デジタルヒューマンと Amazon Bedrock で召喚!バーチャル事務職員 | 【第1回】デジタルヒューマンとチャットボットを連携させよう (original) (raw)
はじめに
はじめまして!株式会社クロスパワー クラウドシステム開発部の N です。 現在弊社では生成 AI を活用したシステムやアプリケーションの開発に精力的に取り組んでいます。
その活動の一環としてデジタルヒューマン株式会社様の協力のもと、社内規定や事務手続きの方法に関連する質問に答えてくれるバーチャル事務職員のプロトタイプを作成しました。

バーチャル事務職員のプロトタイプ
実際に動作する様子はこちらです。
本ブログでは全4回(予定)に渡ってこのようなバーチャル事務職員を実装する手順について解説します。 その中で生成 AI を活用するアプリケーション開発に関わる基本的な知識も紹介していきます。
本記事の対象読者は次のような方を想定しています。
- デジタルヒューマン (仮想の人物との会話) に興味がある
- AWS の生成 AI プラットフォーム (特に Amazon Bedrock) に興味がある
- 生成 AI を活用したアプリケーション開発に興味がある
第1回ではまずデジタルヒューマンとは何かを説明します。 その後 AWS 上でシンプルなチャットボット API を構築してデジタルヒューマンと連携させるところまでの手順を解説していきます。
目次
デジタルヒューマンとは
一般に「デジタルヒューマン」とは仮想空間上で表現される人物及びそのような表現を実現する技術のことを指します。 「3Dアバター」のような言葉に比べて本物の人間と遜色ないレベルの写実的な人物表現を指す場面が多いようです。 近年では実在する(あるいは実在した)俳優をCGとして映像に登場させること事例が増えてきました。 また映像業界に限らず、金融、医療、小売業等といった幅広い分野でデジタルヒューマンが活用される事例が増加しています。
本記事で取り上げるデジタルヒューマンとはニュージーランドに本社を置く UneeQ 社 (日本国内ではデジタルヒューマン株式会社) が展開するデジタルヒューマンを用いた会話プラットフォームです。
