SQL Count() Function (original) (raw)
In the world of SQL, **data analysis often requires us to get counts of rows or unique values. The **COUNT() function is a **powerful tool that helps us perform this task. Whether we are counting all rows in a table, counting rows based on a specific condition, or even counting unique values, the **COUNT() function is essential for summarizing data.
In this article, we will cover the **COUNT() function in detail, including its **syntax, **examples, and **different use cases such as counting rows with conditions and using it with **GROUP BY and **HAVING.
**What is the SQL COUNT() Function?
The COUNT() function in SQL is an aggregate function that returns the number of rows that match a specified condition in a query. It can count all rows in a table, **count distinct values in a column, or count rows based on certain criteria. It is often used in reporting and analysis to aggregate data and retrieve valuable insights. The **COUNT() function is often used in **reporting, **analytics, and **business intelligence queries to summarize large datasets, helping us draw conclusions from them.
**Syntax
COUNT(expression)
- Count all rows:
SELECT COUNT(*) FROM table_name;
**2. Count distinct values in a column:
SELECT COUNT(DISTINCT column_name) FROM table_name;
**Key Terms
- **expression: This can be a column name, an asterisk (*), or a condition.
- **COUNT(*): Counts all rows.
- **COUNT(DISTINCT column_name): Counts distinct values in the specified column.
Examples of SQL Count Function
Now, let’s dive into practical examples of using the **COUNT() function in SQL. We will use a **Customers table as our sample dataset, which contains details about customers, including their **CustomerID, **CustomerName, **City, and **Country.
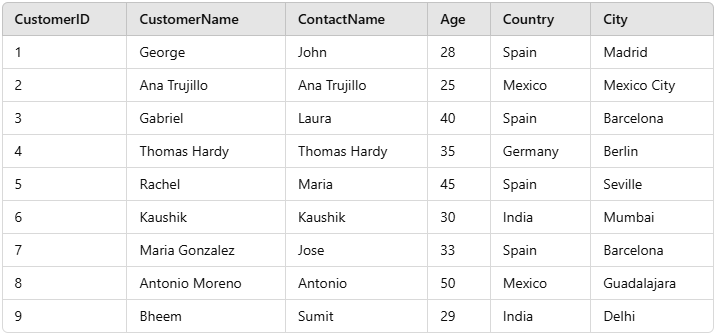
Customers Table
**1. Counting the Number of Rows with COUNT(*)
When we want to count all the rows in a table, regardless of the column values, we can use **COUNT(*). It counts every row, including rows with **NULL values.
**Query:
SELECT COUNT(*)
FROM Customers;
**Output
| COUNT(*) |
|---|
| 9 |
**Explanation:
- This query counts all the rows in the
Customerstable, including those with NULL values in any column. - The result
9indicates that there are 9 rows in theCustomerstable.
**2. Counting Unique Values with COUNT(DISTINCT …)
Sometimes, we may need to count only the **distinct values in a column. The **COUNT(DISTINCT column_name) function allows us to count only unique entries in a column, ignoring duplicates.
**Query:
SELECT COUNT(DISTINCT Country) FROM Customers;
**Output
| COUNT(DISTINCT Country) |
|---|
| 4 |
**Explanation:
- This query counts the number of unique countries in the
Customerstable. - The result
4indicates that there are four distinct countries listed in the table (Spain, Mexico, India, and Germany).
**3. Count Rows That Match a Condition Using COUNT() with CASE WHEN
We can use the **COUNT() function along with **CASE WHEN to count rows that match a specific condition. This is helpful when we want to count rows based on certain criteria without filtering the rows out of the result set.
**Query:
SELECT COUNT(CASE WHEN Age > 30 THEN 1 ELSE NULL END) AS Adults
FROM Customers;
**Output
| Adults |
|---|
| 5 |
**Explanation:
- This query counts the number of customers whose age is greater than 30.
- The **CASE WHEN expression checks if the condition
Age > 30is met. If it is, the value1is returned (otherwise,NULLis returned). - The **COUNT() function then counts the non-NULL values, giving us the total number of customers over 30 years old.
- The result
5shows that five customers are older than 30 years.
