How to Design a Rate Limiter API | Learn System Design (original) (raw)
Last Updated : 28 Mar, 2026
A Rate Limiter API controls how many requests a user or system can make within a specific time period. It helps protect servers from overload by restricting excessive traffic and ensuring fair usage. It is commonly used in APIs, login systems, and payment services to maintain stability and performance.
- Prevents server overload by limiting request rate
- Ensures fair usage among users
- Protects against abuse like DDoS attacks
**Example: A login API allows only 5 requests per minute per user. If a user exceeds this limit, further requests are blocked temporarily.
1. Use of rate limiting
- Avoid resource starvation due to a Denial of Service (DoS) attack.
- Ensure that servers are not overburdened. Using rate restriction per user
- ensures fair and reasonable use without harming other users.
- Control the flow of information, for example, prevent a single worker from
- accumulating a backlog of unprocessed items while other workers are idle.
2. System Requirements
The requirements of a rate limiter API can be classified into two categories: functional and non-functional.
Functional requirements
This section defines the core capabilities of the Rate Limiter API.
- The API should allow the definition of multiple rate-limiting rules.
- The API should provide the ability to customize the response to clients when rate limits are exceeded.
- The API should allow for the storage and retrieval of rate-limit data.
- The API should be implemented with proper error handling as in when the threshold limit of requests are crossed for a single server or across different combinations, the client should get a proper error message.
Non-functional requirements
This section defines system qualities like performance, scalability, and security.
- The API should be highly available and scalable. Availability is the main pillar in the case of request fetching APIs.
- The API should be secure and protected against malicious attacks.
- The API should be easy to integrate with existing systems.
- There should be low latency provided by the rate limiter to the system, as performance is one of the key factors in the case of any system.
3. High Level Design (HLD)
Placement of Rate Limiter in System Design
A rate limiter should generally be implemented on the server side rather than on the client side. This is because of the following points:
- **Positional Advantage: The server is in a better position to enforce rate limits across all clients, whereas client-side rate limiting would require every client to implement their own rate limiter, which would be difficult to coordinate and enforce consistently.
- **Security: Implementing rate limiting on the server side also provides better security, as it allows the server to prevent malicious clients from overwhelming the system with a large number of requests. If rate limiting were implemented on the client side, it would be easier for attackers to bypass the rate limit by just modifying or disabling the client-side code.
- **Flexible: Server-side rate limiting allows more flexibility in adjusting the rate limits and managing resources. The server can dynamically adjust the rate limits based on traffic patterns and resource availability, and can also prioritize certain types of requests or clients over others. Thus, lends to better utilization of available resources, and also keeps performance good.

HLD of Rate Limiter API - rate limiter placed at server side
The overall basic structure of a rate limiter seems relatively simpler. We just need a counter associated with each user to track how many requests are being same submitted in a particular timeframe. The request is rejected if the counter value hits the limit.
4. Memory Structure/Approximation
Thus, now let's think of the data structure which might help us. Since we need fast retrieval of the counter values associated with each user, we can use a hash-table. Considering we have a key-value pair. The key would contain hash value of each User Id, and the corresponding value would be the pair or structure of counter and the startTime, e.g.,
UserId -> {counter, startTime}
Now, each UserId let's say takes 8 bytes(long long) and the counter takes 2 bytes(int), which for now can count to 50k(limit). Now for the time if we store only the minute and seconds, it will also take 2 bytes. So in total, we would need 12 bytes to store each user's data.
Now considering the overhead of 10 bytes for each record in our hash-table, we would be needing to track at least 5 million users at any time(traffic), so the total memory in need would be:
(12+10)bytes*5 million = 110 MB
5. Components
- **Define the rate limiting policy: The first step is to determine the policy for rate limiting. This policy should include the maximum number of requests allowed per unit of time, the time window for measuring requests, and the actions to be taken when a limit is exceeded (e.g., return an error code or delay the request).
