How to think about AI and machine learning technologies, and their roles in automation (original) (raw)
In this post, I share slides and notes from a talk Roger Chen and I gave in May 2018 at the Artificial Intelligence Conference in New York. Most companies are beginning to explore how to use machine learning and AI, and we wanted to give an overview and framework for how to think about these technologies and their roles in automation. Along the way, we describe the machine learning and AI tools that can be used to enable automation.
Let me begin by citing a recent survey we conducted: among other things, we found that a majority (54%) consider deep learning an important part of their future projects. Deep learning is a specific machine learning technique, and its success in a variety of domains has led to the renewed interest in AI.

Learn faster. Dig deeper. See farther.
Much of the current media coverage about AI revolves around deep learning. The reality is that many AI systems will use many different machine learning methods and techniques. For example, recent prominent examples of AI systems—systems that excelled at Go and Poker—used deep learning and other methods. In the case of AlphaGo, Monte Carlo Tree Search played a role, whereas DeepStack’s poker playing system combines neural networks with counterfactual regret minimization and heuristic search.

More recently, we’re beginning to see Bayesian and neuroevolutionary methods being used in conjunction with deep learning. I anticipate more papers and articles describing compelling and very practical hybrid systems in the future.
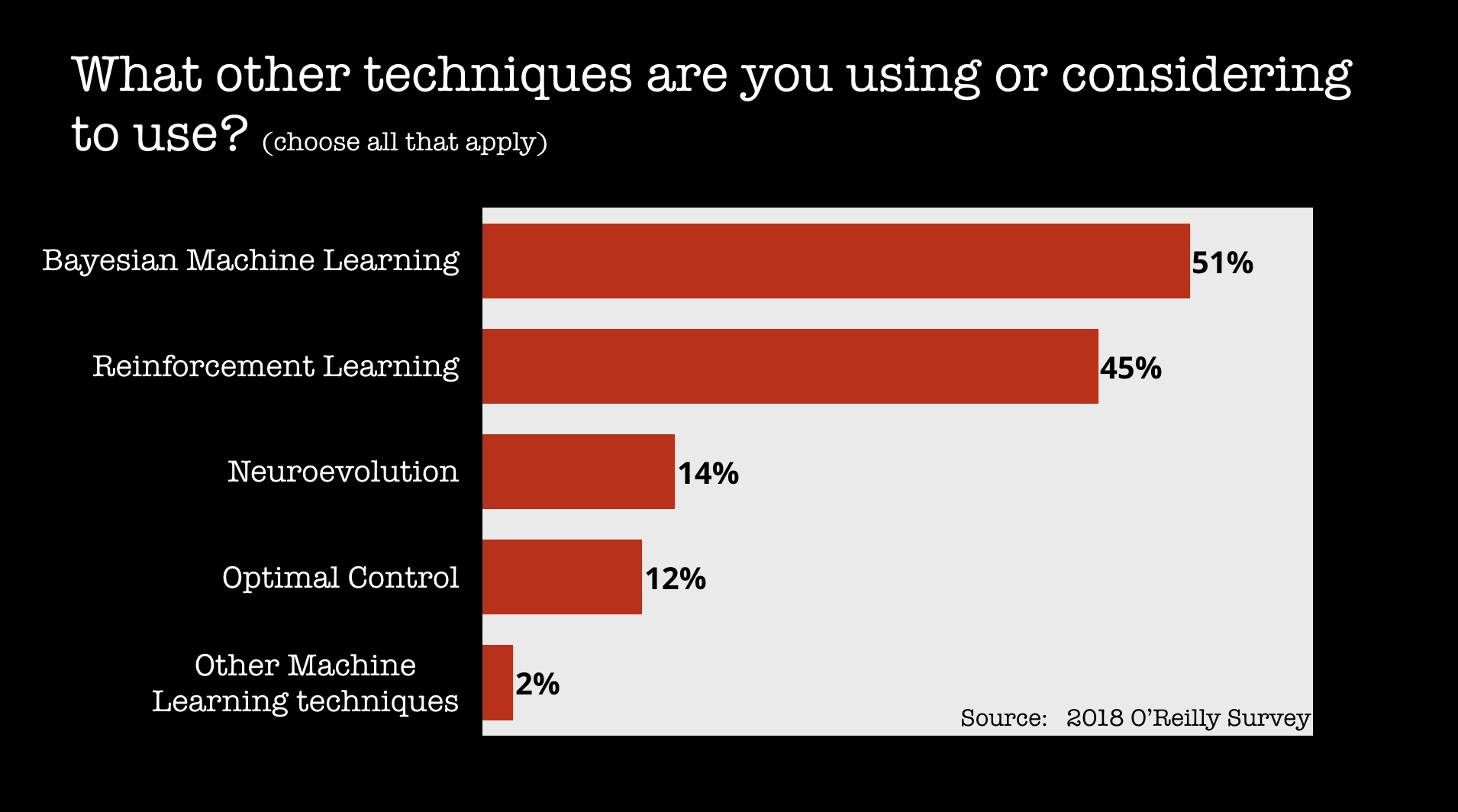
Aside from deep learning, reinforcement learning (RL) stands out as a topic gaining interest among companies. Reinforcement learning has played a critical role in many prominent AI systems. Depending on the context, an AI system might be asked to solve different types of problems: reinforcement learning excels at problems that fall outside the realm of unsupervised and supervised machine learning. One way to think of RL is in the context of an agent learning how to behave within a given environment—through repeatedly exploring a given environment, one attempts to learn a policy for how an agent should behave under certain conditions. The fact that prominent examples of “self-learning” systems rely on reinforcement learning has made it a hot topic among AI researchers.