**4. Count Rows in Groups Using COUNT() with GROUP BY
We can use the **COUNT() function with GROUP BY to count rows within groups based on a column. This is useful when we want to categorize data and then count how many records exist in each category.
**Query:
SELECT Country, COUNT(*) AS CustomerCount
FROM Customers
GROUP BY Country;
**Output
| Country | CustomerCount |
|---|---|
| Spain | 4 |
| Mexico | 2 |
| India | 2 |
| Germany | 1 |
**Explanation:
- This query groups the rows in the
Customerstable by theCountrycolumn and then counts how many customers belong to each country. - The result shows the number of customers from each country: 4 from Spain, 2 from Mexico, 2 from India, and 1 from Germany
**5. Filter Groups Using COUNT() with GROUP BY and HAVING
We can combine the **COUNT() function with **HAVING to filter the results after grouping. The **HAVING clause is used to specify conditions on groups, similar to the WHERE clause, but for groups.
**Query:
SELECT Country, COUNT() AS CustomerCount
FROM Customers
GROUP BY Country
HAVING COUNT() > 2;
**Output
| Country | CustomerCount |
|---|---|
| Spain | 4 |
**Explanation:
- This query counts the number of customers from each country and filters out countries with fewer than 3 customers.
- The result only includes Spain, as it is the only country with more than 2 customers.
**Best Practices for Using the COUNT() Function
The **COUNT() function is a **powerful and **versatile tool in SQL, but like any tool, it works best when used correctly. To ensure our queries are efficient and maintainable, it's important to follow a few best practices. Below are some key tips to get the most out of the **COUNT() function in SQL:
**1. Use COUNT(*) for Complete Row Counts:
When we need to count every row in a table, including rows with **NULL values, use **COUNT(*). This counts all rows, regardless of the data in them
**Example:
SELECT COUNT(*)
FROM Customers;
**Explanation:
This query will count all rows in the **Customers table, even if some of those rows have **NULL values in their columns. **COUNT(*) is the best choice when we're looking for the total number of records in a table.
**2. Use COUNT(DISTINCT column_name) to Count Unique Values:
If we only need to count the number of unique (distinct) values in a specific column, use **COUNT(DISTINCT column_name). This is useful when we want to know how many different values exist in a column, like counting distinct countries, cities, or customer types.
**Example:
SELECT COUNT(DISTINCT Country)
FROM Customers;
**Explanation:
This query counts how many unique countries are listed in the **Customers table, excluding any duplicates. Using **COUNT(DISTINCT) ensures that only distinct values are counted, which is helpful for analyzing unique data points.
**3. Optimize Queries for Large Datasets:
When we're working with large datasets, **COUNT() can become slow if the query scans the entire table. To improve performance, ensure that the columns you're querying are properly indexed. Indexing can significantly speed up the counting process by allowing the database to quickly locate and retrieve the necessary data.
**Example:
If we frequently count values in the **Country column, consider adding an index to the **Country column:
CREATE INDEX idx_country
ON Customers(Country);
**Explanation:
By creating an index on the **Country column, you reduce the time the database takes to count the rows matching certain conditions, especially on large tables with millions of rows
**4. Avoid Complex COUNT Queries for Large Tables:
When dealing with very large tables, complex **COUNT() queries involving multiple conditions or subqueries can take a long time to execute. It's often better to break the query down into smaller, more manageable parts. This **reduces the load on the database and can help **improve performance.
**Example:
SELECT COUNT(*)
FROM Customers
WHERE (Country = 'Spain' OR Country = 'France')
AND Age > 30
AND City = 'Barcelona';
**Explanation:
By breaking the query into smaller parts, the database only needs to process smaller datasets at a time, reducing the overall processing time.
**Conclusion
The **COUNT() function is an essential tool in SQL for aggregating data. It allows us to count rows, count unique values, and filter based on specific conditions. Whether we’re working with **COUNT() in a SELECT statement or using it with **GROUP BY or HAVING to aggregate data, this function is crucial for **data analysis and reporting. By following best practices like indexing and breaking down complex queries, we can optimize our **COUNT() function usage to ensure high performance and accurate results.