Big O Complexity Cheat Sheet for Coding Interviews (original) (raw)
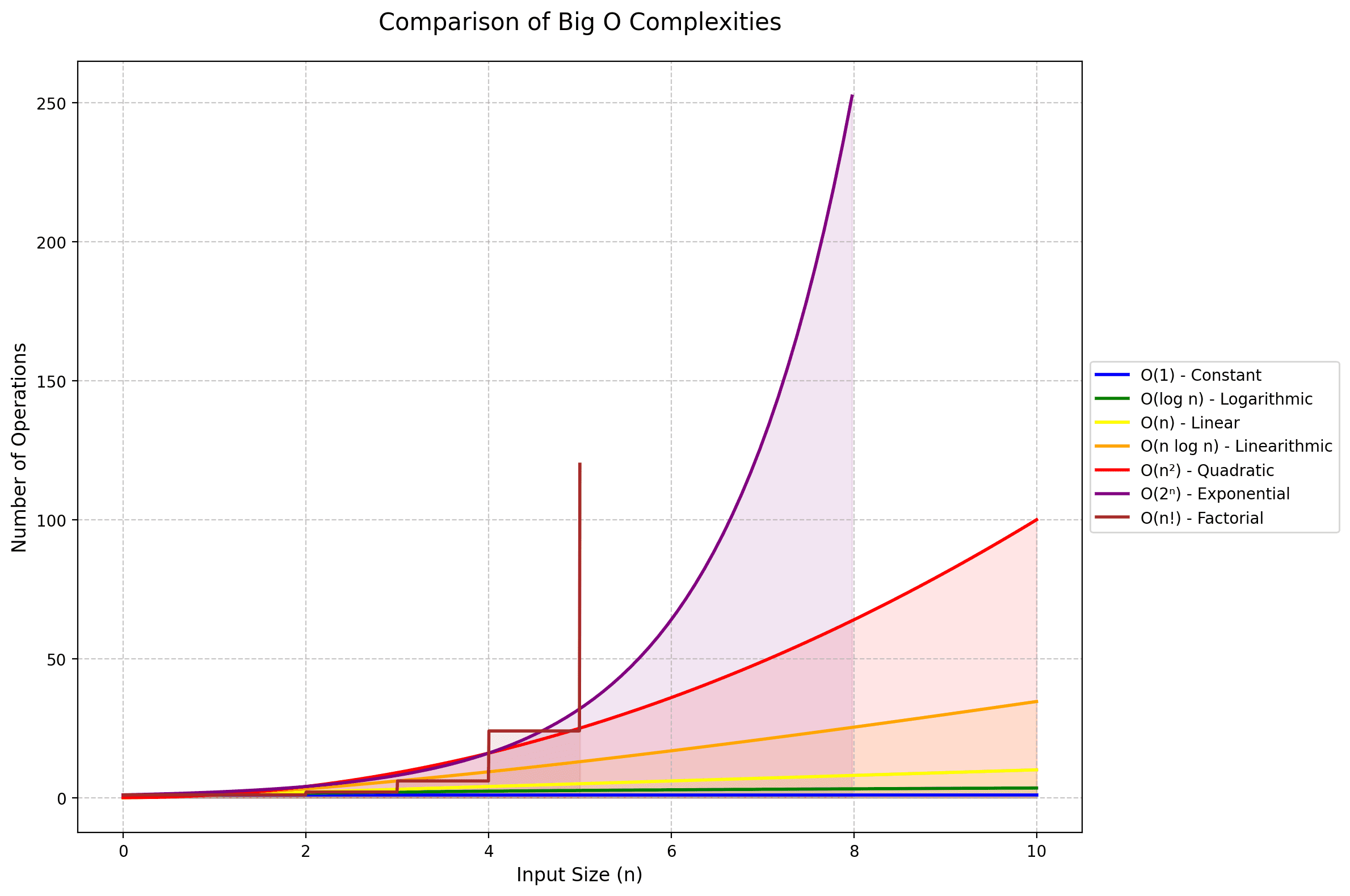
Image by Author | Python & Matplotlib
If you're preparing for coding interviews at tech companies or any software engineering or data role, understanding Big O notation isn't just useful—it's essential. During technical interviews, you'll frequently be asked to analyze the efficiency of your solutions, and you should be able to answer questions like "What's the time complexity of this algorithm?".
But Big O isn't just interview knowledge; it's a fundamental concept you should understand when choosing data structures and designing algorithms. You may be optimizing a database query that needs to scale to millions of users, choosing the right data structure for an application feature, you name it.
Understanding algorithmic complexity, therefore, helps you make informed decisions that can make or break your application's performance. This article will walk you through everything you need to know about Big O notation, from the basics to common algorithmic complexities and where you’ll find them in practice.
▶️ If you’re looking for example code snippets for the common algorithmic complexities in the wild, you can find them on GitHub.