このデジタルヒューマンプラットフォームはユーザーから入力された音声の文字起こし (Speech-to-Text) と回答文からデジタルヒューマンの映像と音声の生成を担います。 開発者が用意するデジタルヒューマンを表示するフロントエンドと回答文を生成するバックエンドと連携させることで、デジタルヒューマンと会話を実現するプラットフォームを構築することができます。
デジタルヒューマン公式サイトでは実際にデジタルヒューマンと会話できるデモが公開されているので、まずはそちらを体験してみることをおすすめします。
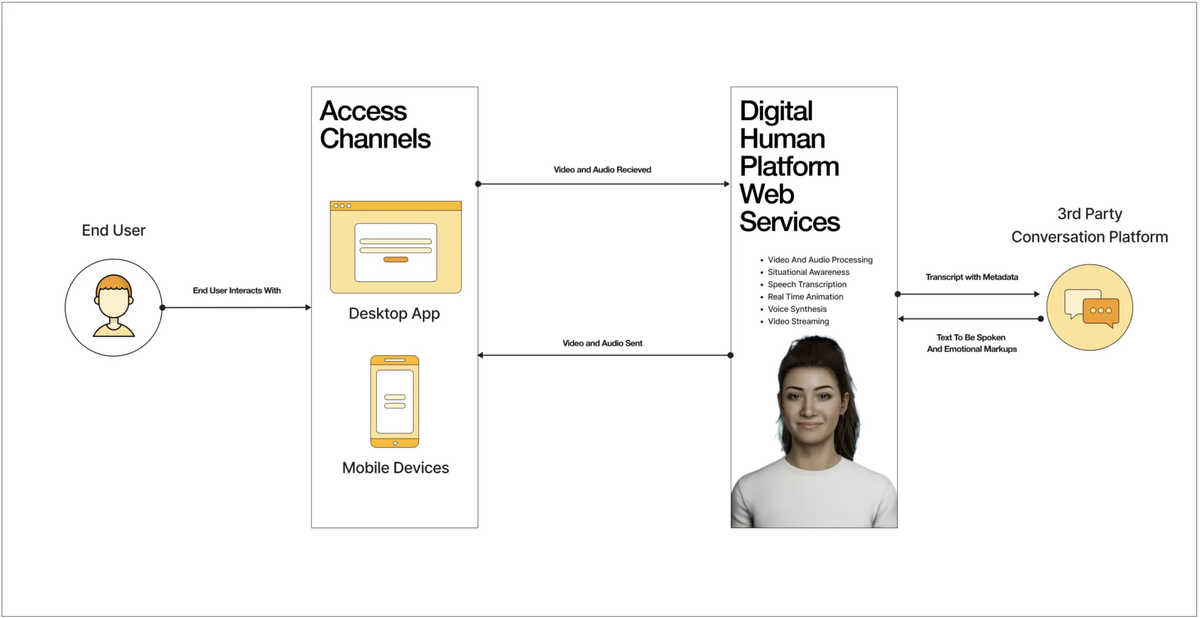
デジタルヒューマンプラットフォームの概要 (プラットフォームの概要 – ヘルプセンター | デジタルヒューマンより引用)
このデジタルヒューマンプラットフォームの特徴は何と言っても他のチャットボットの統合のしやすさです。
前述の通り音声や映像周りの処理はデジタルヒューマン側で完結しているので、開発者は基本的にはテキストベースのチャットボットを実装するだけで済みます。 データのやり取りもシンプルな REST API を利用しているのでチャットボットが動作するバックエンドのプラットフォームを限定しません。
また、表示する3Dモデルや音声認識・生成モデルを用途に応じてカスタマイズすることも可能です。詳細はデジタルヒューマンのヘルプセンターをご参照ください。
この度デジタルヒューマン株式会社様のご厚意のもとこのデジタルヒューマンを試用する機会を設けていただきました。 デジタルヒューマン株式会社様にはこの場を借りてお礼申し上げます。
開発環境
リージョンについて補足です。
AWS の生成 AI 関連のサービスのほとんどは us-east-1 から展開されるので最新の機能に触れたいのであれば us-east-1 リージョン上にアプリケーションを構築することをおすすめします。 本記事で利用するサービスの範囲であれば ap-northeast-1 アジアパシフィック(東京)リージョンに開発環境を置くことも可能です。