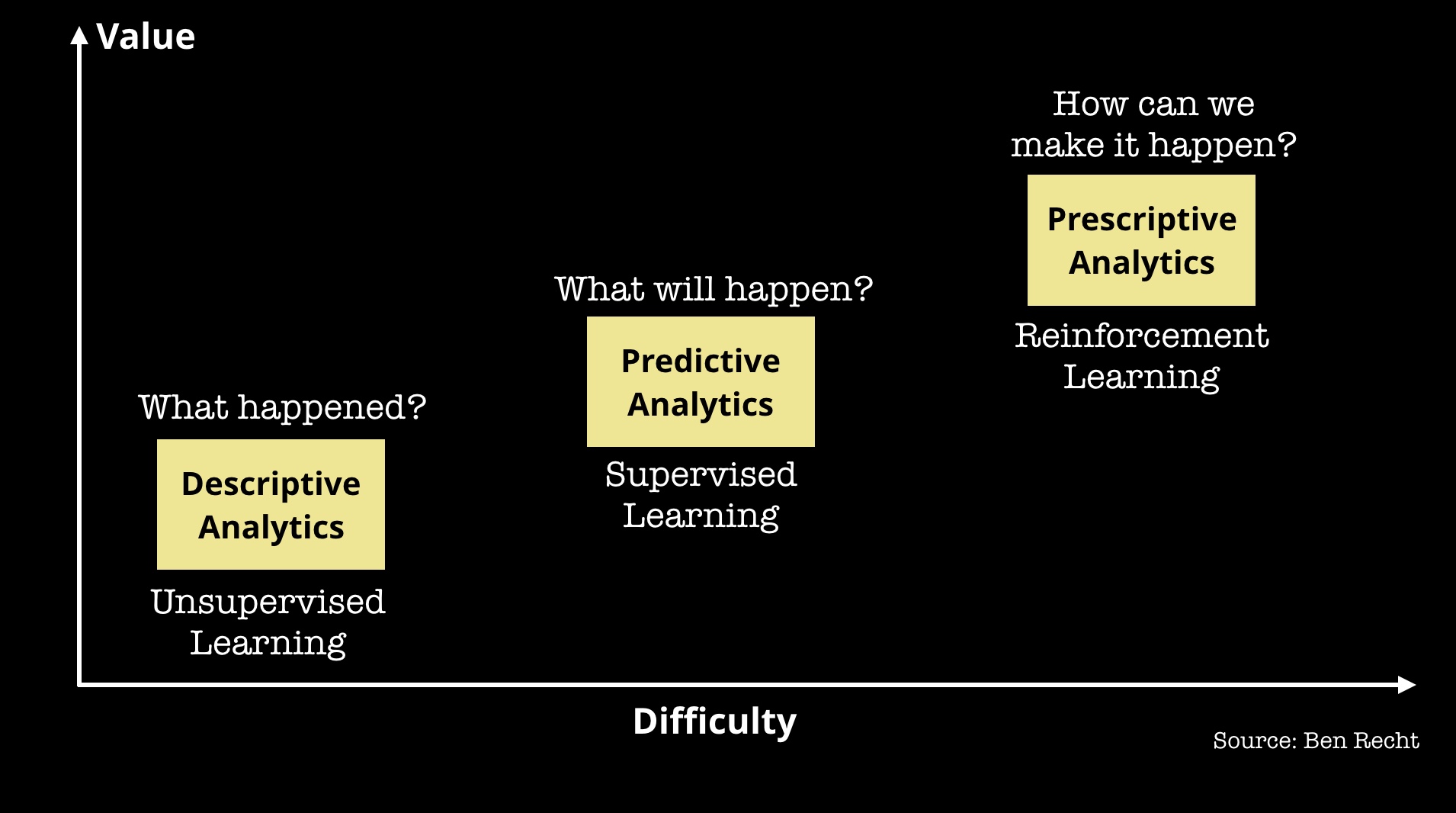
However, reinforcement learning is not without challenges:
- First, teaching an agent how to act in a given environment requires a lot of data. That’s why many of the initial applications are in areas where you have access to simulations.
