CQRS Command Query Responsibility Segregation Design Pattern (original) (raw)
Last Updated : 13 May, 2026
Command Query Responsibility Segregation (CQRS) is an architectural pattern that improves scalability and performance by separating read and write operations into distinct models. Instead of using a single model to both retrieve and modify data, CQRS divides responsibilities into two parts:
- Commands, which handle state-changing operations such as insert, update, and delete.
- Queries, which retrieve data without modifying the system state.
This separation allows the write side to focus on enforcing business rules and maintaining consistency, while the read side can be optimized for fast data access. As applications grow in complexity and scale, this division helps improve flexibility and system performance.
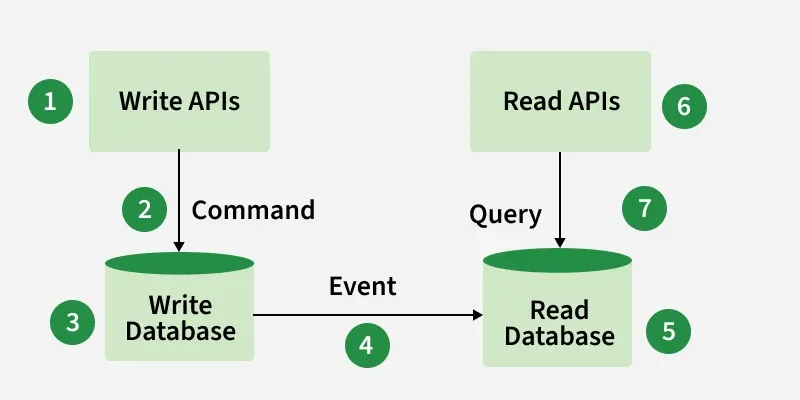
- Write operations update the write database, which acts as the source of truth.
- Changes are propagated-often through events-to update the read database.
- Queries retrieve data exclusively from the read database, ensuring clear separation between data modification and data retrieval.
Detailed Architecture of CQRS
To understand how CQRS is implemented in real-world systems, the following diagram illustrates a structured service-level architecture.
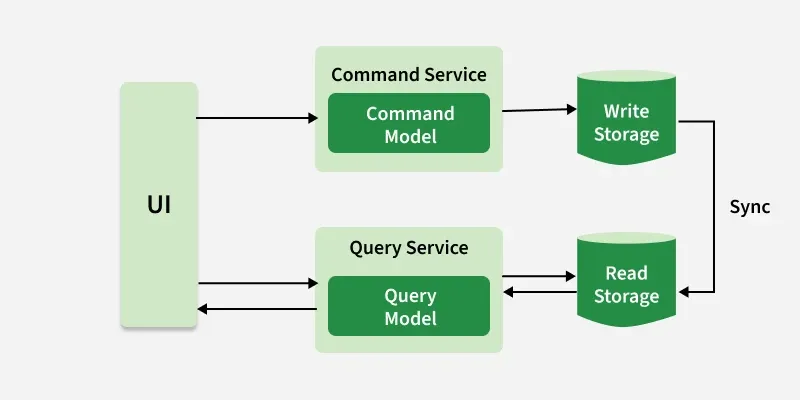
In a structured implementation, CQRS is realized using separate services and storage layers:
- **UI (User Interface): Sends commands for write operations and queries for read operations.
- **Command Service (Command Model): Processes commands, applies business logic, and updates the write storage.
- **Write Storage: Acts as the source of truth and stores authoritative data.
- **Synchronization Mechanism: Propagates changes from write storage to read storage, often using events.
- **Read Storage: Maintains a read-optimized view of the data for fast retrieval.
- **Query Service (Query Model): Handles read-only requests and fetches data from read storage.
This architecture enables independent scaling of read and write components, improving system flexibility and supporting high-load applications.
Limitations of Traditional Architectures and Solution by CQRS
Traditional architectures often face challenges in handling high loads and managing complex data requirements. In these systems, the same model is used for both reading (fetching data) and writing (updating data), which can lead to performance issues. As the application grows, handling large read and write requests together becomes harder, creating bottlenecks and slowing down responses.