アプリケーションの概要
第1回では AWS 上で LLM を用いたチャットボット API を構築しデジタルヒューマンと連携させるところまでを実装していきます。
アプリケーション全体の構成は次のようになります。
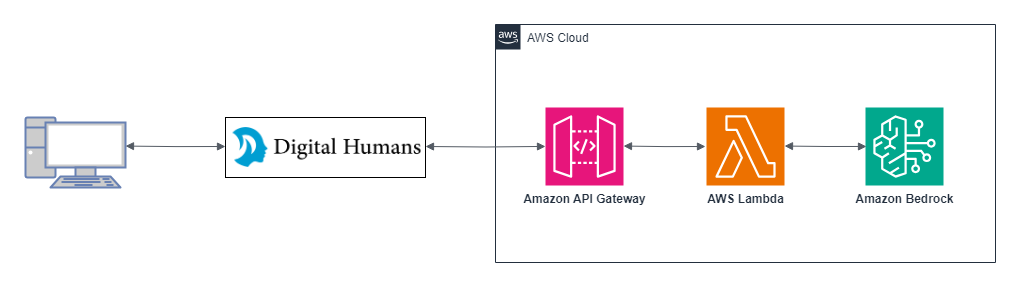
アプリケーション構成図
デジタルヒューマンは HTML ファイルのヘッダー内で特定のスクリプトを読み込むことで任意の Web ページで表示することが可能です。
今回のトライアルではデジタルヒューマン株式会社様の方でフロントエンドの Web ページを用意していただいたので、こちらはバックエンドとなるチャットボット API のみ AWS 上で実装する形となりました。
実装する手順は次のようになります。
- Lambda 関数で利用するモジュールを格納する Lambda レイヤーを作成する。
- Amazon Bedrock のベースモデルへのアクセスをリクエストする。
- チャットボット本体となる Lambda 関数を作成して初期設定をする。
- 3 の Lambda 関数を編集して入力された質問への回答文を生成して返す処理を実装する。
- 3 で作成した Lambda 関数を呼び出す API を公開する API Gateway を設定する。
3 以降で実装する Lambda 関数は LangChain というフレームワークのモジュールを用いて Amazon Bedrock の LLM を実行します。
LangChain や Amazon Bedrock については、本ブログの過去の記事の『Amazon BedrockとLangChain(LCEL記法)によるLLMアプリケーション開発ことはじめ』で詳しく解説されているのでぜひそちらを参照してください。
アプリケーションの実装
1. Lambda レイヤーの作成
Lambda 関数の実行に必要なモジュールを格納する Lambda レイヤーを作成していきます。
