of performance.
- The holdout method is a form of cross-validation but simpler and faster.
- It is most effective when the dataset is large enough to allow meaningful splitting.
- Random shuffling before splitting is often applied to reduce bias.
This ensures that the model’s evaluation is unbiased and gives an estimate of how well it will generalize to new data.
Working of Holdout Method
The holdout method works by creating separate partitions of data that ensure training and evaluation are performed independently.
- The training set is used to fit the model.
- The test set is used to evaluate performance metrics such as accuracy, precision, recall or RMSE.
- The model is never tested on the same data it was trained on to check its accuracy.
- Performance results approximate how the model will behave on real-world unseen data.
- Sometimes a validation set is introduced to tune hyperparameters before the final test.
Let's see an example:
Here we will use scikit learn library.
- **Dataset: We will use Iris dataset which is a standard classification dataset.
- **train_test_split: Divides data into 80% training and 20% testing.
- **DecisionTreeClassifier: We will see the decision tree model for demonstration.
- **Accuracy & Report: Shows how well the model performs on unseen data. Python `
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score, classification_report
iris = load_iris() X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, shuffle=True )
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy on Test Set:", accuracy) print("\nClassification Report:\n", classification_report( y_test, y_pred, target_names=iris.target_names))
`
**Output:
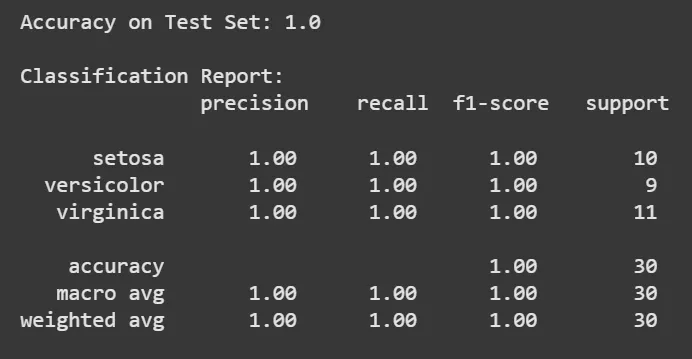
Output
Application
- **Fraud Detection in Banking: Evaluating models that identify fraudulent transactions using past transaction data.
- **Medical Diagnosis Systems: Validating models that predict diseases based on patient health records.
- **Spam Email Classification: Testing classifiers that separate spam from genuine emails.
- **Customer Churn Prediction: Measuring accuracy of models that forecast which customers may leave a service.
- **Recommendation Systems: Assessing product or content recommendation models in e-commerce and streaming platforms.
Advantages
- **Simplicity: Easy to understand and implement without complex procedures.
- **Speed: Computationally efficient since the dataset is split only once.
- **Unbiased Evaluation: Ensures test data remains unseen during training.
- **Scalability: Works effectively with very large datasets.
- **Flexibility: Allows adjustable train-test ratios based on dataset size.
Limitations
- **Data Dependency: Performance heavily depends on how the dataset is split.
- **Variance in Results: Different splits may give different accuracy scores.
- **Data Waste in Small Sets: Not all data is used for training, reducing learning capacity.
- **Class Imbalance Sensitivity: Risk of uneven class distribution between train and test sets.
- **Less Reliable for Small Data: Cross-validation often outperforms holdout in limited data scenarios.