Copyright, AI, and Provenance (original) (raw)
Generative AI stretches our current copyright law in unforeseen and uncomfortable ways. In the US, the Copyright Office has issued guidance stating that the output of image-generating AI isn’t copyrightable unless human creativity has gone into the prompts that generated the output. This ruling in itself raises many questions: How much creativity is needed, and is that the same kind of creativity that an artist exercises with a paintbrush? If a human writes software to generate prompts that in turn generate an image, is that copyrightable? If the output of a model can’t be owned by a human, who (or what) is responsible if that output infringes existing copyright? Is an artist’s style copyrightable, and if so, what does that mean?
Another group of cases involving text (typically novels and novelists) argue that using copyrighted texts as part of the training data for a large language model (LLM) is itself copyright infringement,1 even if the model never reproduces those texts as part of its output. But reading texts has been part of the human learning process as long as reading has existed, and while we pay to buy books, we don’t pay to learn from them. These cases often point out that the texts used in training were acquired from pirated sources—which makes for good press, although that claim has no legal value. Copyright law says nothing about whether texts are acquired legally or illegally.

Learn faster. Dig deeper. See farther.
How do we make sense of this? What should copyright law mean in the age of artificial intelligence?
In an article in The New Yorker, Jaron Lanier introduces the idea of data dignity, which implicitly distinguishes between training a model and generating output using a model. Training an LLM means teaching it how to understand and reproduce human language. (The word “teaching” arguably invests too much humanity into what is still software and silicon.) Generating output means what it says: providing the model instructions that cause it to produce something. Lanier argues that training a model should be a protected activity but that the output generated by a model can infringe on someone’s copyright.
This distinction is attractive for several reasons. First, current copyright law protects “transformative use.” You don’t have to understand much about AI to realize that a model is transformative. Reading about the lawsuits reaching the courts, we sometimes have the feeling that authors believe that their works are somehow hidden inside the model, that George R. R. Martin thinks that if he searched through the trillion or so parameters of GPT-4, he’d find the text to his novels. He’s welcome to try, and he won’t succeed. (OpenAI won’t give him the GPT models, but he can download the model for Meta’s Llama 2 and have at it.) This fallacy was probably encouraged by another New Yorker article arguing that an LLM is like a compressed version of the web. That’s a nice image, but it is fundamentally wrong. What is contained in the model is an enormous set of parameters based on all the content that has been ingested during training, that represents the probability that one word is likely to follow another. A model isn’t a copy or a reproduction, in whole or in part, lossy or lossless, of the data it’s trained on; it is the potential for creating new and different content. AI models are probability engines; an LLM computes the next word that’s most likely to follow the prompt, then the next word most likely to follow that, and so on. The ability to emit a sonnet that Shakespeare never wrote: that’s transformative, even if the new sonnet isn’t very good.
Lanier’s argument is that building a better model is a public good, that the world will be a better place if we have computers that can work directly with human language, and that better models serve us all—even the authors whose works are used to train the model. I can ask a vague, poorly formed question like “In which 21st century novel do two women travel to Parchman prison to pick up one of their husbands who is being released,” and get the answer “Sing, Unburied, Sing by Jesmyn Ward.” (Highly recommended, BTW, and I hope this mention generates a few sales for her.) I can also ask for a reading list about plagues in 16th century England, algorithms for testing prime numbers, or anything else. Any of these prompts might generate book sales—but whether or not sales result, they will have expanded my knowledge. Models that are trained on a wide variety of sources are a good; that good is transformative and should be protected.
The problem with Lanier’s concept of data dignity is that, given the current state of the art in AI models, it is impossible to distinguish meaningfully between “training” and “generating output.” Lanier recognizes that problem in his criticism of the current generation of “black box” AI, in which it’s impossible to connect the output to the training inputs on which the output was based. He asks, “Why don’t bits come attached to the stories of their origins?,” pointing out that this problem has been with us since the beginning of the web. Models are trained by giving them smaller bits of input and asking them to predict the next word billions of times; tweaking the model’s parameters slightly to improve the predictions; and repeating that process thousands, if not millions, of times. The same process is used to generate output, and it’s important to understand why that process makes copyright problematic. If you give a model a prompt about Shakespeare, it might determine that the output should start with the word “To.” Given that it has already chosen “To,” there’s a slightly higher probability that the next word in the output will be “be.” Given that, there’s an even slightly higher probability that the next word will be “or.” And so on. From this standpoint, it’s hard to say that the model is copying the text. It’s just following probabilities—a “stochastic parrot.” It’s more like monkeys typing randomly at keyboards than a human plagiarizing a literary text—but these are highly trained, probabilistic monkeys that actually have a chance at reproducing the works of Shakespeare.