アプリケーションの開発中は Cloud9 を利用していたのですが2024年7月25日から新規利用が停止してしまいました。
代替手段として AWS CloudShell を用いた方法で Lambda レイヤーを作成します。
AWS コンソールから AWS CloudShell を開きます。
まずは作業用のディレクトリを作成してその中へ移動しましょう。
$ mkdir chatbot-lambda-layer $ cd chatbot-lambda-layer
お好みのテキストエディタで requirements.txt を作成します。
$ nano requirements.txt
requirements.txt の中身は次の通りです。
langchain==0.2.0 langchain-aws==0.1.4 langchain-community==0.2.0 python-dateutil==2.8.2
モジュールのインストール先のディレクトリを作成しモジュールをインストールします。
$ mkdir python $ pip install -r requirements.txt -t ./python
boto 系のモジュールは Lambda ランタイム環境にプリインストールされているのでレイヤーからは除外します。
$ rm -r ./python/boto*
モジュールをインストールしたディレクトリをzip圧縮します。
$ zip -r layer_content.zip ./python
AWS CLI を用いて Lambda レイヤーを作成します。
$ aws lambda publish-layer-version --layer-name chatobot-lambda-layer --zip-file fileb://layer_content.zip --compatible-runtimes python3.9 --compatible-architectures "x86_64"
AWS コンソールから Lambda レイヤーが正しく作成されたことを確認します。
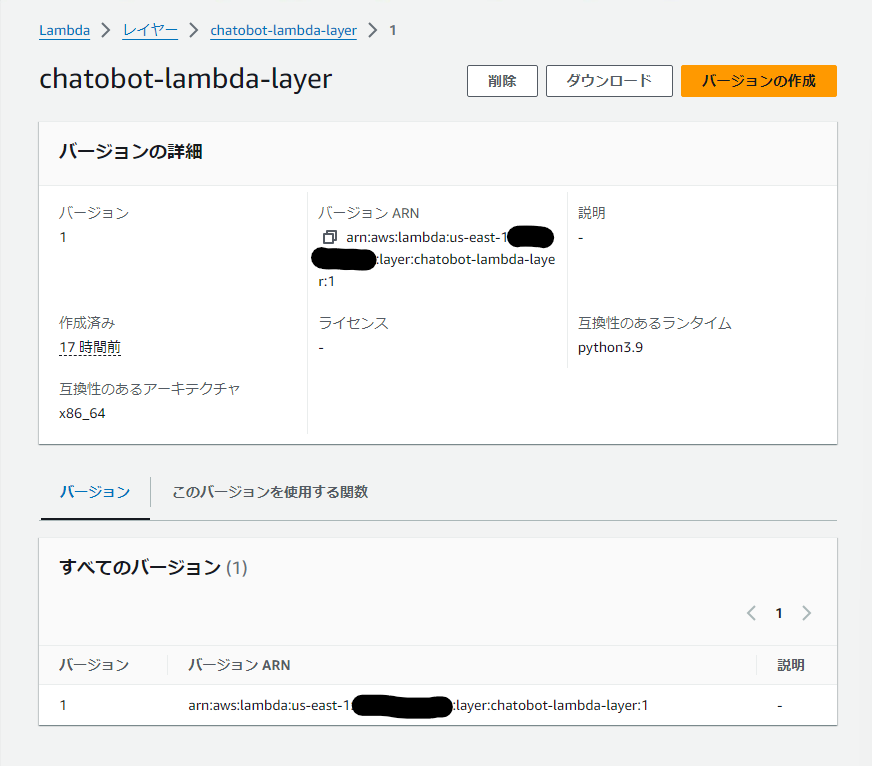
