Xintao Wang (original) (raw)
News
- [3/2025] We release several interesting papers: ReCamMaster, DiffMoE and IGV-as-GGE.
- [2/2025] Three papers (StyleMaster, PatchVSR and SketchVideo) are accepted to CVPR 2025.
- [1/2025] Two papers (SynCamMaster and3DTrajMaster) are accepted to ICLR 2025.
- [12/2024] Three papers (ImageConductor,CustomCrafter and Anti-Diffusion[oral]) are accepted to AAAI 2025.
- [9/2024] Ranked asTop 2% Scientists Worldwide 2024 (Single Year) by Stanford University.
- [9/2024] Three papers (MiraData, ReVideo andVideoTetris) are accepted to NeurIPS 2024.
- [9/2024] One paper (StyleAdapter) is accepted to IJCV.
- [8/2024] Two papers (ToonCrafter and StyleCrafter) are accepted to SIGGRAPH Asia 2024.
- [7/2024] One paper (CustomNet) is accepted to ACM MM 2024.
- [7/2024] Five papers (DynamiCrafter[oral],BrushNet, DreamDiffusion, MOFA-Video, CheapScaling) are accepted to ECCV 2024.
- [5/2024] One paper (PromptGIP) is accepted to ICML 2024.
- [3/2024] One paper (MotionCtrl) is accepted to SIGGRAPH 2024.
- [3/2024] Nine papers (PhotoMaker, SUPIR, VideoCrafter2, SmartEdit[highlight], Rethink VQ Tokenizer, EvalCrafter, X-Adapter, DiffEditor and Seeing&Hearing) are accepted to CVPR 2024.
- [1/2024] Four papers (DragonDiffusion[spotlight], ScaleCrafter[spotlight], FreeNoise and SEED-LlaMa) are accepted to ICLR 2024.
- [12/2023] Three papers are accepted to AAAI 2024.
- [10/2023] Ranked asTop 2% Scientists Worldwide 2023 (Single Year) by Stanford University. Click for More
- [10/2023] Two papers are accepted to NeurIPS 2023.
- [09/2023] ReleaseT2I-Adapter for SDXL: the most efficient control models, collaborating withHuggingFace.
- [07/2023] Three papers are accepted to ICCV 2023.
- [04/2023] One paper is accepted to ICML 2023.
- [03/2023] We are holding the360° Super-Resolution Challenge as a part of theNTIRE workshop in conjunction with CVPR 2023.
- [02/2023] Three papers to appear in CVPR 2023.
- [11/2022] Two papers to appear in AAAI 2023.
- [09/2022] Ranked asTop 2% Scientists Worldwide 2022 (Single Year) by Stanford University.
- [09/2022] Two papers to appear in NeurIPS 2022.
- [07/2022] Two papers to appear in ECCV 2022. VQFR is accepted as oral (2.7%).
- [06/2022] Two papers to appear in ACM MM 2022.
- [05/2022] BasicSR joins theXPixel Group!
- [04/2022] We release a high-quality face video dataset (VFHQ). Please refer to theproject page andour paper.
- [12/2021] One paper to appear in NeurIPS 2021 asspotlight (2.85%):FAIG: Finding Discriminative Filters for Specific Degradations in Blind Super-Resolution. Codes are released inTencentARC/FAIG.
- [10/2021] Real-ESRGAN is accepted by ICCV 2021 AIM workshop with Honorary Nomination Paper Award.
- [07/2021] One paper to appear in ICCV 2021:Towards Vivid and Diverse Image Colorization with Generative Color Prior
- [07/2021] The codes for practical image restorationReal-ESRGAN are released onGithub.
- [06/2021] The training and testing codes of GFPGAN are released onTencentARC.
- [03/2021] 5 papers to appear in CVPR 2021.
- [03/2021] A brand-newHandyView online!.
- [08/2020] A brand-newBasicSR v1.0.0 online!
- [06/2019] We have released theEDVR training and testing codes and also updatedBasicSR codes!
- [06/2019] Got my first outstanding reviewer recognition from CVPR 2019!
- [05/2019] Our video restoration method, EDVR, won all four tracks in theNTIRE 2019 video restoration and enhancement challenges. Checkour paper for more details.
- [03/2019] Our paperDeep Network Interpolation for Continuous Imagery Effect Transition to appear in CVPR 2019.
- [08/2018] Our SuperSR team won the third track of the2018 PIRM Challenge on Perceptual Super-Resolution. Check the reportESRGAN for more details.
- [06/2018] We won theNTIRE 2018 Challenge on Single Image Super-Resolution as first runner-up and ranked the first in the_Realistic Wild ×4 conditions_ track.
- [02/2018] Our paperRecovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform to appear in CVPR 2018.
- [07/2017] Our HelloSR team won theNTIRE 2017 Challenge on Single Image Super-Resolution as first runner-up.
GFPGAN
Practical face restoration
Real-ESRGAN
Practical algorithms for image restoration
BasicSR
Open source image and video restoration toolbox
T2I-Adapter
Dig out controllable ability for text-to-image diffusion models
VideoCrafter
Open sourced large models for video generation
HandyView
Handy image viewer
Publications[Full List]
(* equal contribution, # corresponding author)
Selected Preprint
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, Di Zhang
arXiv preprint: 2503.11647.