- **Store request counts: The rate limiter API should keep track of the number of requests made by each client. One way to do this is to use a database, such as Redis or Cassandra, to store the request counts.
- **Identify the client: The API must identify each client that makes a request. This can be done using a unique identifier such as an IP address or an API key.
- **Handle incoming requests: When a client makes a request, the API should first check if the client has exceeded their request limit within the specified time window. If the limit has been reached, the API can take the action specified in the rate-limiting policy (e.g., return an error code). If the limit has not been reached, the API should update the request count for the client and allow the request to proceed.
- **Set headers: When a request is allowed, the API should set appropriate headers in the response to indicate the remaining number of requests that the client can make within the time window, as well as the time at which the limit will be reset.
- **Expose an endpoint: Finally, the rate limiter API should expose an endpoint for clients to check their current rate limit status. This endpoint can return the number of requests remaining within the time window, as well as the time at which the limit will be reset.
Best Place to Store Counters in Rate
Due to the slowness of Database operations, it is not a smart option for us. This problem can be handled by an in-memory cache such as Redis. It is quick and supports the already implemented time-based expiration technique.
We can rely on two commands being used with in-memory storage,
- **INCR: This is used for increasing the stored counter by 1.
- **EXPIRE: This is used for setting the timeout on the stored counter. This counter is automatically deleted from the storage when the timeout expires.
In this design, client requests pass through a rate limiter middleware, which checks against the configured rate limits. The rate limiter module stores and retrieves rate limit data from a backend storage system. If a client exceeds a rate limit, the rate limiter module returns an appropriate response to the client.
6. Algorithms to Design a Rate Limiter API
Several algorithms are used for rate limiting, including
- The Token bucket,
- Leaky bucket,
- Sliding window logs, and
- Sliding window counters.
Let's discuss each algorithm in detail:
1. Token Bucket
The token bucket algorithm is a simple algorithm that uses a fixed-size token bucket to limit the rate of incoming requests. The token bucket is filled with tokens at a fixed rate, and each request requires a token to be processed. If the bucket is empty, the request is rejected.
The token bucket algorithm can be implemented using the following steps:
- Initialize the token bucket with a fixed number of tokens.
- For each request, remove a token from the bucket.
- If there are no tokens left in the bucket, reject the request.
- Add tokens to the bucket at a fixed rate.
Thus, by allocating a bucket with a predetermined number of tokens for each user, we are successfully limiting the number of requests per user per time unit. When the counter of tokens comes down to 0 for a certain user, we know that he or she has reached the maximum amount of requests in a particular timeframe. The bucket will be auto-refilled whenever the new timeframe starts.

Token bucket example with initial bucket token count of 3 for each user in one minute
2. Leaky Bucket
It is based on the idea that if the average rate at which water is poured exceeds the rate at which the bucket leaks, the bucket will overflow.
The leaky bucket algorithm is similar to the token bucket algorithm, but instead of using a fixed-size token bucket, it uses a leaky bucket that empties at a fixed rate. Each incoming request adds to the bucket's depth, and if the bucket overflows, the request is rejected.
One way to implement this is using a queue, which corresponds to the bucket that will contain the incoming requests. Whenever a new request is made, it is added to the queue's end. If the queue is full at any time, then the additional requests are discarded.
The leaky bucket algorithm can be separated into the following concepts:
- Initialize the leaky bucket with a fixed depth and a rate at which it leaks.
- For each request, add to the bucket's depth.
- If the bucket's depth exceeds its capacity, reject the request.
- Leak the bucket at a fixed rate.

Leaky bucket example with token count per user per minute is 3, which is the queue size.
3. Sliding Window Logs
Another approach to rate limiting is to use sliding window logs. This data structure involves a "window" of fixed size that slides along a timeline of events, storing information about the events that fall within the window at any given time.