2. Amazon Bedrock ベースモデルへのアクセスのリクエスト
今回のアプリケーションでは Amazon Bedrock のベースモデルの1つである Anthropic Claude 3.5 Sonnet を利用します。 そのためには事前にこのモデルへのアクセスをリクエストしてアクセス権を取得しておく必要があります。
まずは Amazon Bedrock コンソールのメニューから「Bedrock configurations」の中の「モデルアクセス」を選択します。
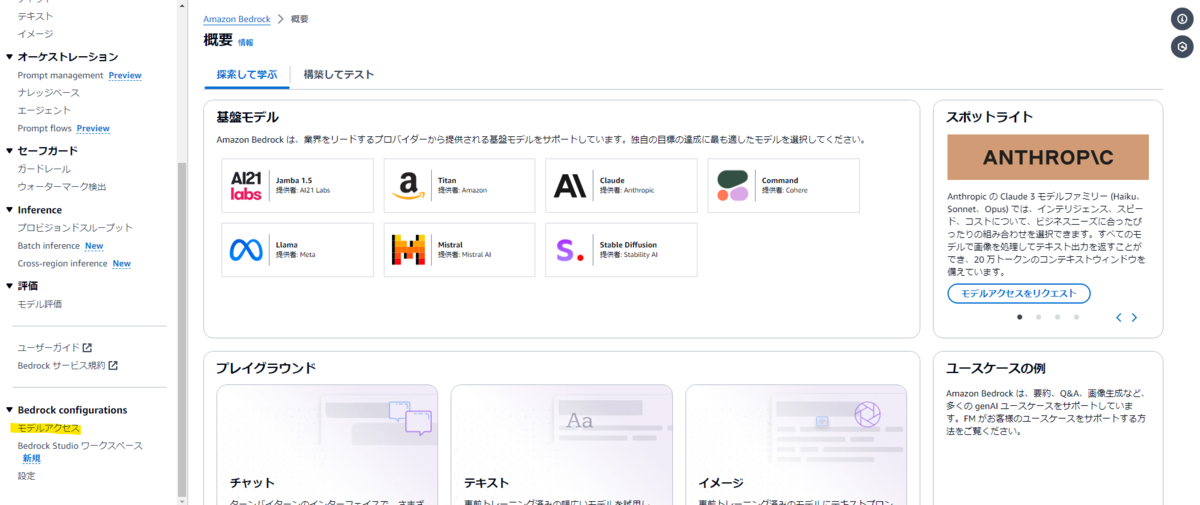
表示されるベースモデルの一覧から Anthropic Claude 3.5 Sonnet の「リクエスト可能」を選択します。
表示されるポップアップメニューの「モデルアクセスをリクエスト」を選択します。
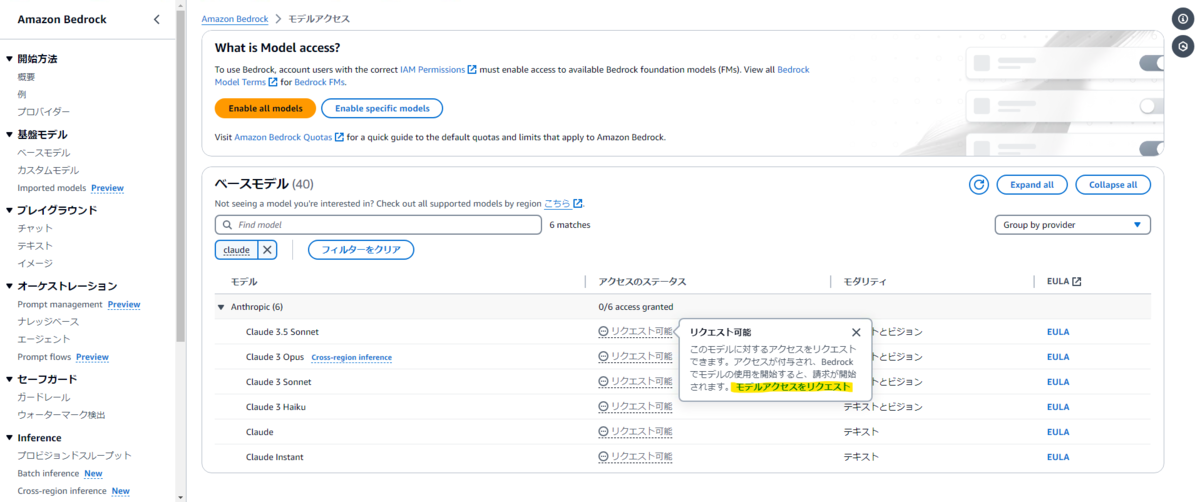
Anthropic Claude 3.5 Sonnet にチェックが入っていることを確認して「Next」を選択します。
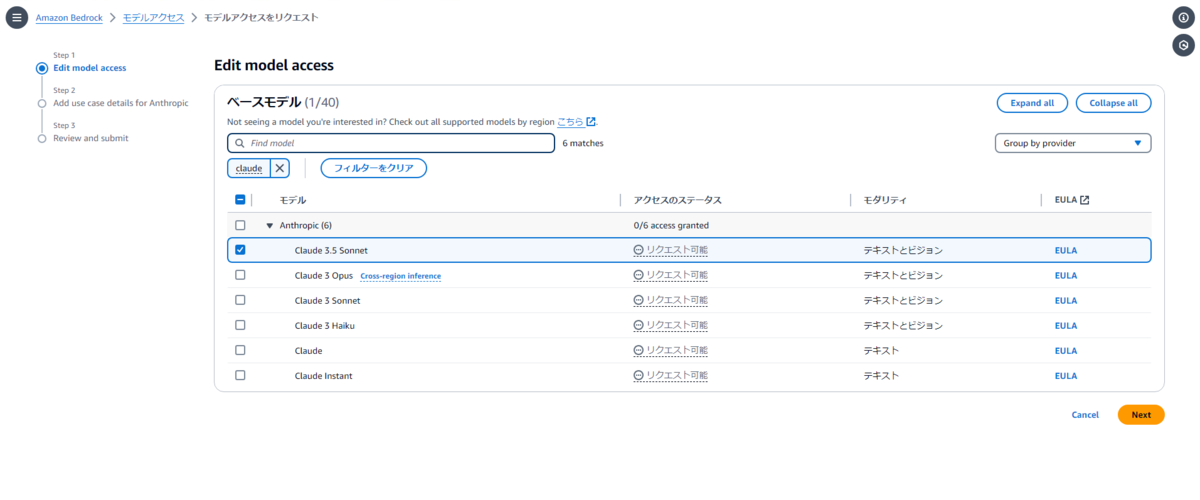
モデルの使用用途を入力して「Next」を選択します。
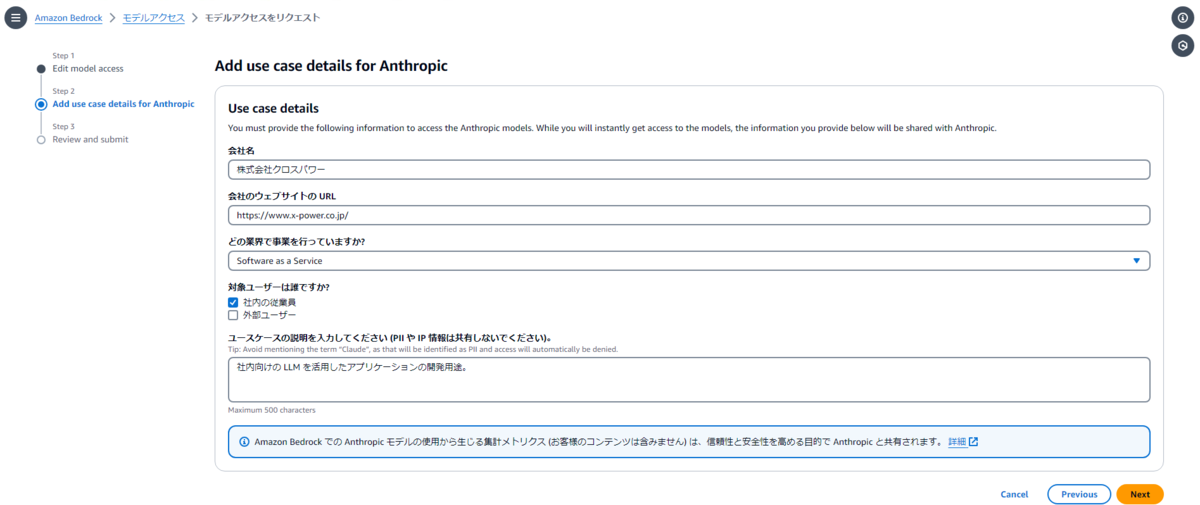
最後に入力内容の確認をすればリクエスト処理は完了です。
しばらくすればモデルへのアクセス権が付与されるはずです。
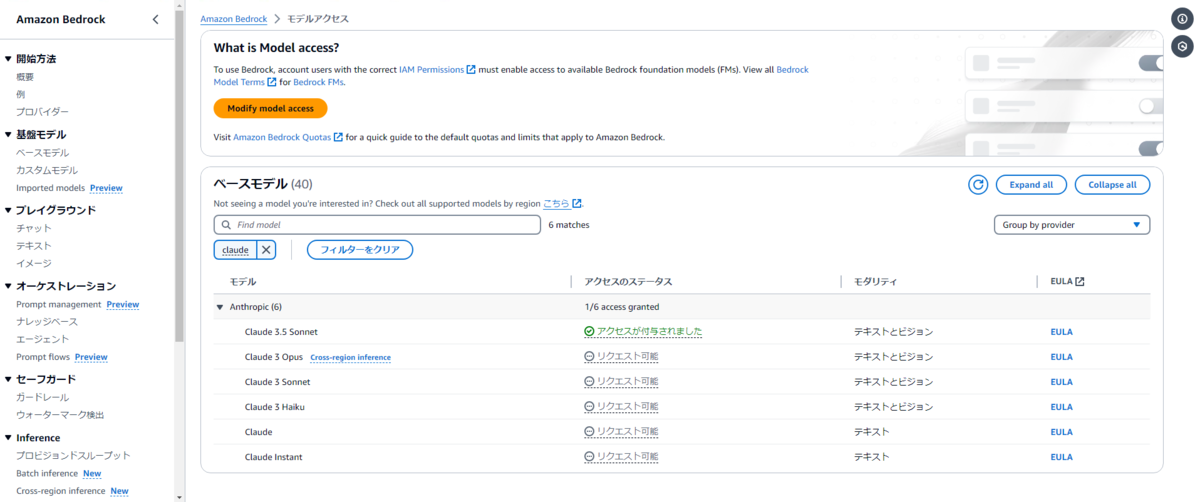
3. Lambda 関数の作成と設定
3-1. Lambda 関数の作成
チャットボットの本体となる Lambda 関数を作成と初期設定をしていきます。
まずは AWS Lambda コンソールから「関数の作成」を選択します。
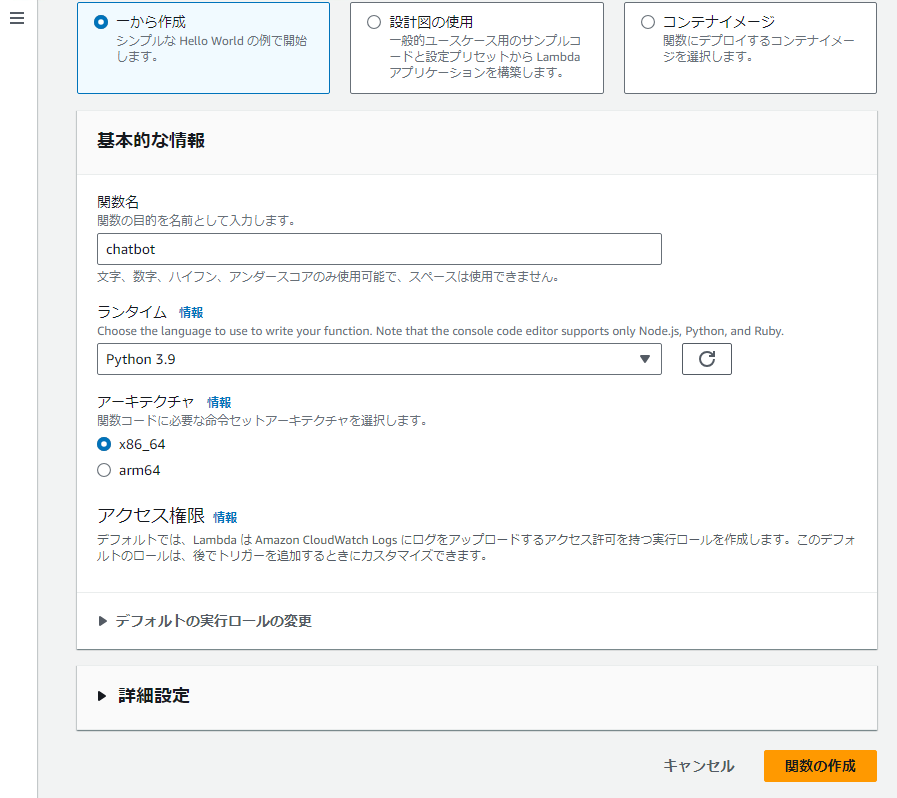
関数名を chatbot に、ランタイムを Python 3.9 にアーキテクチャを x86_64 に設定したら「関数の作成」を選択します。