Project Page Paper (arXiv) Codes 
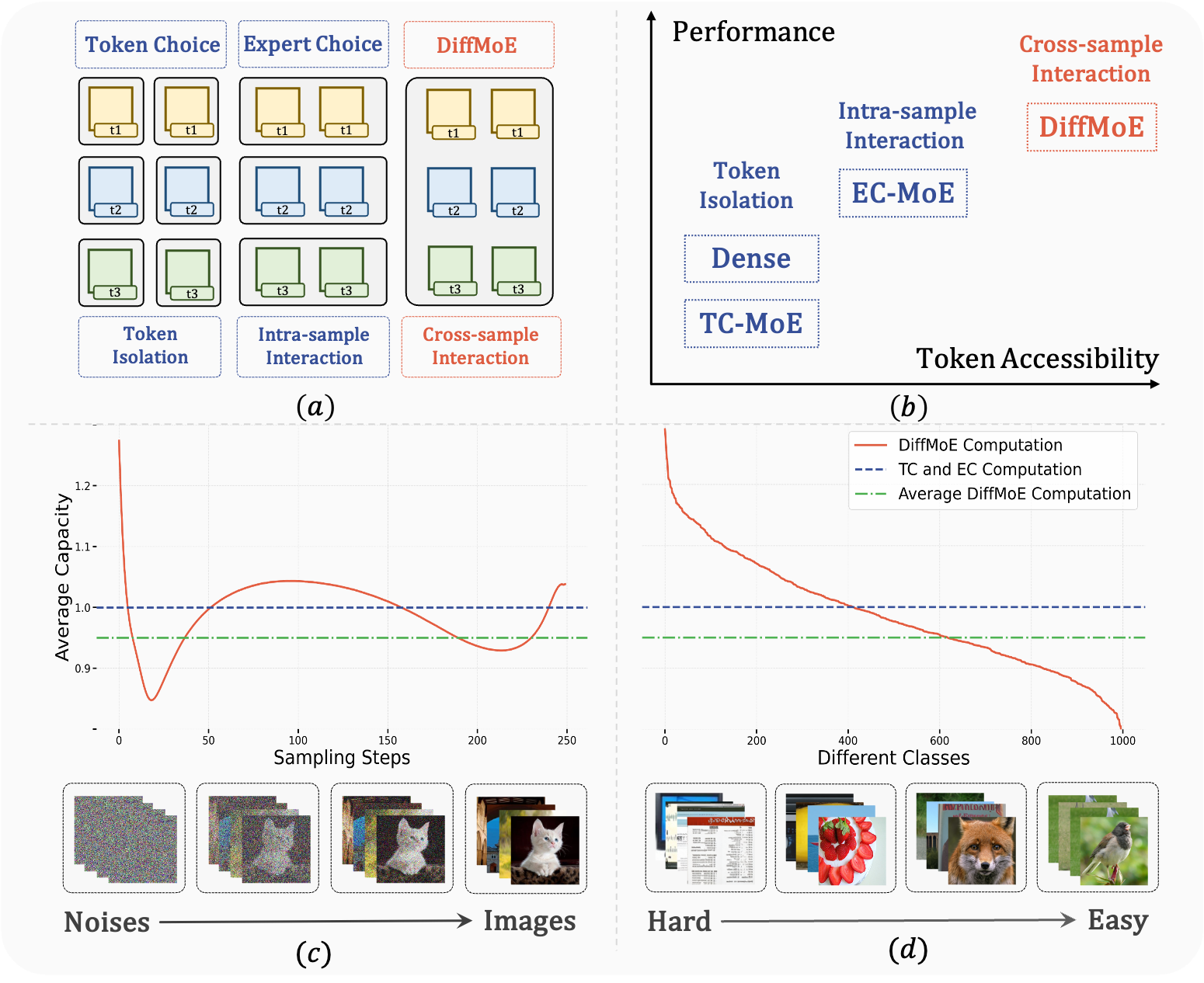
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Minglei Shi, Ziyang Yuan, Haotian Yang, Xintao Wang#, Mingwu Zheng, Xin Tao, Wenliang Zhao, Wenzhao Zheng, Jie Zhou, Jiwen Lu#, Pengfei Wan, Di Zhang, Kun Gai
arXiv preprint: 2503.14487.
Project Page Paper (arXiv) Codes 
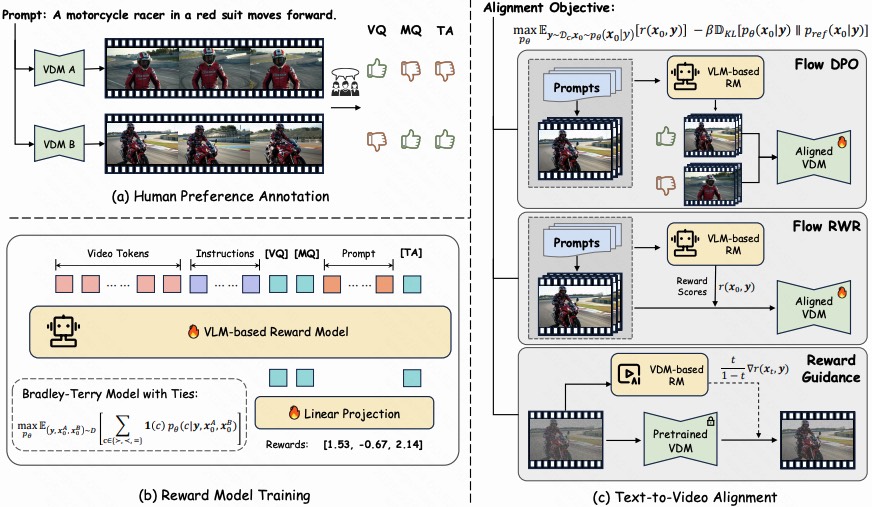
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Menghan Xia, Xintao Wang, Xiaohong Liu, Fei Yang, Pengfei Wan, Di Zhang, Kun Gai, Yujiu Yang, Wanli Ouyang
arXiv preprint: 2501.13918.