What is Big O?
Big O notation is our way of describing how an algorithm's performance scales with input size. It gives the worst-case runtime complexity of the algorithm. It answers the question: "What happens to the performance when we increase the input size?"
Think of Big O as a way to measure the "rate of growth" of an algorithm. When we write O(n), we're saying the algorithm's resource usage (usually time or space) grows linearly with the input size. We always focus on the worst-case scenario and drop constants because we care about the trend at scale, not the exact numbers.
For example, whether an operation takes 2n or 5n steps, we still call it O(n) because we're interested in the linear growth pattern, not the exact multiplier.
▶️ We’ll focus on time complexity here. But once you understand how Big O works, you should be able to work out space complexity as well. I recommend doing the exercises in the Big O section in Cracking the Coding Interview by Gayle Laakmann McDowell.
O(1) - Constant Time
What it means: The algorithm takes the same amount of time regardless of input size. Whether you're working with 10 items or 10 million items, the operation takes the same time.
Where we find it:
- Hash table insertions and lookups
- Stack push/pop operations
- Array index access
- Mathematical calculations independent of input size
O(log n) - Logarithmic Time
What it means: The processing time increases logarithmically with input size. As the input doubles, the algorithm only needs one more step. This is incredibly efficient for large datasets.
Where we find it:
- Binary search operations
- Balanced binary tree operations (insert/delete)
- Number of digits in a number
- Many divide-and-conquer algorithms
O(n) - Linear Time
What it means: Processing time increases linearly with input size. If you double the input size, the processing time doubles. This is considered an efficient and practical complexity for many real-world problems.
Where we find it:
- Linear search
- Array/list traversal
- String traversal
- Finding min/max in unsorted array
- Counting elements meeting a criterion
O(n log n) - Linearithmic Time
What it means: Combines linear and logarithmic complexity. For each linear iteration (n), you're doing a logarithmic operation (log n). This is often the best possible complexity for sorting algorithms that compare elements.
Where we find it:
- Efficient sorting algorithms (Merge sort, Quicksort average case)
- Certain divide-and-conquer algorithms
- Some tree algorithms
- Finding closest pair of points
O(n²) - Quadratic Time
What it means: Processing time increases with the square of the input size. If you double the input, the processing time increases four-fold. This becomes impractical for large datasets.
Where we find it:
- Nested iterations over data
- Simple sorting algorithms (Bubble sort, Selection sort)
- Comparing all pairs in an array
- Simple graph traversal algorithms
O(2ⁿ) - Exponential Time
What it means: Processing time doubles with each additional input element. Even small increases in input size result in massive increases in processing time. Often indicates a brute force approach.
Where we find it:
- Recursive Fibonacci
- Power set calculation
- Generating all subsets
O(n!) - Factorial Time
What it means: The most dramatic growth rate in our list. Processing time grows by multiplying all positive integers up to n. Even tiny inputs can result in astronomical processing times.
Where we find it:
- Generating all possible permutations
- Solving traveling salesman problem (brute force)
- Finding all possible arrangements of elements
- Generating all possible subsets with ordering
- Solving certain types of puzzles exhaustively
Big-O Complexity Reference Table
| Complexity | Name | Description | Common Use Cases | Performance at Scale |
|---|---|---|---|---|
| O(1) | Constant | Runtime unaffected by input size | Hash tables, array access | Excellent |
| O(log n) | Logarithmic | Runtime increases slowly | Binary search, balanced trees | Very good |
| O(n) | Linear | Runtime scales linearly | Linear search, array traversal | Good |
| O(n log n) | Linearithmic | Between linear and quadratic | Efficient sorting algorithms | Fair |
| O(n²) | Quadratic | Runtime squares with input size | Nested loops, simple sorting | Poor |
| O(2ⁿ) | Exponential | Runtime doubles with each input | Recursive solutions, combinatorics | Very poor |
| O(n!) | Factorial | Runtime grows by factorial | Permutations, traveling salesman | Terrible |
Wrap Up and Best Practices
Understanding Big O notation is more than just interview preparation—it's about writing better, more scalable code. Here are key takeaways to remember:
Always consider the scale:
- For small inputs, even O(n²) algorithms might be fine.
- For large-scale systems, the difference between O(n) and O(n log n) can make all the difference
Interview tips:
- Always mention the time and space complexity of your solution
- Consider discussing trade-offs between different approaches
- Be prepared to optimize your initial solution
- Practice explaining your thinking process while analyzing complexity
Common pitfalls to avoid:
- Don't forget about space complexity
- Watch out for hidden loops in built-in functions
- Remember that average case and worst case can be different
- Consider the practical constraints of your specific use case
Remember: Your goal isn't to write the most efficient algorithm. The goal is to make informed decisions about performance trade-offs and to write code that scales appropriately for your specific needs. So yeah, keep coding, keep practicing!
****Bala Priya C** is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
{kind=link}