The window can be thought of as a buffer of limited size that holds the most recent events or changes that have occurred. As new events or changes occur, they are added to the buffer, and old events that fall outside of the window are removed. This ensures that the buffer stays within its fixed size, and only contains the most recent events.
This rate limitation keeps track of each client's request in a time-stamped log. These logs are normally stored in a time-sorted hash set or table.
The sliding window logs algorithm can be implemented using the following steps:
- A time-sorted queue or hash table of timestamps within the time range of the most recent window is maintained for each client making the requests.
- When a certain length of the queue is reached or after a certain number of minutes, whenever a new request comes, a check is done for any timestamps older than the current window time.
- The queue is updated with new timestamp of incoming request and if number of elements in queue does not exceed the authorised count, it is proceeded otherwise an exception is triggered.

Sliding window logs in a timeframe of 1 minute
4. Sliding Window Counters
The sliding window counter algorithm is an optimization over sliding window logs. As we can see in the previous approach, memory usage is high. For example, to manage numerous users or huge window timeframes, all the request timestamps must be kept for a window time, which eventually uses a huge amount of memory. Also, removing numerous timestamps older than a particular timeframe means high complexity of time as well.
To reduce surges of traffic, this algorithm accounts for a weighted value of the previous window's request based on timeframe. If we have a one-minute rate limit, we can record the counter for each second and calculate the sum of all counters in the previous minute whenever we get a new request to determine the throttling limit.
The sliding window counters can be separated into the following concepts:
- Remove all counters which are more than 1 minute old.
- If a request comes which falls in the current bucket, the counter is increased.
- If a request comes when the current bucket has reached it's throat limit, the request is blocked.
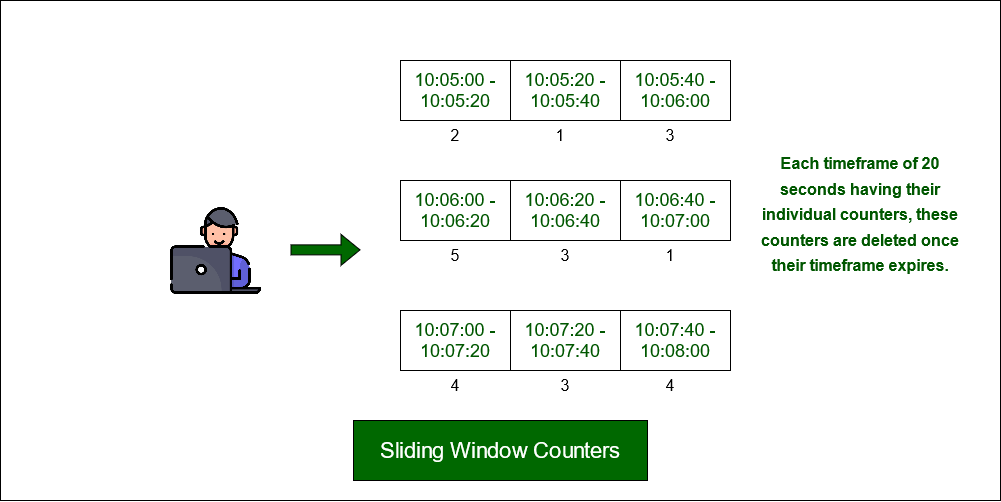
sliding window counters with a timeframe of 20 seconds
7. Examples of Rate Limiting APIs used worldwide
This section highlights commonly used platforms and tools that provide built-in rate limiting features.
- **Google Cloud Endpoints: Provides built-in rate limiting to control API usage and prevent abuse.
- **AWS API Gateway: Uses usage plans and throttling to limit API request rates.
- **Akamai API Gateway: Offers rate limiting to manage and secure API traffic.
- **Cloudflare Rate Limiting: Protects against DDoS and excessive requests by enforcing limits.
- **Redis: Used as a backend store for implementing custom rate limiters with fast in-memory access.