Project Page Paper (arXiv) Codes 

2024


3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
Xiao Fu, Xian Liu, Xintao Wang#, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, Dahua Lin#
arXiv preprint: 2412.07759
ICLR, 2025. Project Page Paper (arXiv) Codes 

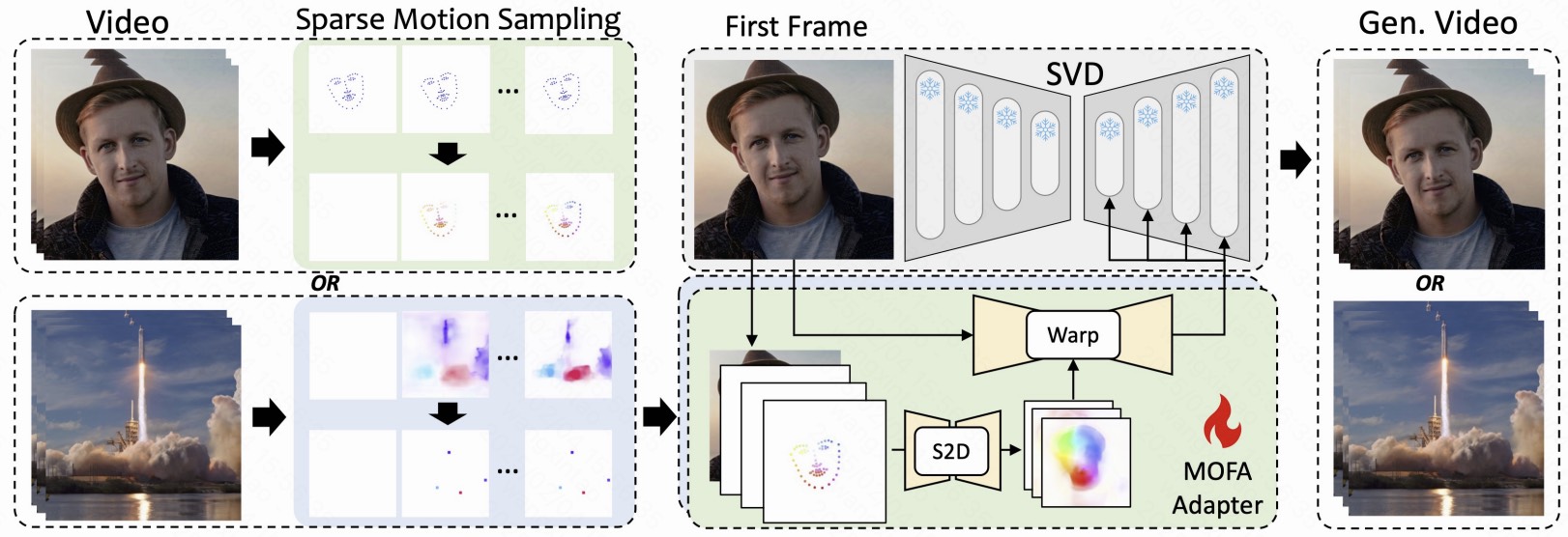

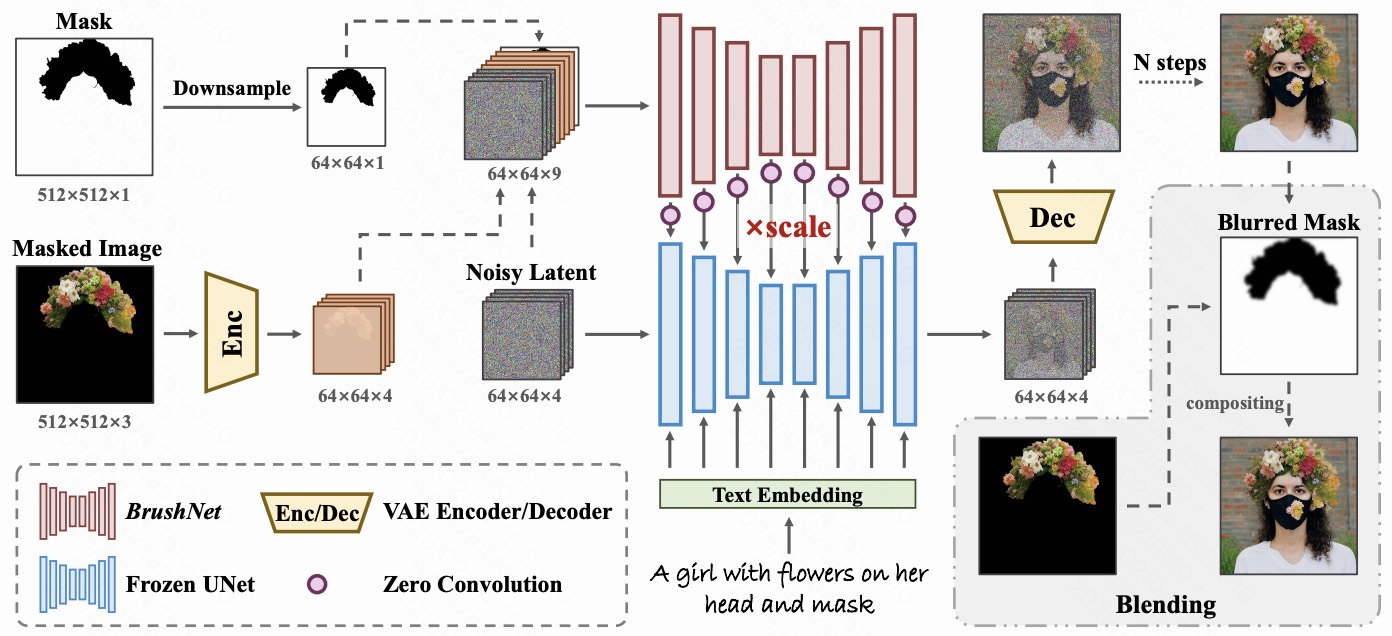

2023

SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Yuzhou Huang, Liangbin Xie, Xintao Wang#, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang#, Ying Shan
arXiv preprint: 2312.06739
