わずか10秒の元音声でもリアルな「なりきりボイチェン」できる無料ソフト『Seed-VC』は過去最高レベルの再現度か(CloseBox) (original) (raw)
筆者はUTAUによる波形接続の時代から「その人の声になりきる」技術を試してきましたが、このほど、その中でも画期的と思える技術に出会いました。『Seed-VC』(Seed Voice Conversion)というオープンソースソフトです。
■AIボイチェンの進化
どこが画期的なポイントかというと、高い音質を維持しながら、ゼロショット、つまりファインチューニングをせずに、1秒から30秒までの短い音源を参照するだけで、短時間でオリジナルに近いボイチェンができるところにあります。
以前紹介したDiff-SVCやRVCは、オリジナル音声に近いボイチェンが可能ですが、学習にはそれなりの長さのオーディオデータと高性能GPUによる処理が必要です。
RVCはリアルタイムに近い応答が可能で音質もよくなっているのですが、ファインチューニングには時間がかかります。
さらに、これはAIによるファインチューニングとは異なる方式ですが、Vocoflexという商用ソフトでは、数十秒の短いサンプルを読み込ませるだけで本人の歌声に寄せることができる、しかも最高水準のレイテンシーを実現しています。
一方、ゼロショットで声を模倣するTTS(Text to Speech)ソフトとしては、VALL-E Xというものがあります。本物ではなくマイクロソフトが開発した技術をオープンソース実装したもので、開発したのはシンガポール在住の研究者であるPlachtaaさん。
この時に実際に試してみましたが、推論に時間がかかりすぎて実用にはちょっと遠い印象がありました。
筆者は現在、RVCとVocoflexを併用しており、時には単独で、時には両方を使ったダブルトラッキングを活用して音楽制作をしています。
そこに新たに加わったのが、今回紹介するSeed-VC。実は、その作者はVALL-E Xオープンソース版と同じPlachtaaさんだったのです。
GitHubのページでは、コマンドラインでのインストール方法が公開されているのですが、筆者の環境では(おそらくライブラリのバージョンの関係で)うまく動かすことができません。
でも、Hugging Faceでデモページが公開されているので試してみました。
■ゼロショットボイチェンのやり方
使用するオーディオデータは、元音声と参照音声の2種類。どちらもマイクでの取り込みも可能です。

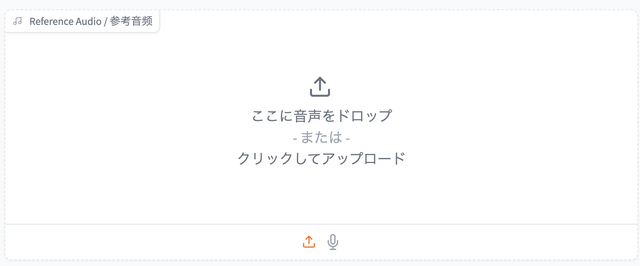
なお、参照音源は最初の25秒しか認識しないので、それ以上の長さの音声データを入力しても意味がありません。
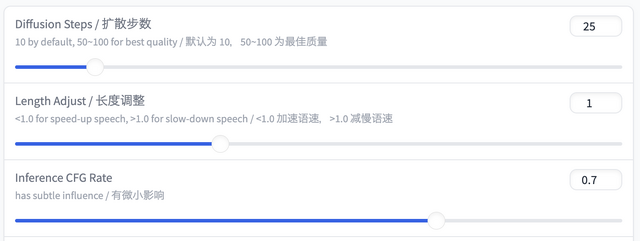
パラメータとしては、推論のステップ数、音声のスピード、CFGレートが設定できます。ここはデフォルト値のままに。
今回試したのは歌声なので、さらに歌声用のパラメータを設定しておきます。
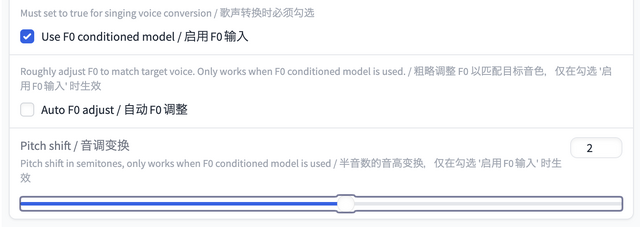
F0つまり元音声のピッチに合わせるという設定にチェックを入れておきます。F0の自動調整は外しておきます。ピッチシフトはなぜか0ではなく2に設定しないとオリジナルキーにならないようです。バグですかね。
ここまで調整が終わったら、Submitボタンをクリック。すると、右上に2つのオーディオデータが生成されます。
上のオーディオデータはストリーミングされるもので、数秒後には再生可能になります。推論が終わったらその下のオーディオデータが再生可能になります。この段階でダウンロード可能です。
この流れを動画にまとめてみました。参照音源は、iPhoneで録音した妻の歌声です。Suno AIで生成した歌声を元音声として、変換してみました。
話し声でもやってみました。同じ参照音源で、元音源はChatGPTのAdavanced Voice Modeを使用。参照音声は歌声のままなのですが、本人の喋り声にかなり近い音声になっています。これはすごいです。
使ってみた印象ですが、元音声の表現をかなり忠実にトレースするようです。例えばブレス、フレーズ末尾の母音の変化など、RVCやVocoflexでは難しかった部分ができているようです。RVCでロボ声化するような場面でもうまくいっています。
一方で、ブレスはかなり大きくなりがちなので歌声においてはオートメーションで調整するなり、ディエッサー使うなりの処理をお好みで。
声質にハリがあり、かなり高音強調で出るので、フォルマントやイコライザーを調整したほうがオリジナルボイスに近づけるような気がします。
■Suno AI、Vocoflex、RVC、Seed-VCの歌声を比較
では作例。ChatGPTに、Seed Voice Conversionをテーマにした歌詞を考えてもらい、Suno AIで作曲。そのボーカルを元に、Vocoflex、RVC、Seed-VCのそれぞれにボイチェンしてみました。
作例では、Suno AIのオリジナルボイスから、Vocoflex、RVC、Seed-VCとボイチェンを変えていき、そこからは3種のボイチェンをミックスしたトリプルトラッキングにしています。
ちなみに動画はFLUX.1 [dev] + LoRAを元に、Runway Gen-3 Alpha Turboでリップシンクしています。Suno AIボーカルの部分のみ、Midjourneyで元絵を作成。
Seed-VCのみのバージョンも用意しました。
参照音声が短くていいので、曲のさまざまな部分をピックアップして、必要に応じて声質を変えていくことも可能。個人的には非常に満足しています。