- Second, it’s challenging to reproduce the results found in research papers let alone to translate them into working systems. This may change as new open source systems, particularly RISE Lab’s Ray and RLlib, get used by more researchers, and we see less custom or one-off code. Coincidentally, in recent weeks I’ve come across some major companies that are already using Ray in production as part of their infrastructure.
Despite these challenges, reinforcement learning is beginning to see real-world usage in areas like industrial automation. Mark Hammond of Bonsai has described many examples of how companies are using RL—including how to manage wind turbines or operate expensive machines. Google’s DeepMind has reportedly developed an RL-based system to help improve power consumption in its data centers. Hammond describes the process of training RL models as “machine teaching”: using domain experts to train an RL-based system that can then enable automation:
[You want] to enable your subject matter experts (a chemical engineer or a mechanical engineer, someone who is very, very well versed in whatever their domain is but not necessarily in machine learning or data science) to take that expertise and use it as the foundation for describing what to teach and then automating the underlying pieces.
Automation
Machine learning and AI will enable automation across many domains and professions. We sometimes think of automation as binary: either we have full automation or we have no automation. The truth is, automation occurs on a spectrum. For example, the self-driving car industry has several levels with only the highest level (Level 5) representing full automation.
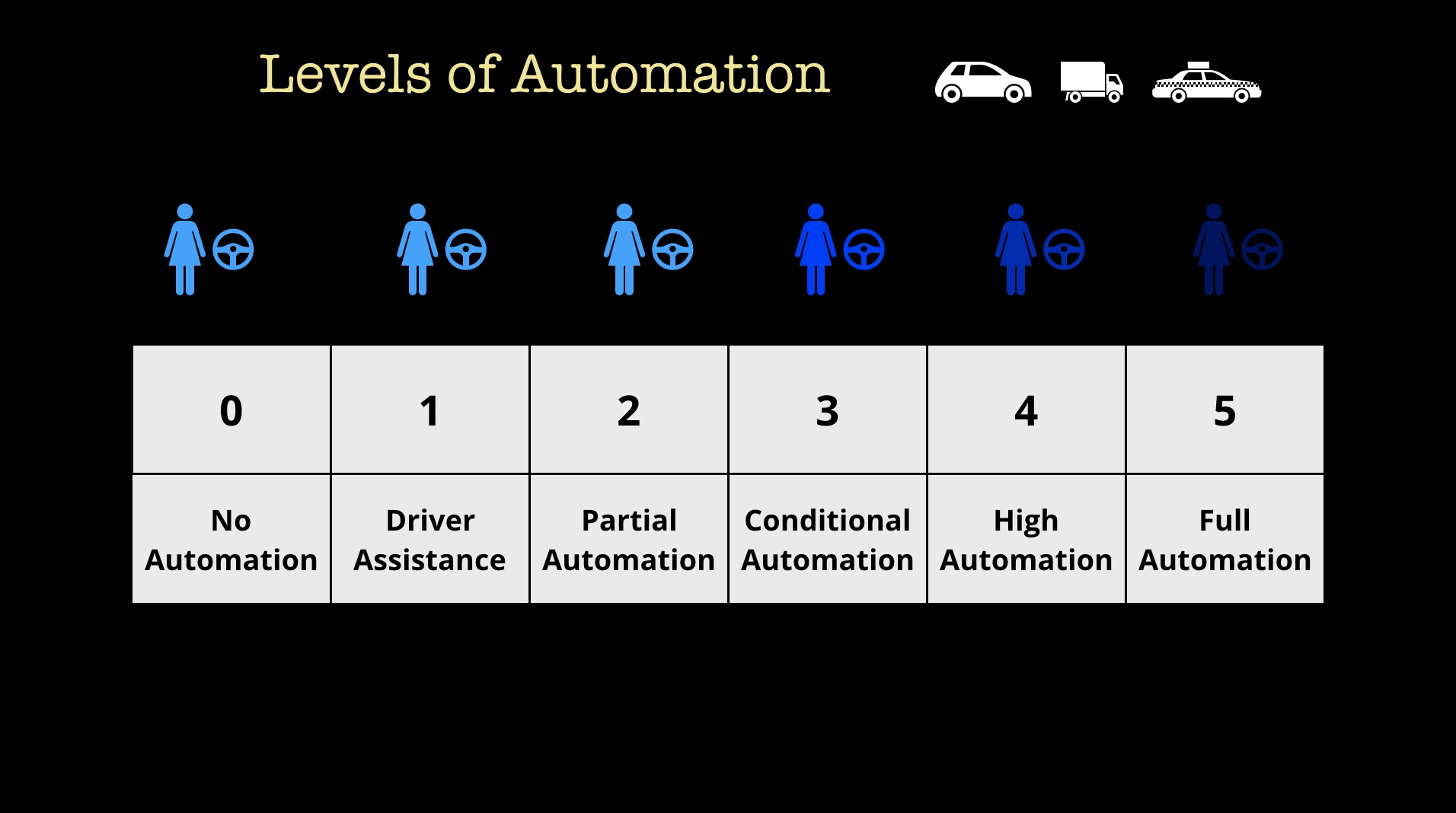
In fact, McKinsey estimates that “fewer than 5% of occupations can be entirely automated using current technology. However, about 60% of occupations could have 30% or more of their constituent activities automated.” Tim O’Reilly has written about about the impact of these technologies on the economy and on employment, and notes that augmentation (“human-in-the-loop”) technologies open up many possibilities.