CVPR, 2024 (hilight). Project Page Paper (arXiv) Codes 




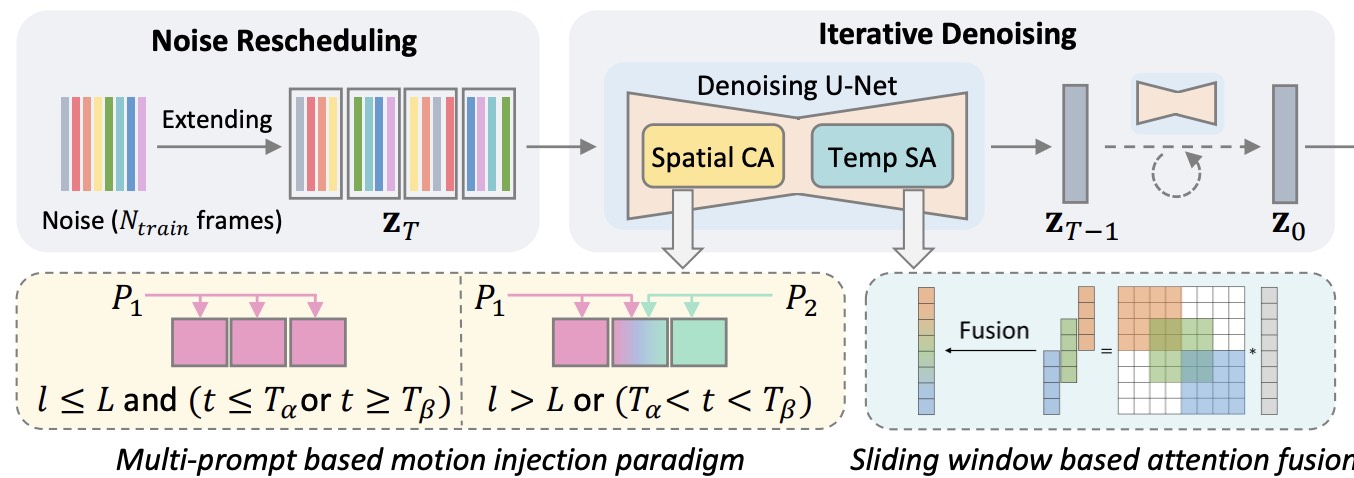
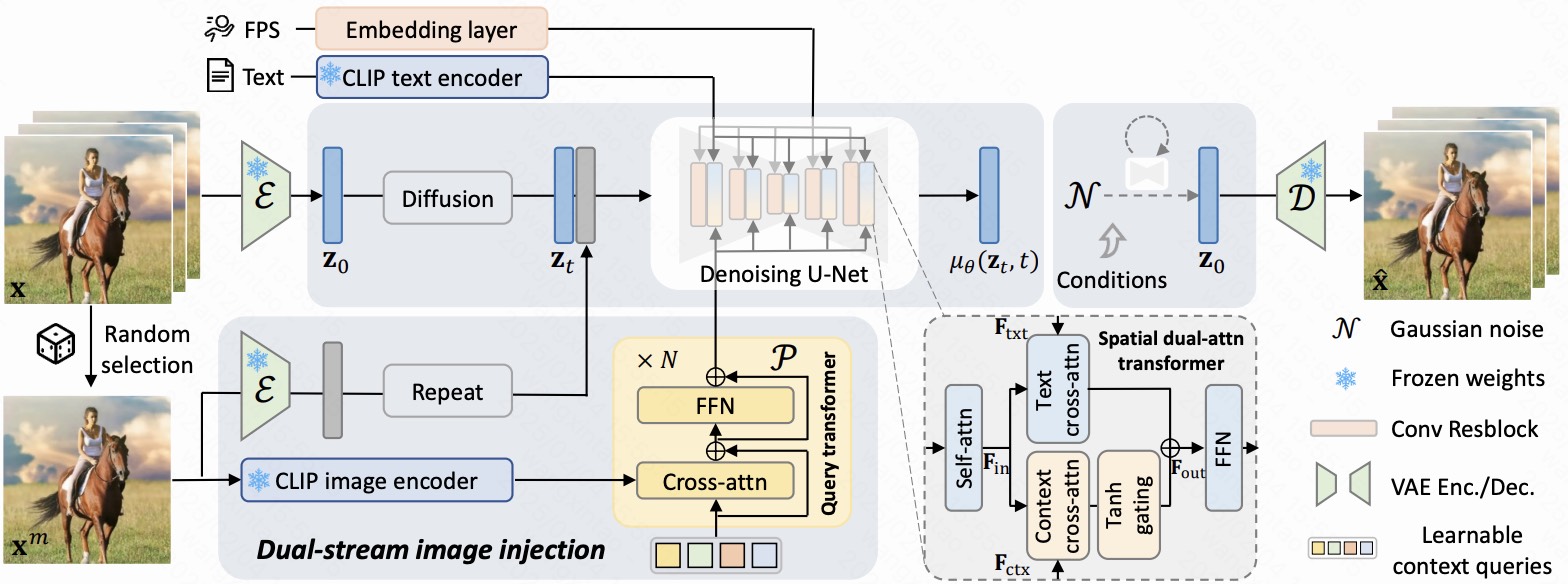
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, Tien-Tsin Wong
arXiv preprint: 2310.12190
ECCV, 2024 (oral). Project Page Paper (arXiv) Codes 
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond H. Chan, Ying Shan
arXiv preprint: 2310.11440
CVPR, 2024. Project Page Paper (arXiv) Codes 
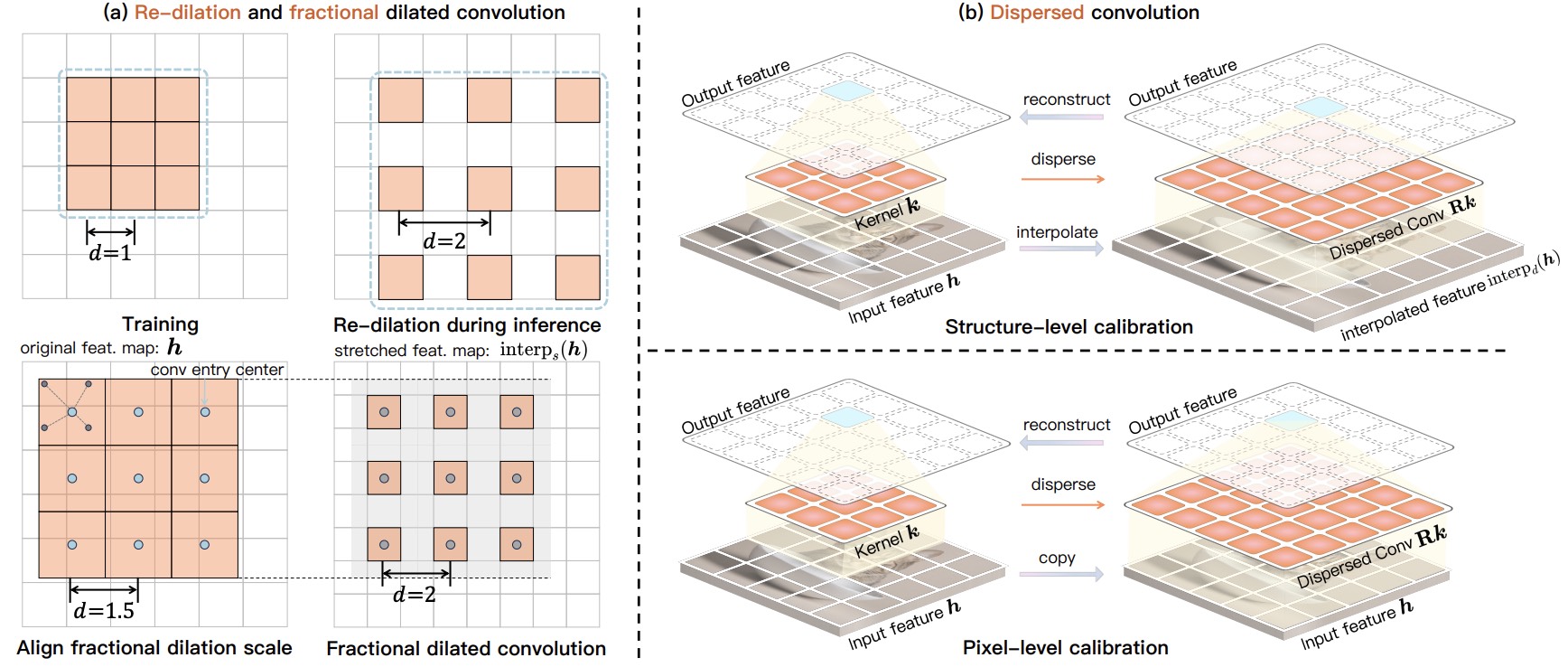
ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, Ying Shan
arXiv preprint: 2310.07702.