CQRS addresses this by allowing read and write workloads to scale and evolve independently.
- As a result, CQRS allows systems to handle higher traffic efficiently, improves performance, and simplifies scaling by allowing independent optimization of read and write parts.
Relationship between CQS and CQRS
Command Query Separation (CQS) and CQRS are related in that CQRS extends upon the fundamental concept of CQS. To put it simply, this is how they are related:
- **CQS: It is a programming principle that says you should separate operations that change data (commands) from those that read data (queries). If you have a method, for instance, it should either return something or update something, but not both.
- **CQRS: By dividing the design of the entire system into two sections—one for managing commands (writing or modifying data) and another for managing queries (reading data), CQRS expands on this idea. Each side can have its own database or model to optimize how they work.
So, CQS is the basic rule, and CQRS is like an advanced version of it used for bigger systems where you want to handle reading and writing differently.
Uses
You should use the CQRS design pattern when your application has different types of operations—like when reading data is very frequent and writing data is complex or infrequent.
- **Handling complex queries: If your application needs to perform complicated read operations (queries), separating the read and write sides can optimize performance.
- **Scalability: When you need to scale reading and writing operations independently, CQRS allows you to optimize each side separately for better scalability.
- **Event-driven systems: In systems where changes trigger events, CQRS works well with event sourcing to handle complex workflows.
- **When data models differ: If the way you store data for writing is different from how it should be optimized for reading, CQRS helps by keeping separate models.
CQRS is most suitable for systems with high read/write imbalance, complex business logic, or strong scalability requirements.
Database Synchronization in CQRS
Synchronizing databases in a system that follows the CQRS pattern can be challenging due to the separation of the write and read sides of the application.
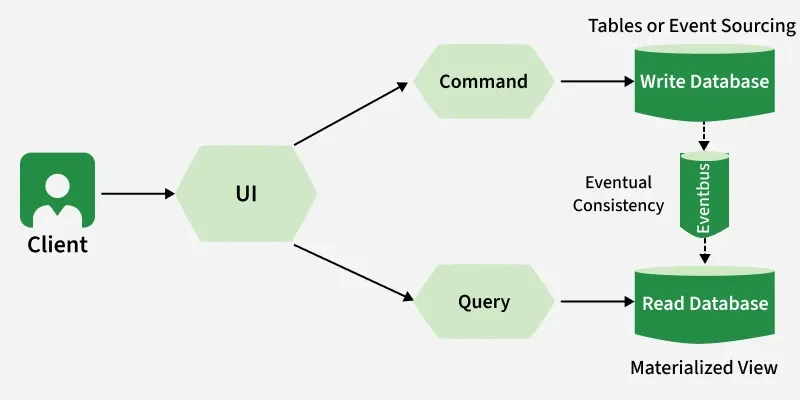
- **Step 1: Write to the Command Database: When you make changes (create, update, delete), they are first saved in the command database. This database is optimized for handling write operations.
- **Step 2: Generate Events: After the write operation is successful, the system generates events that describe what changed (like "Order Created" or "User Updated"). These events serve as notifications about the updates.
- **Step 3: Update the Query Database: The read database, optimized for fast queries, listens for these events and applies the changes to its own copy of the data. This way, the query database gets updated with the latest information.
- **Step 4: Eventual Consistency: The key idea is that the query database doesn’t have to update immediately. There can be a slight delay, but eventually, both databases will sync, ensuring consistency over time.
This approach ensures that the systems are synchronized, with the command side focusing on data integrity and the query side on performance.
Example
In our E-commerce microservices architecture, we're introducing a new approach to database design using the CQRS pattern. We've decided to split our databases into two separate parts to better manage our data and improve performance.