So, when you are considering automating certain tasks, keep in mind that in many cases, current technologies might be able to help you already achieve partial automation. How does one go about identifying which task should be automated? Since we are talking about using machine learning, a couple basic requirements need to be met:
- Do you have data to support automation?
- Do you have the scale to justify it?
Identifying which tasks to automate is critical, as Tesla recently found out in their quest to automate many aspects of car manufacturing. Tesla CEO, Elon Musk, recently observed: “excessive automation at Tesla was a mistake. … Humans are underrated.” If identifying use cases is difficult even for Tesla, how does this bode for enterprises? The good news is that there are many companies and AI startups that are looking at tasks and workflows in a typical company, and carefully examining which ones can be (partially) automated using current technologies. Some recent examples of partial automation: Google recently announced Duplex, a voice technology tool that allows users to conduct narrow tasks using natural conversation, and Microsoft demonstrated a tool that transcribes and assembles action items from a meeting.
One of the areas where automation is showing up is in software development and data science. This isn’t surprising since engineers are smart and they are always attempting to automate repetitive and tedious tasks. From database management systems to designing neural network architectures to tools for writing bug free code, there are a lot of interesting automation tools that are becoming available. Another area that’s exploding is automating customer interactions. We are still in the early stages, and many of the rudimentary chatbots we see today will pale in comparison to the smart assistants that may become available years from now.
How soon before we have truly smart assistants? More generally, how soon before we expect automation in enterprise workflows? The rate of progress will be determined by research advances in key building blocks. In the case of chatbots, this includes natural language understanding and natural language generation. For manual work, it will require advances in perception and robotics.