ICLR, 2024 (spotlight) Project Page Paper (arXiv) Codes 

Making LLaMA SEE and Draw with SEED Tokenizer
Yuying Ge, Sijie Zhao, Ziyun Zeng, Yixiao Ge, Chen Li, Xintao Wang, Ying Shan Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, , Ying Shan, Ziwei Liu
arXiv preprint: 2310.01218.
ICLR, 2024 Project Page Paper (arXiv) Codes 

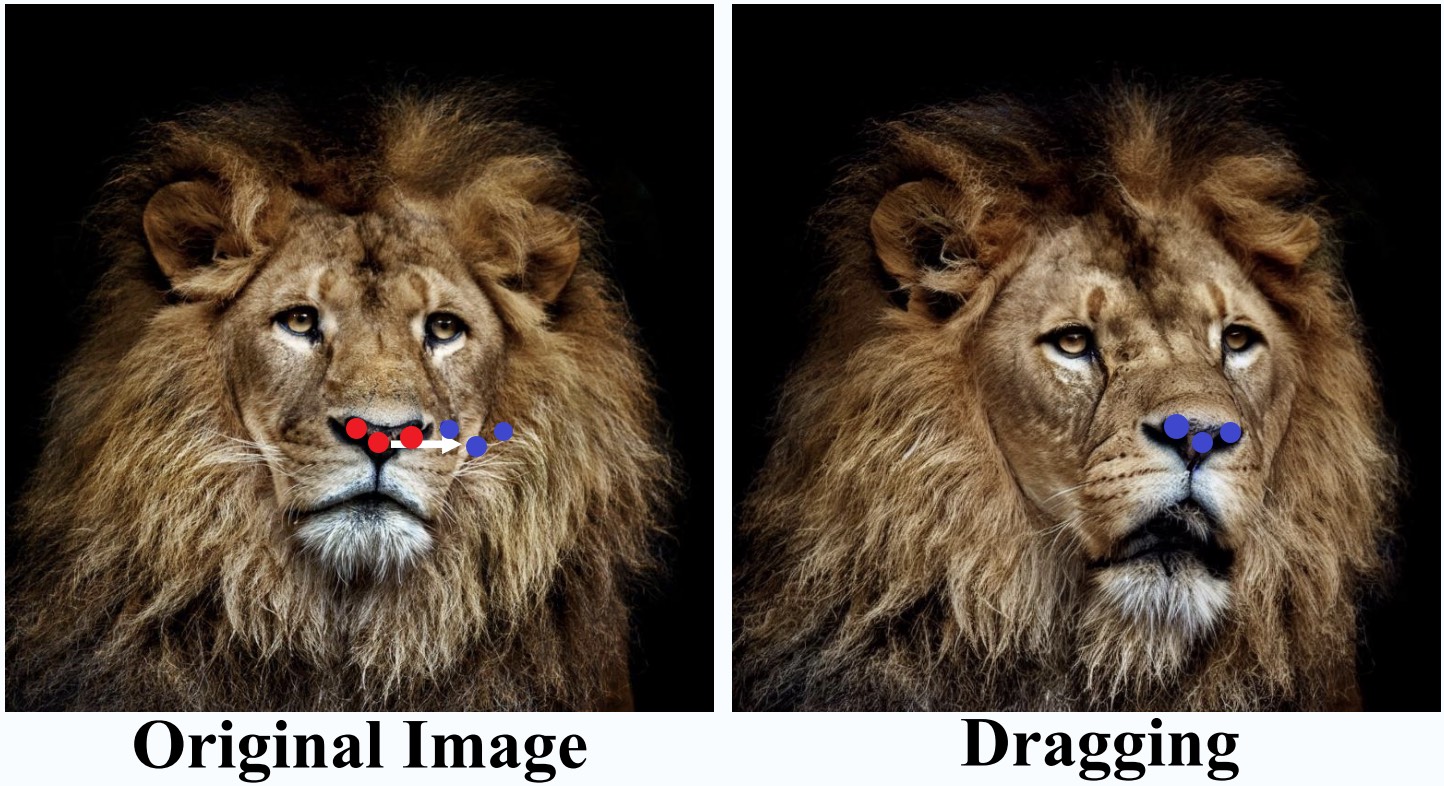

2022

Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou
arXiv preprint: 2212.11565
ICCV, 2023. Project Page Paper (arXiv) Codes 

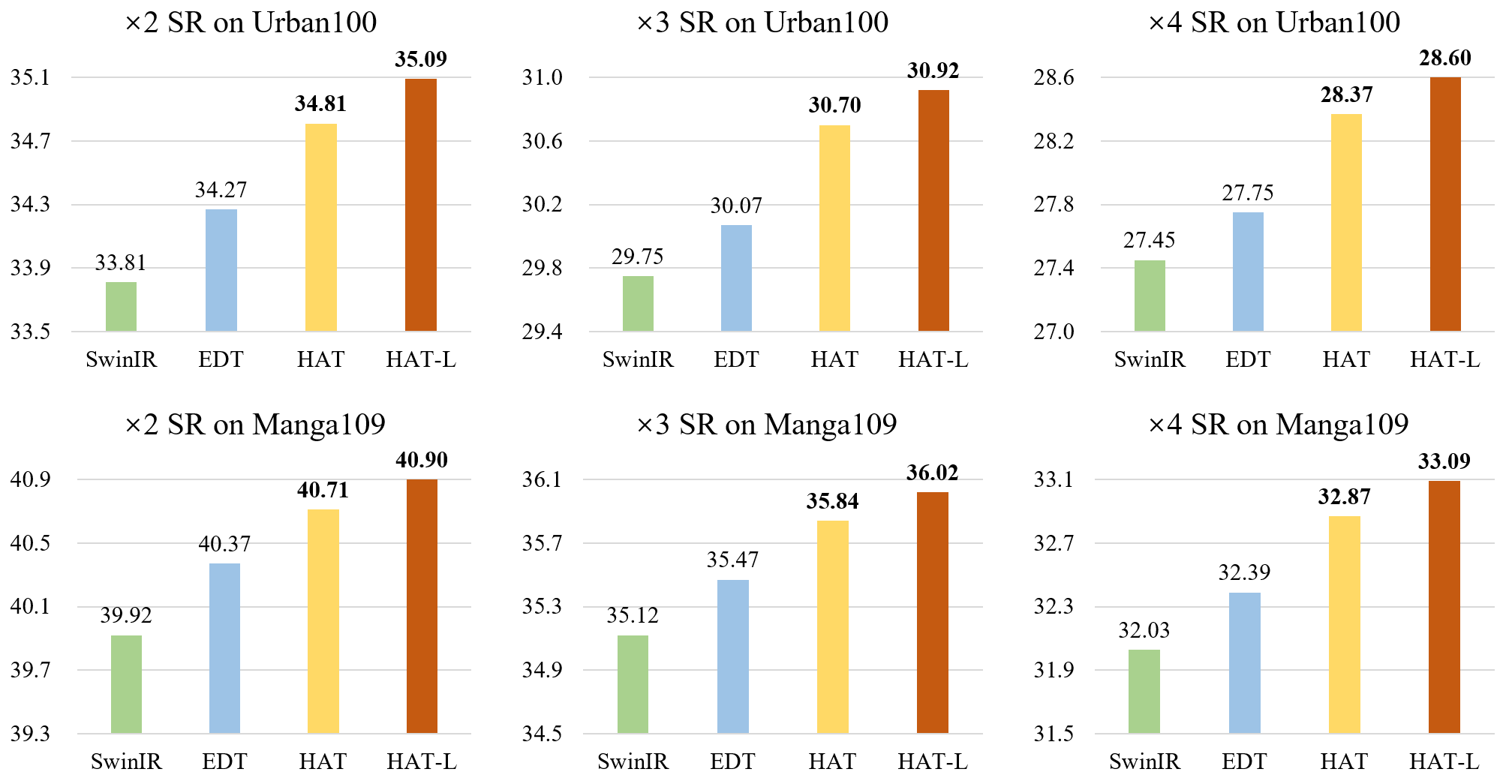
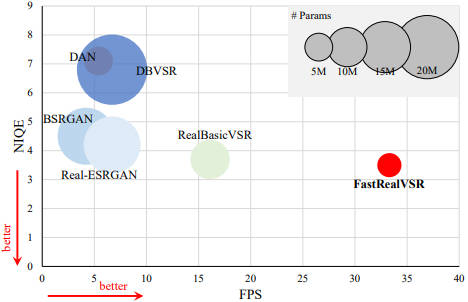
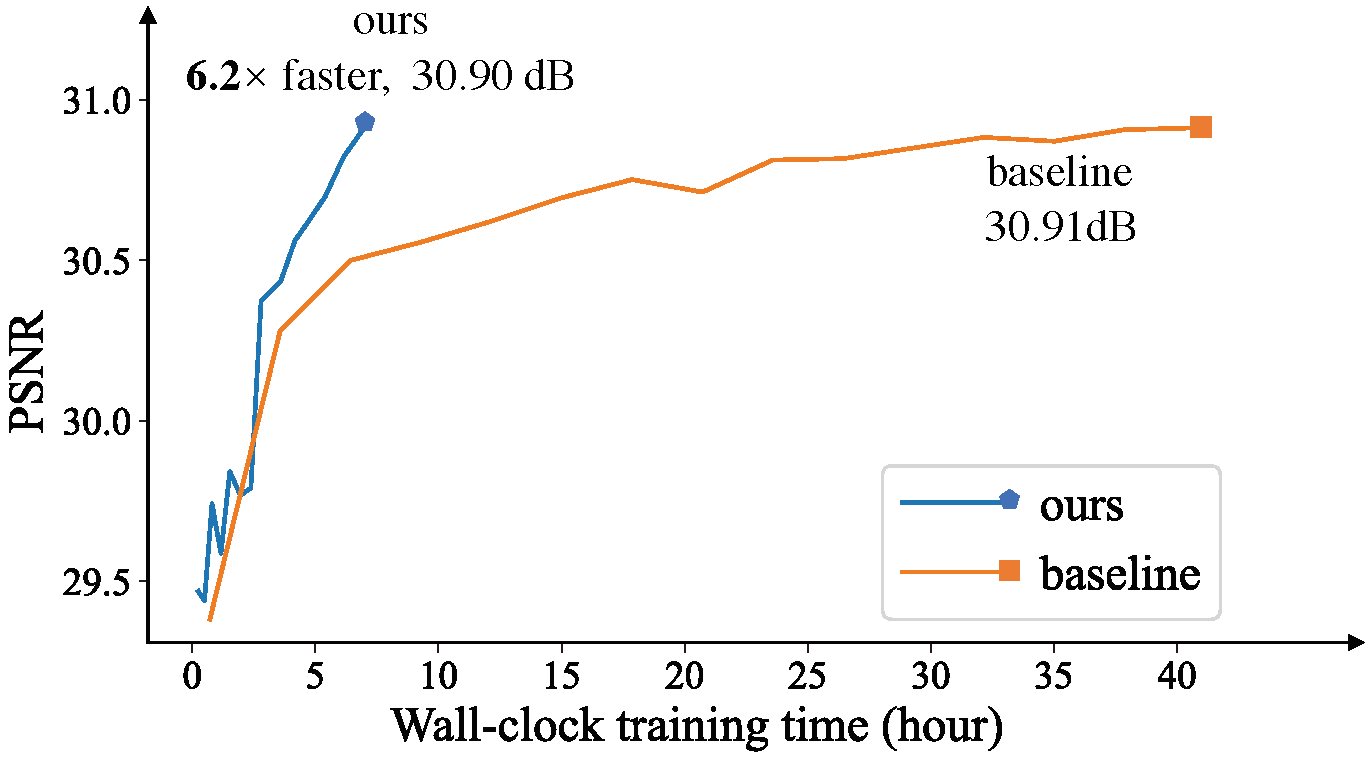
