Specialized tools for machine learning development and model governance are becoming essential (original) (raw)
A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machine learning (ML) projects. Along the way, we described a new job role and title—machine learning engineer—focused on creating data products and making data science work in production, a role that was beginning to emerge in the San Francisco Bay Area two years ago. At that time, there weren’t any popular tools aimed at solving the problems facing teams tasked with putting machine learning into practice.
About 10 months ago, Databricks announced MLflow, a new open source project for managing machine learning development (full disclosure: Ben Lorica is an advisor to Databricks). We thought that given the lack of clear open source alternatives, MLflow had a decent chance of gaining traction, and this has proven to be the case. Over a relatively short time period, MLflow has garnered more than 3,300 stars on GitHub and 80 contributors from more than 40 companies. Most significantly, more than 200 companies are now using MLflow.

Learn faster. Dig deeper. See farther.
So, why is this new open source project resonating with data scientists and machine learning engineers? Recall the following key attributes of a machine learning project:
- Unlike traditional software where the goal is to meet a functional specification, in ML the goal is to optimize a metric.
- Quality depends not just on code, but also on data, tuning, regular updates, and retraining.
- Those involved with ML usually want to experiment with new libraries, algorithms, and data sources—and thus, one must be able to put those new components into production.
MLflow’s success can be attributed to a lightweight “open interface” that allows users to hook up their favorite machine learning libraries, and the availability of three components that users can pick and choose from (i.e., they can use one, two, or all three of the following):
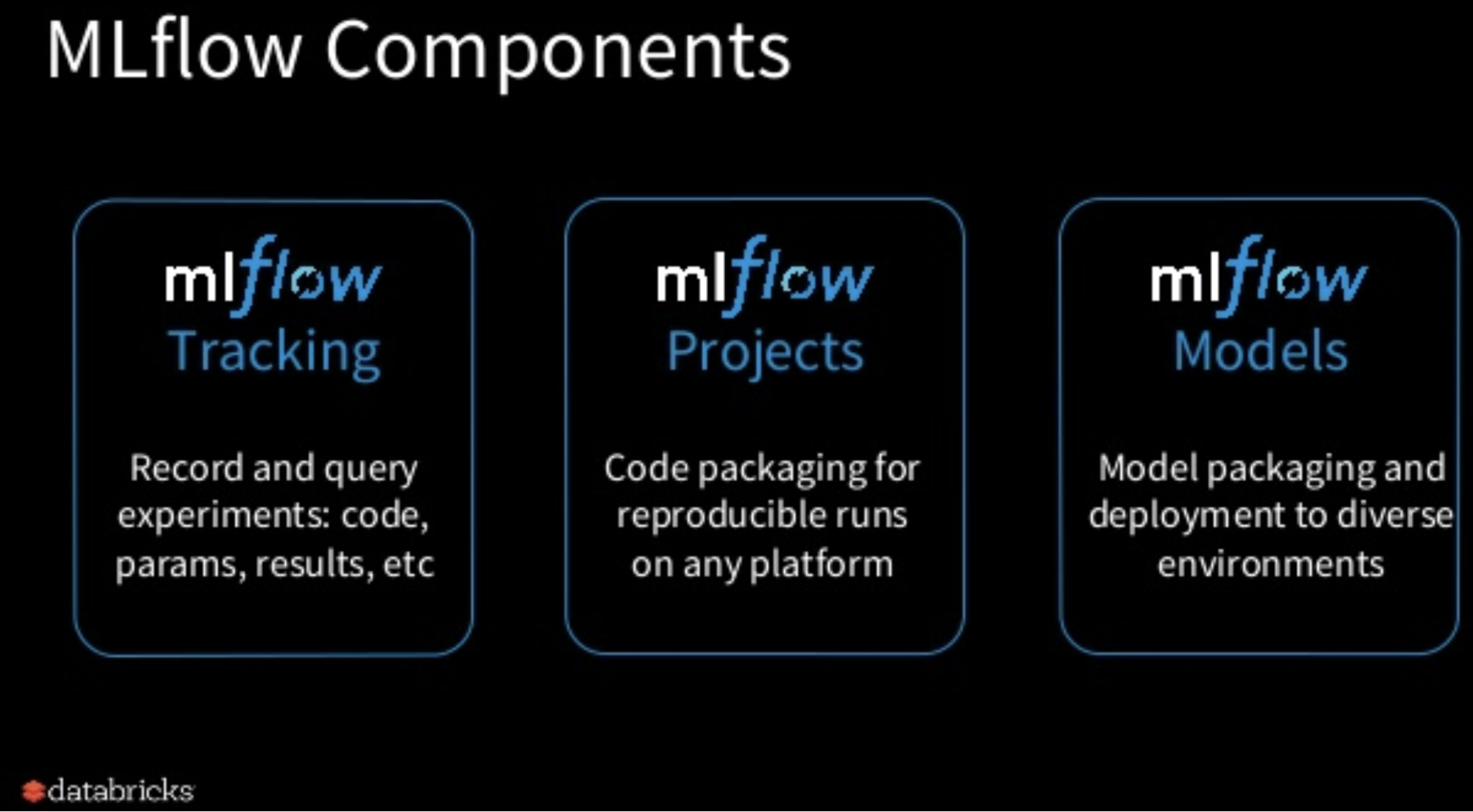
Figure 1. Image by Matei Zaharia; used with permission.