The AI systems we have today rely on deep learning and, thus, tend to require large amounts of labeled data—that data is used to train large models that require a lot of computational resources. With that said, I predict that the AI systems of the future will look differently than the system we have today. First of all, what is called AI today is often really just machine learning. In a recent post, we outlined the efforts aimed toward building tools for the AI applications of tomorrow:
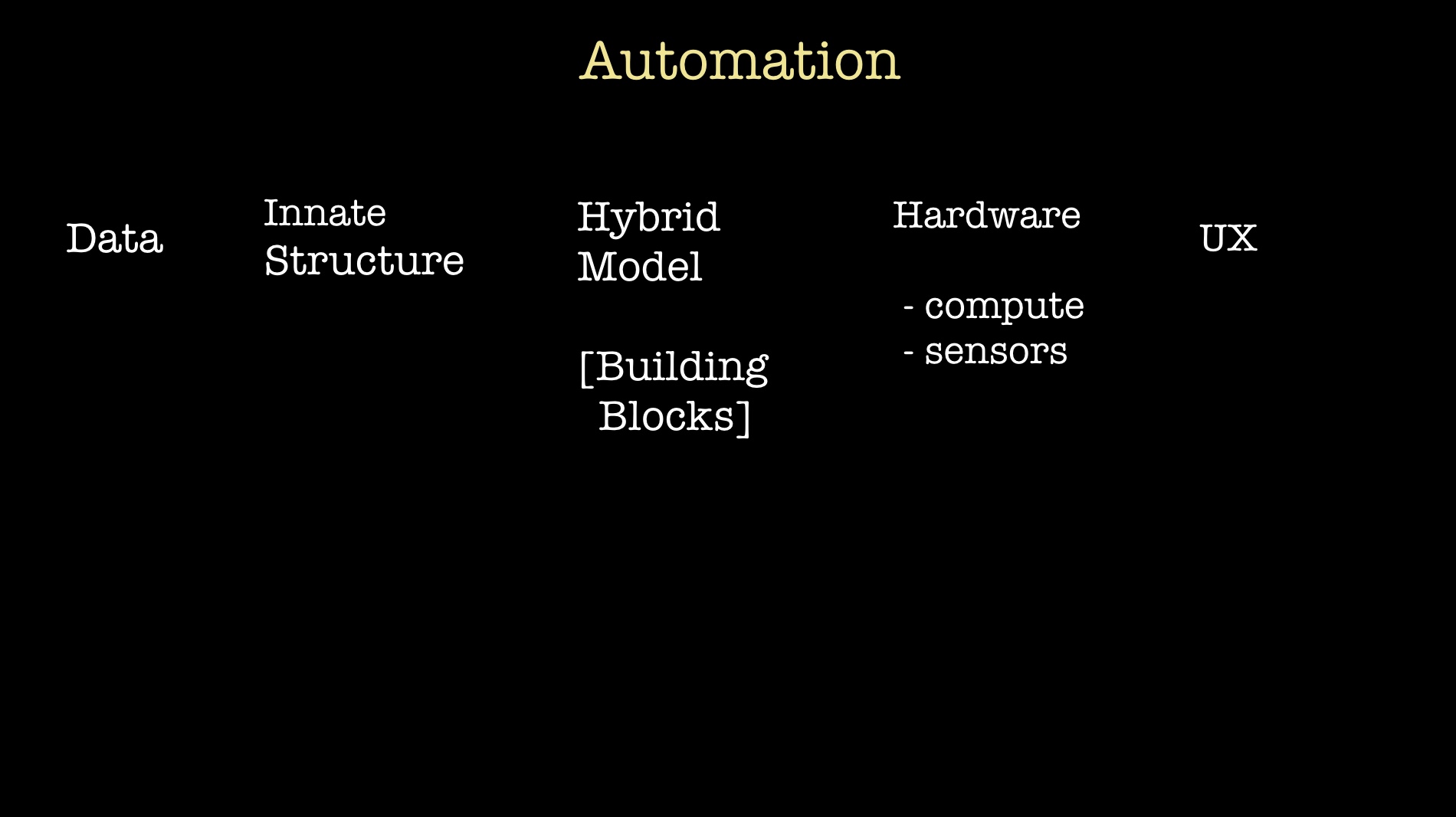
Intelligence augmentation and intelligent infrastructure are inherently multidisciplinary, and require going beyond the perspective of a single agent learning to map inputs to outputs. Such a perspective, and its current implementation with deep learning, will inevitably be part of the solution; but just as inevitably, it won’t be the whole solution.
True AI applications will require integrating many components—sensors, hardware, UX, and many software components. One way to understand the mixture of technologies that can come into play (to build a specific AI system) is to read Shaoshan Liu’s post detailing the components needed to build an autonomous vehicle.
Closing thoughts
We are still in the early phases of AI and automation. The current generation of tools have already allowed partial automation in certain domains. And as we see more advances occur in several foundational areas (2018 will be an interesting year for hardware), we look forward to seeing the AI community roll out targeted systems in many different domains and applications. Even domain specific, end-to-end AI systems will require progress in technologies that cut across disciplines and communities.
Related content:
- “Understanding Automation”
- How Companies Are Putting AI to Work Through Deep Learning: results of a recent O’Reilly survey
- “Building tools for the AI applications of tomorrow”
- “Toward the Jet Age of machine learning”
- “How Ray makes continuous learning accessible and easy to scale”
- “Practical applications of reinforcement learning in industry”
- Neuroevolution – a different kind of deep learning: the quest to evolve neural networks through evolutionary algorithms
- Machine learning needs machine teaching: Mark Hammond on applications of reinforcement learning to manufacturing and industrial automation
- Use deep learning on data you already have: putting deep learning into practice with new tools, frameworks, and future developments
Get the O’Reilly Radar Trends to Watch newsletter
Tracking need-to-know trends at the intersection of business and technology.