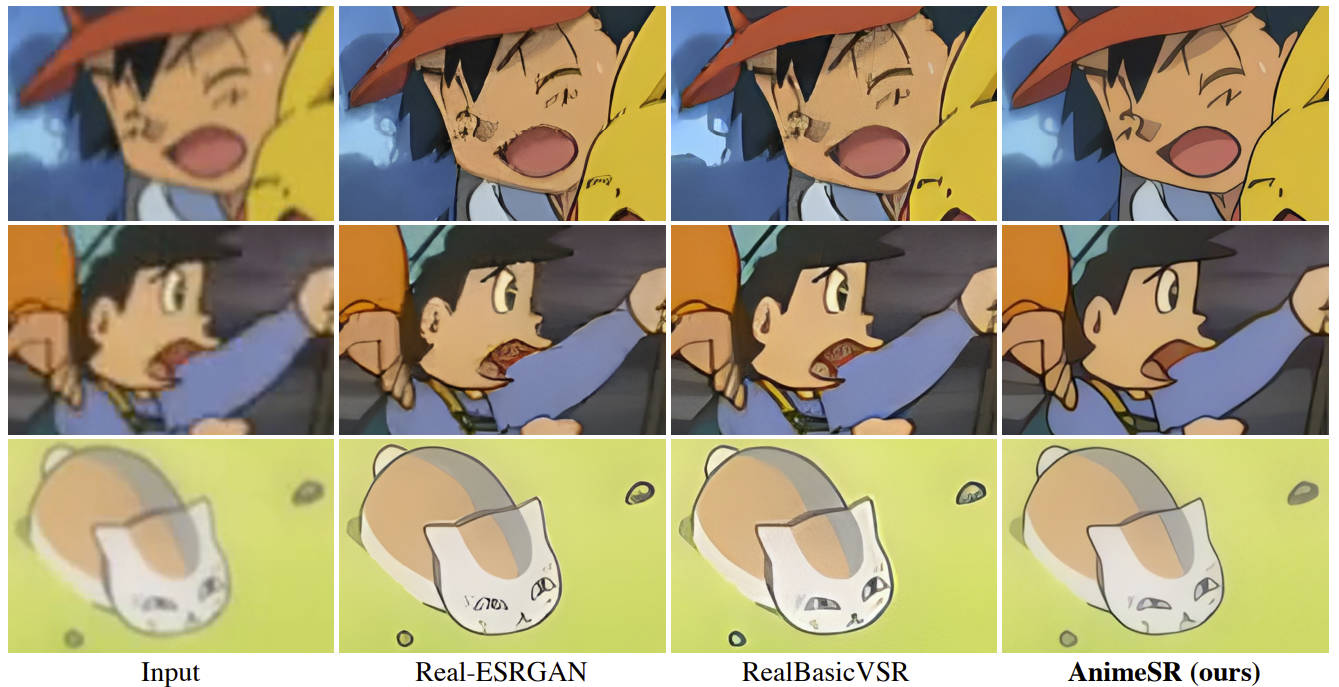
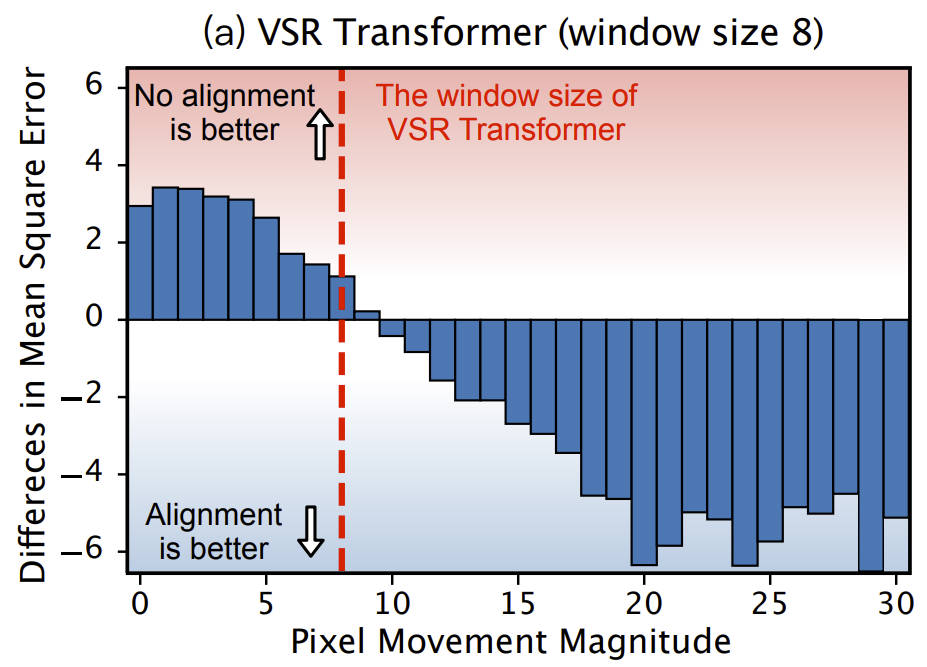
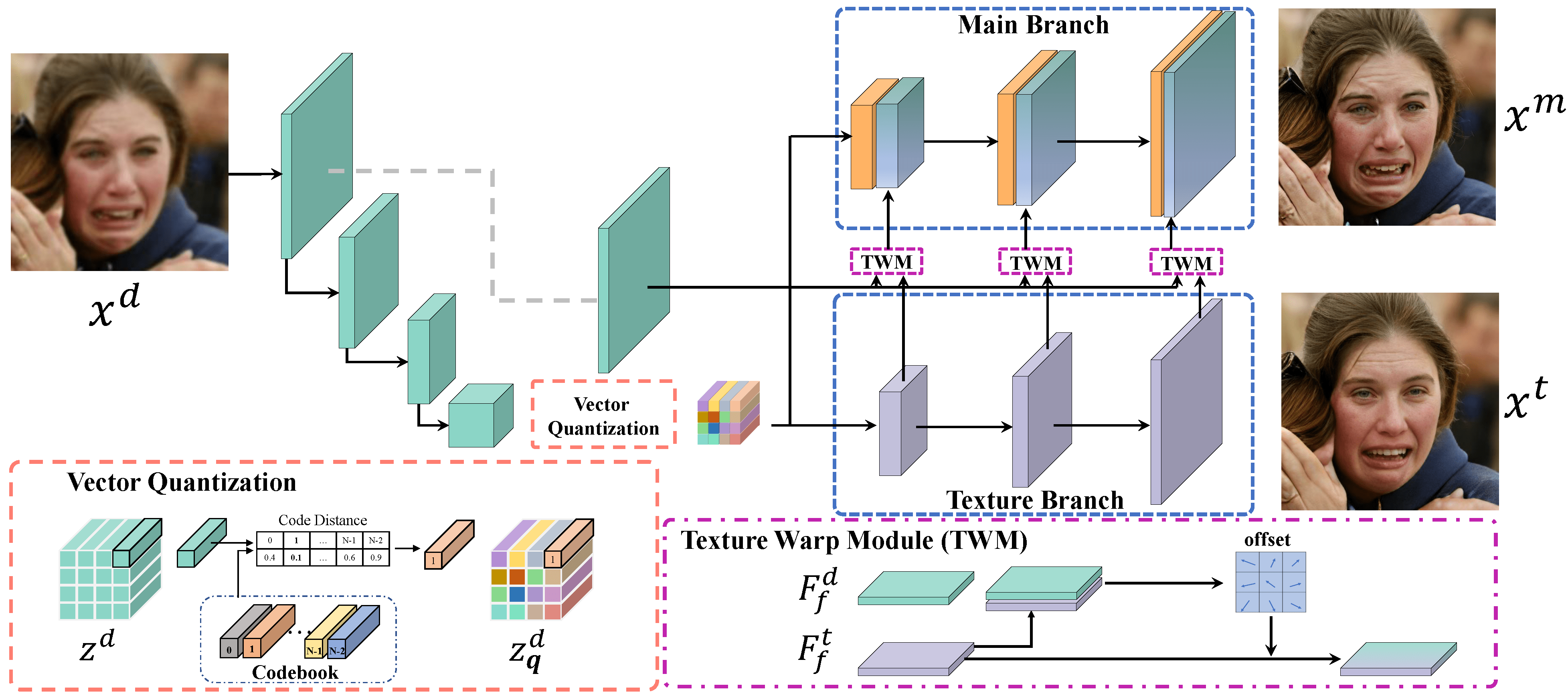
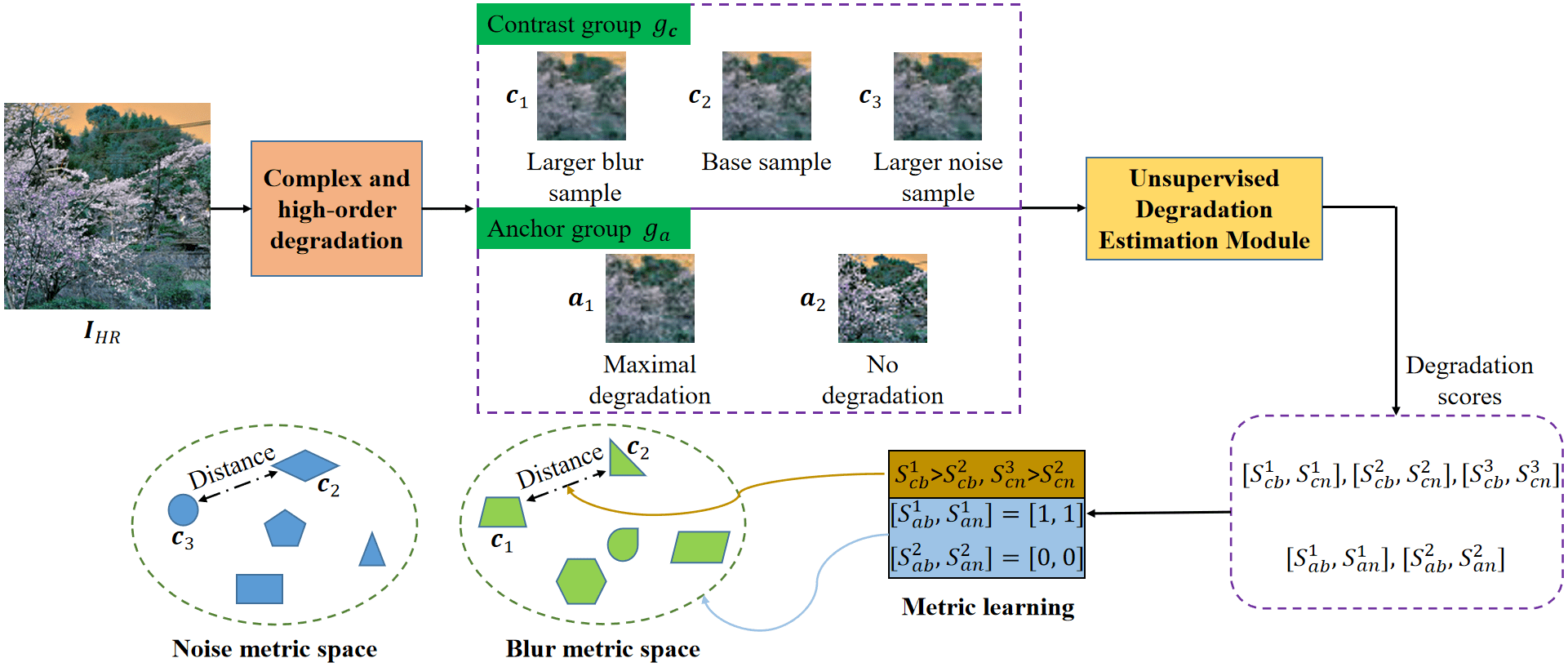
2021


2020 and before
To be updated