これで Lambda 関数の作成は完了です。
3-2. Lambda レイヤーの追加
1 で作成した Lambda レイヤーを関数に追加しましょう。
作成した Lambda 関数の「コード」タブ下部の「レイヤー」内の「レイヤーの追加」を選択します。

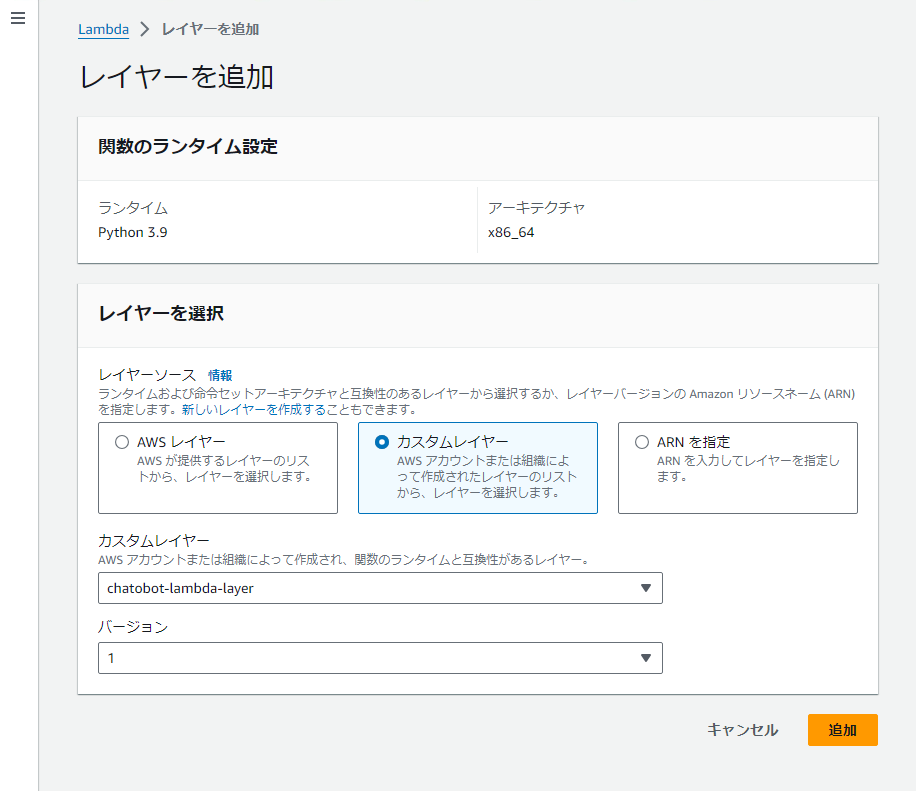
「カスタムレイヤー」を選択します。
カスタムレイヤーは 1 で作成した chatbot-lambda-layer を、バージョンは特に理由がなければ最新のものを選択します。
最後に「追加」を選択します。
3-3. Lambda 関数の各種設定
「設定」タブを選択したら表示される一般設定の「編集」を選択します。
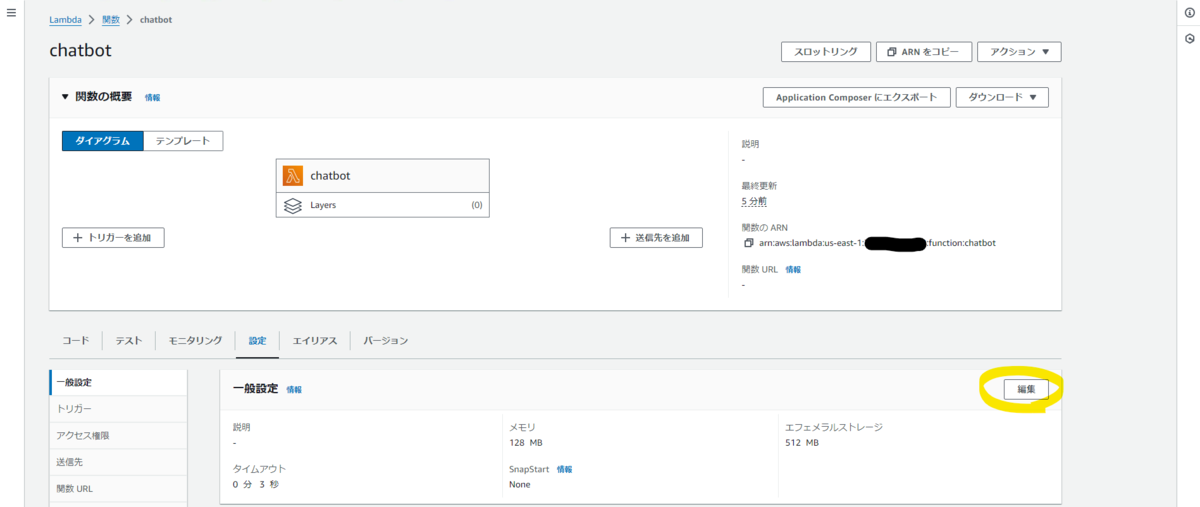
メモリを 128 MB から 256 MB に、タイムアウトを 3 秒 から 1 分 に変更して「保存」を選択します。
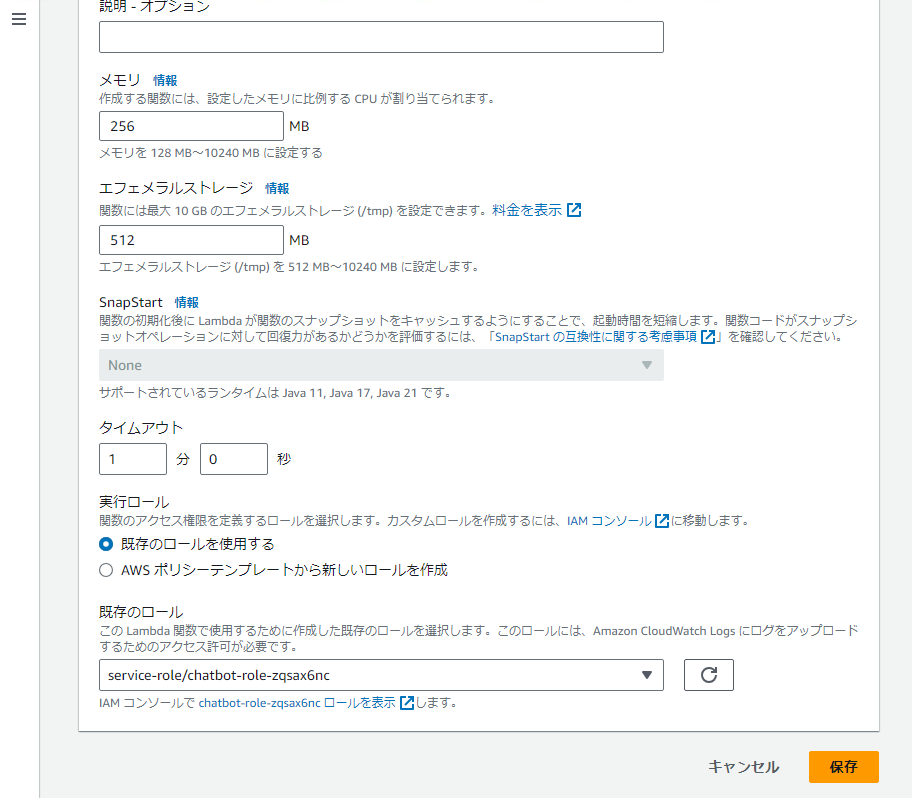
次に Lambda 関数の実行ロールを編集して Amazon Bedrock へのアクセス権限を付与します。
「設定」タブの「アクセス権限」ページ内「実行ロール」の「ロール名」の下のリンクを選択して IAM コンソールを開きます。
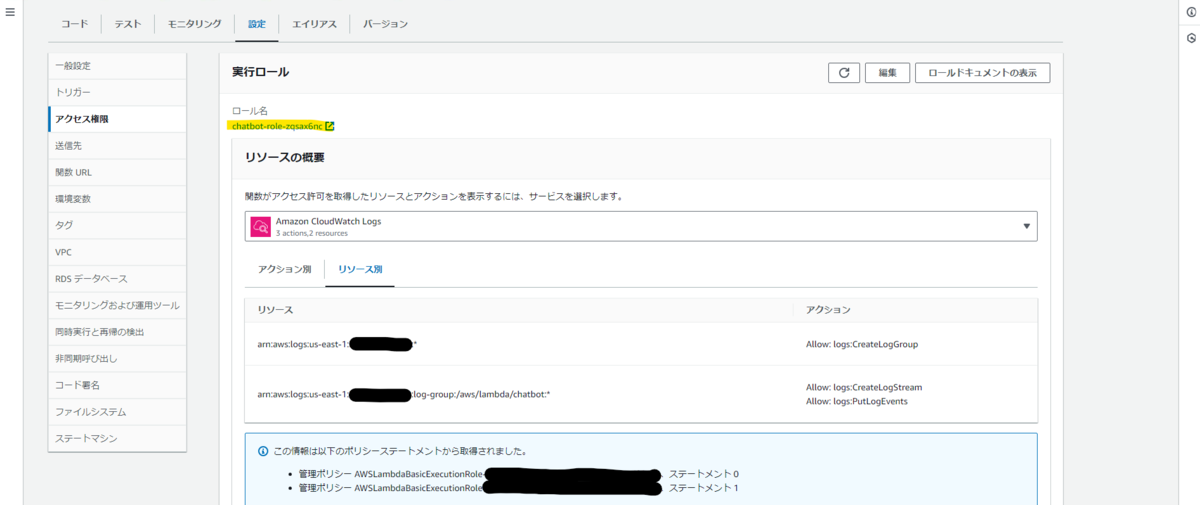
「許可ポリシー」の「許可を追加」を選択したら表示されるメニューから「ポリシーをアタッチ」を選択します。
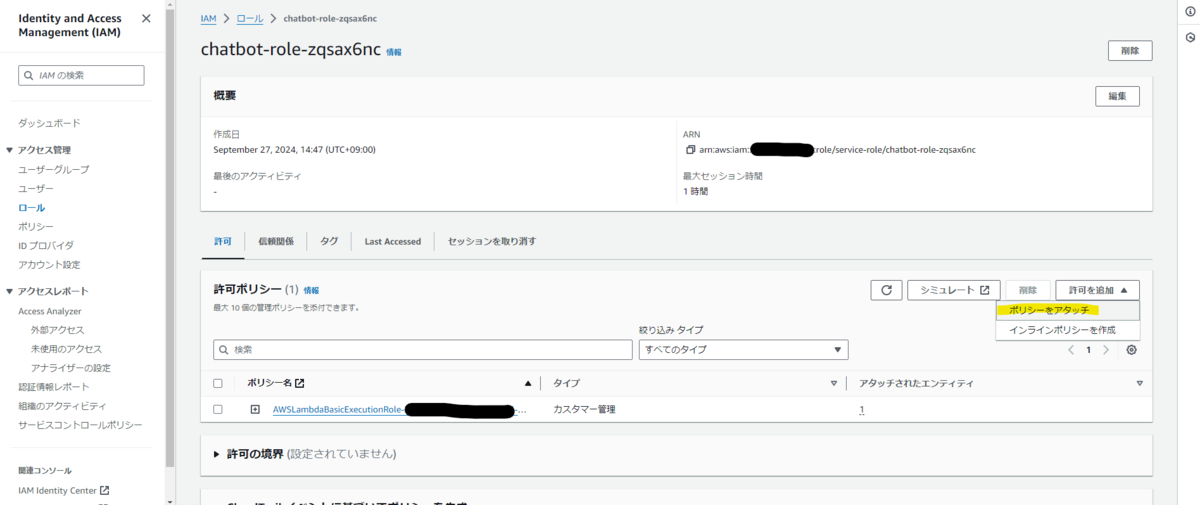
「その他の許可ポリシー」から AmazonBedrockFullAccess にチェックを入れて「許可を追加」を選択します。
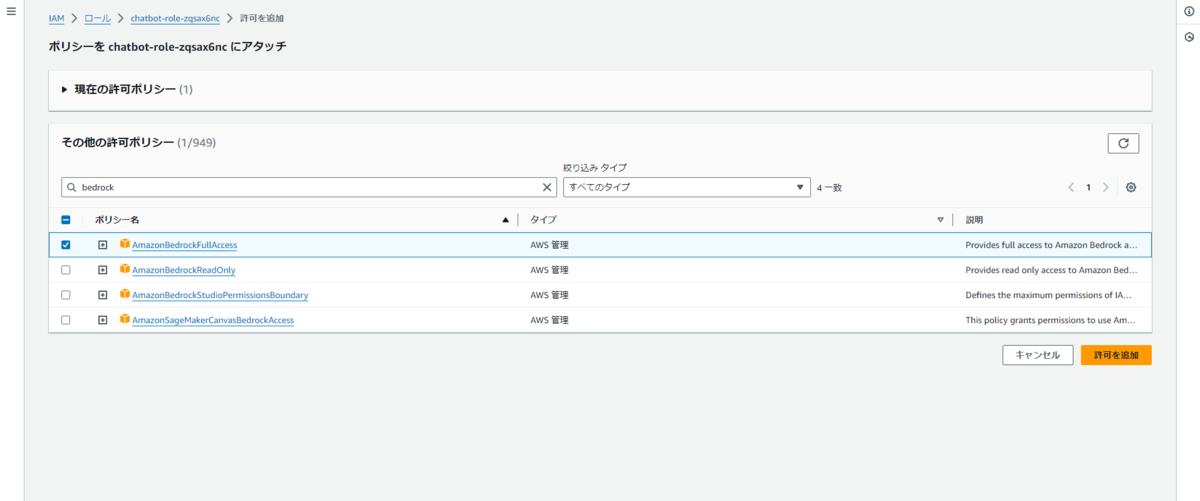
これで Lambda 関数から Amazon Bedrock のベースモデルの機能を呼び出すことができるようになりました。
4. 回答文生成処理の実装