The fact that one can pick and choose which MLflow component(s) to use means the project is able to quickly serve the needs of a diverse set of users. Based on an upcoming survey we conducted of MLflow users, here are some of the most popular use cases:
- Tracking and managing large numbers of machine learning experiments: MLflow is useful for an individual data scientist tracking his/her own experiments, but it is also designed to be used by companies with large teams of machine learning developers who are using it to track thousands of models.
- MLflow is being used to manage multi-step machine learning pipelines.
- Model packaging: companies are using MLflow to incorporate custom logic and dependencies as part of a model’s package abstraction before deploying it to their production environment (example: a recommendation system might be programmed to not display certain images to minors).
The upcoming 0.9.0 release has many new features, including support for database stores for the MLflow Tracking Server, which will make it easier for large teams to query and track ongoing and past experiments.
We are still in the early days for tools supporting teams developing machine learning models. Besides MLflow, there are startups like Comet.ml and Verta.ai that are building tools to ease similar pain points. As software development begins to resemble ML development over the next few years, we expect to see more investments in tools.
Model governance
Companies need to look seriously at the improved tools for developing machine learning models, many of which are part of more ambitious tools suites. Machine learning can’t be limited to researchers with Ph.D.s; there aren’t enough of them. Machine learning is in the process of democratization; tools that make it possible for software developers to build and train models are essential to this process.
We’ve also said the number of machine learning models that are deployed in production will increase dramatically: many applications will be built from many models, and many organizations will want to automate many different aspects of their business. And those models will age and need to be re-trained periodically. We’ve become accustomed to the need for data governance and provenance, understanding and controlling the many
databases that are combined in a modern data-driven application. We’re now realizing the same is true for models, too. Companies will need to track the models they’re building and the models they have in production.
Startups like Datatron are beginning to use the term “model governance” to describe the task of tracking and managing models, and they are beginning to build model governance tools into their product suites. This term describes the processes that enterprises and large companies are starting to use to understand the many ML initiatives and projects teams are working on. Regulators are also signalling their interest in products that rely on AI and machine learning, thus systems for managing ML development are going to be required to comply with future legislation. Here are some of the elements that are going to play a role in building a model governance solution:
- A database for authorization and security: who has read/write access to certain models
- A catalog or a database that lists models, including when they were tested, trained, and deployed
- Metadata and artifacts needed for audits: as an example, the output from the components of MLflow will be very pertinent for audits
- Systems for deployment, monitoring, and alerting: who approved and pushed the model out to production, who is able to monitor its performance and receive alerts, and who is responsible for it
- A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners)
Traditional software developers have long had tools for managing their projects. These tools serve functions like version control, library management, deployment automation, and more. Machine learning engineers know and use all those tools, but they’re not enough. We’re beginning to see the tool suits that provide the features that machine learning engineers need, including tools for model governance, tracking experiments, and packaging models so that results are repeatable. The next big step in the democratization of machine learning is making it more manageable: not simply hand-crafted artisanal solutions, but solutions that make machine learning manageable and deployable at enterprise scale.
Related resources:
- “What are machine learning engineers?”: a new role focused on creating data products and making data science work in production
- “What machine learning means for software development”
- “Deep automation in machine learning”
- “What is hardcore data science—in practice?”: the anatomy of an architecture to bring data science into production
- “Lessons learned turning machine learning models into real products and services”
- Harish Doddi on “Simplifying machine learning lifecycle management”
- Jesse Anderson and Paco Nathan on “What machine learning engineers need to know”
- “Data engineers vs. data scientists”
Post topics: Data
Get the O’Reilly Radar Trends to Watch newsletter
Tracking need-to-know trends at the intersection of business and technology.