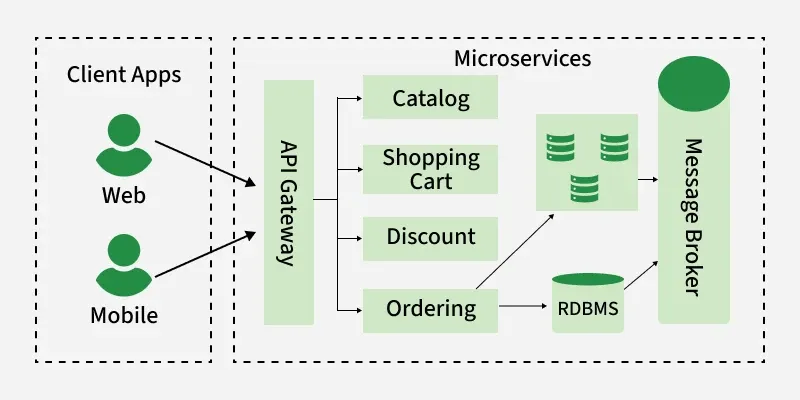
- Firstly, we'll have a write database that focuses on handling all write operations, such as creating and updating orders.
- This database will be optimized for transactional consistency and relational data modeling, making it suitable for managing the core data changes.
- Secondly, we'll introduce a read database dedicated to handling read operations, such as querying for order details and order history.
- This database will be designed for high performance and scalability, using a NoSQL database like MongoDB or Cassandra.
Event Sourcing and CQRS
Event Sourcing andCQRS are often used together in systems that require high scalability, traceability, and complex business logic.
- Event Sourcing stores every state change as an immutable event instead of persisting only the latest state. For example, rather than updating a user’s balance directly, each transaction (such as “Deposit 100” or “Withdraw 50”) is recorded as a separate event. The current state is reconstructed by replaying these events.
- When combined with CQRS, the command side records events as the source of truth, while the query side builds optimized read models based on those events. This separation enables high performance on reads while maintaining strong consistency and traceability on writes.
Together, Event Sourcing and CQRS provide traceability on the write side and optimized read models for performance-critical queries.
Challenges
The challenges of using CQRS Design Pattern are:
- **Complexity: Your system may become more complex if you use CQRS, particularly if you are unfamiliar with the pattern. It can be difficult to coordinate data synchronization, manage distinct read and write models, and guarantee consistency between the two.
- **Consistency: Maintaining consistency between the read and write models can be challenging, especially in distributed systems where data updates may not propagate immediately. Careful planning and execution are necessary to guarantee stability over time without compromising scalability or performance.
- **Data Synchronization: It might be difficult to keep the read and write models in sync, particularly when handling complicated data transformations or big data sets. Message queues or event streams are commonly used to handle synchronization.
- **Performance Overhead: Implementing CQRS can introduce performance overhead, especially if not done carefully. For example, using event sourcing for the write model can impact write performance, while keeping the read model updated in real-time can impact read performance.
- **Operational Complexity: Operational complexity may rise while managing two databases or data storage (one for read and one for write). This covers duties including monitoring, backup and restoration, and guaranteeing data durability and high availability.
Best Practices for implementing CQRS pattern
Below are some of the best practices for implementing CQRS pattern:
- **Separate Read and Write Models Carefully: Clearly divide the system into models for reading data (queries) and writing data (commands). This separation helps keep each model simple and optimized for its specific task.
- **Use Asynchronous Communication When Needed: Since commands and queries are separated, consider using asynchronous messaging for commands. This helps the system stay responsive and handle high traffic efficiently, even if some operations take longer.
- **Keep Commands and Queries as Simple as Possible: Design commands to focus only on changing data (like “CreateOrder” or “UpdateUser”) and queries only on retrieving data (like “GetOrderDetails”). Avoid mixing read and write logic in either part to keep things clean and maintainable.
- **Embrace Event Sourcing for Data Consistency: Event sourcing can be paired with CQRS to keep a record of all changes. Each change is saved as an event, and the current state is rebuilt from these events. This can make it easier to track history, recover data, or audit changes.
- **Consider the Complexity of Your System: CQRS adds some complexity, so it’s best suited for systems with high read and write demands or complex business rules. For simpler systems, CQRS might be overkill and add unnecessary development overhead.