An important consequence of this process is that it’s not possible to connect the output back to the training data. Where did the word “or” come from? Yes, it happens to be the next word in Hamlet’s famous soliloquy; but the model wasn’t copying Hamlet, it just picked “or” out of the hundreds of thousands of words it could have chosen, on the basis of statistics. It isn’t being creative in any way we as humans would recognize. It’s maximizing the probability that we (humans) will perceive the output it generates as a valid response to the prompt.
We believe that authors should be compensated for the use of their work—not in the creation of the model, but when the model produces their work as output. Is it possible? For a company like O’Reilly Media, a related question comes into play. Is it possible to distinguish between creative output (“Write in the style of Jesmyn Ward”) and actionable output (“Write a program that converts between current prices of currencies and altcoins”)? The response to the first question might be the start of a new novel—which might be substantially different from anything Ward wrote, and which doesn’t devalue her work any more than her second, third, or fourth novels devalue her first novel. Humans copy each other’s style all the time! That’s why English style post-Hemingway is so distinctive from the style of 19th century authors, and an AI-generated homage to an author might actually increase the value of the original work, much as human “fan-fic” encourages rather than detracts from the popularity of the original.
The response to the second question is a piece of software that could take the place of something a previous author has written and published on GitHub. It could substitute for that software, possibly cutting into the programmer’s revenue. But even these two cases aren’t as different as they first appear. Authors of “literary” fiction are safe, but what about actors or screenwriters whose work could be ingested by a model and transformed into new roles or scripts? There are 175 Nancy Drew books, all “authored” by the nonexistent Carolyn Keene but written by a long chain of ghostwriters. In the future, AIs may be included among those ghostwriters. How do we account for the work of authors—of novels, screenplays, or software—so they can be compensated for their contributions? What about the authors who teach their readers how to master a complicated technology topic? The output of a model that reproduces their work provides a direct substitute rather than a transformative use that may be complementary to the original.
It may not be possible if you use a generative model configured as a chat server by itself. But that isn’t the end of the story. In the year or so since ChatGPT’s release, developers have been building applications on top of the state-of-the-art foundation models. There are many different ways to build applications, but one pattern has become prominent: retrieval-augmented generation, or RAG. RAG is used to build applications that “know about” content that isn’t in the model’s training data. For example, you might want to write a stockholders’ report or generate text for a product catalog. Your company has all the data you need—but your company’s financials obviously weren’t in ChatGPT’s training data. RAG takes your prompt, loads documents in your company’s archive that are relevant, packages everything together, and sends the prompt to the model. It can include instructions like “Only use the data included with this prompt in the response.” (This may be too much information, but this process generally works by generating “embeddings” for the company’s documentation, storing those embeddings in a vector database, and retrieving the documents that have embeddings similar to the user’s original question. Embeddings have the important property that they reflect relationships between words and texts. They make it possible to search for relevant or similar documents.)
While RAG was originally conceived as a way to give a model proprietary information without going through the labor- and compute-intensive process of training, in doing so it creates a connection between the model’s response and the documents from which the response was created. The response is no longer constructed from random words and phrases that are detached from their sources. We have provenance. While it still may be difficult to evaluate the contribution of the different sources (23% from A, 42% from B, 35% from C), and while we can expect a lot of natural language “glue” to have come from the model itself, we’ve taken a big step forward toward Lanier’s data dignity. We’ve created traceability where we previously had only a black box. If we published someone’s currency conversion software in a book or training course and our language model reproduces it in response to a question, we can attribute that to the original source and allocate royalties appropriately. The same would apply to new novels in the style of Jesmyn Ward or, perhaps more appropriately, to the never-named creators of pulp fiction and screenplays.
Google’s “AI-powered overview” feature2 is a good example of what we can expect with RAG. We can’t say for certain that it was implemented with RAG, but it clearly follows the pattern. Google, which invented Transformers, knows better than anyone that Transformer-based models destroy metadata unless you do a lot of special engineering. But Google has the best search engine in the world. Given a search string, it’s simple for Google to perform the search, take the top few results, and then send them to a language model for summarization. It relies on the model for language and grammar but derives the content from the documents included in the prompt. That process could give exactly the results shown below: a summary of the search results, with down arrows that you can open to see the sources from which the summary was generated. Whether this feature improves the search experience is a good question: while an interested user can trace the summary back to its source, it places the source two steps away from the summary. You have to click the down arrow, then click on the source to get to the original document. However, that design issue isn’t germane to this discussion. What’s important is that RAG (or something like RAG) has enabled something that wasn’t possible before: we can now trace the sources of an AI system’s output.
Now that we know that it’s possible to produce output that respects copyright and, if appropriate, compensates the author, it’s up to regulators to hold companies accountable for failing to do so, just as they are held accountable for hate speech and other forms of inappropriate content. We should not buy into the assertion of the large LLM providers that this is an impossible task. It is one more of the many business models and ethical challenges that they must overcome.

The RAG pattern has other advantages. We’re all familiar with the ability of language models to “hallucinate,” to make up facts that often sound very convincing. We constantly have to remind ourselves that AI is only playing a statistical game, and that its prediction of the most likely response to any prompt is often wrong. It doesn’t know that it is answering a question, nor does it understand the difference between facts and fiction. However, when your application supplies the model with the data needed to construct a response, the probability of hallucination goes down. It doesn’t go to zero, but it is significantly lower than when a model creates a response based purely on its training data. Limiting an AI to sources that are known to be accurate makes the AI’s output more accurate.
We’ve only seen the beginnings of what’s possible. The simple RAG pattern, with one prompt orchestrator, one content database, and one language model, will no doubt become more complex. We will soon see (if we haven’t already) systems that take input from a user, generate a series of prompts (possibly for different models), combine the results into a new prompt, which is then sent to a different model. You can already see this happening in the latest iteration of GPT-4: when you send a prompt asking GPT-4 to generate a picture, it processes that prompt, then sends the results (probably including other instructions) to DALL-E for image generation. Simon Willison has noted that if the prompt includes an image, GPT-4 never sends that image to DALL-E; it converts the image into a prompt, which is then sent to DALL-E with a modified version of your original prompt. Tracing provenance with these more complex systems will be difficult—but with RAG, we now have the tools to do it.
AI at O’Reilly Media
We’re experimenting with a variety of RAG-inspired ideas on the O’Reilly learning platform. The first extends Answers, our AI-based search tool that uses natural language queries to find specific answers in our vast corpus of courses, books, and videos. In this next version, we’re placing Answers directly within the reading context and using an LLM to generate content-specific questions about the material to enhance your understanding of the topic.
For example, if you’re reading about gradient descent, the new version of Answers will generate a set of related questions, such as how to compute a derivative or use a vector library to increase performance. In this instance, RAG is used to identify key concepts and provide links to other resources in the corpus that will deepen the learning experience.
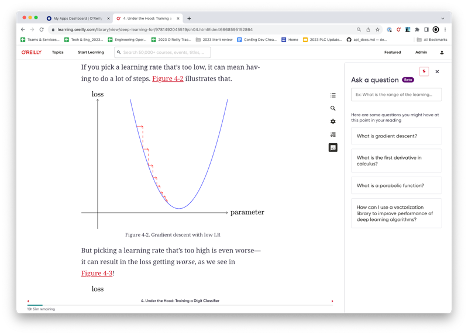
Answers 2.0, expected to go into beta in the first half of 2024
Our second project is geared toward making our long-form video courses simpler to browse. Working with our friends at Design Systems International, we’re developing a feature called “Ask this course,” which will allow you to “distill” a course into just the question you’ve asked. While conceptually similar to Answers, the idea of “Ask this course” is to create a new experience within the content itself rather than just linking out to related sources. We use a LLM to provide section titles and a summary to stitch together disparate snippets of content into a more cohesive narrative.
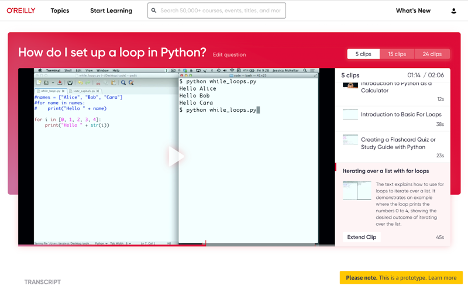
Ask this course, expected to go into beta in the first half of 2024
Footnotes
The first case to reach the courts involving novels and other prose works has been dismissed; the judge said that the claim that the model itself infringed upon the authors’ copyrights was “nonsensical,” and the plaintiffs did not present any evidence that the model actually produced infringing works.
As of November 16, 2023, it’s unclear who has access to this feature; it appears to be in some kind of gradual rollout, A/B test, or beta test, and may be limited to specific browsers, devices, operating systems, or account types.