3 で作成した Lambda 関数のコードを編集してデジタルヒューマンプラットフォームから受け取った質問文から回答文を生成する処理を実装していきます。
「コード」タブを開いて lambda_function.py を次のように編集します。 なお、説明の簡単のためエラーハンドリング等の一部の処理の記述は省略しています。
import json
from langchain_aws import ChatBedrock
def lambda_handler(event, context):
body = json.loads(event["body"])
question = body["fm-question"]
llm = ChatBedrock(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
model_kwargs={"max_tokens": 1000},
)
response = llm.invoke(question)
res_body = {
"answer": json.dumps({
"answer": response.content,
"instructions": {},
}, ensure_ascii=False),
"matchedContext": "",
"conversationPayload": "{}",
}
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps(res_body, ensure_ascii=False),
}コードの内容を解説していきます。
from langchain_aws import ChatBedrock
ここで Lambda レイヤーとして追加した LangChain モジュールをインポートしています。
def lambda_handler(event, context):
body = json.loads(event["body"])
question = body["fm-question"]API Gateway を介して受け取ったデジタルヒューマンプラットフォームからの入力から質問文の文字列を抽出して変数 question へ格納します。
デジタルヒューマンプラットフォームからのリクエストの仕様はヘルプセンターのチャットボット・会話AIとのインテグレーションの概要 - リクエストの仕様を参照してください。
llm = ChatBedrock(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
model_kwargs={"max_tokens": 1000},
)呼び出す LLM の ID や設定を指定して LLM オブジェクトを作成します。
response = llm.invoke(question)質問文を入力として LLM を呼び出して回答文を生成し response 変数へ格納します。
res_body = {
"answer": json.dumps({
"answer": response.content,
"instructions": {},
}, ensure_ascii=False),
"matchedContext": "",
"conversationPayload": "{}",
}
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps(res_body, ensure_ascii=False),
}ヘルプセンターのチャットボット・会話AIとのインテグレーションの概要 - レスポンスの仕様に則ったレスポンスを生成して返します。
5. API Gateway の設定
実装した Lambda 関数をデジタルヒューマンプラットフォームが呼び出すための API を API Gateway を用いて構成していきましょう。
Amazon API Gateway コンソールを開いて REST API の「構築」を選択します。
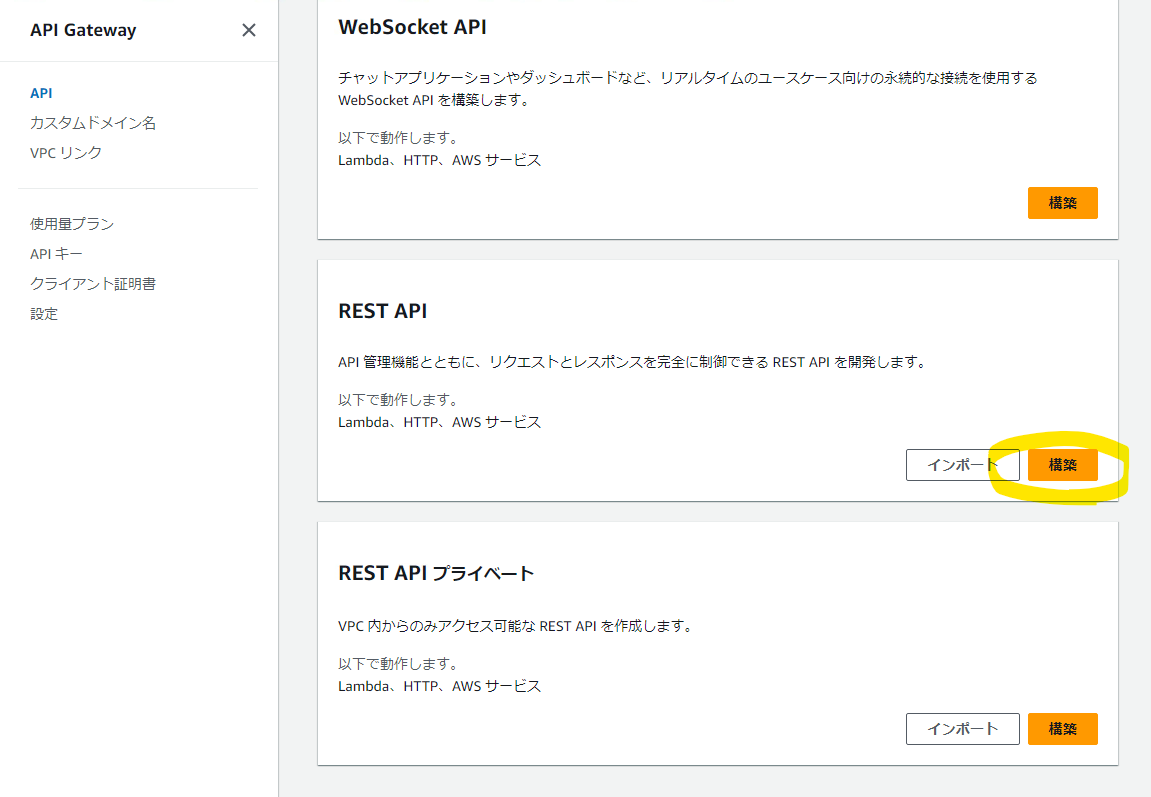
API 名を ChatbotApi に設定して「API を作成」を選択します。
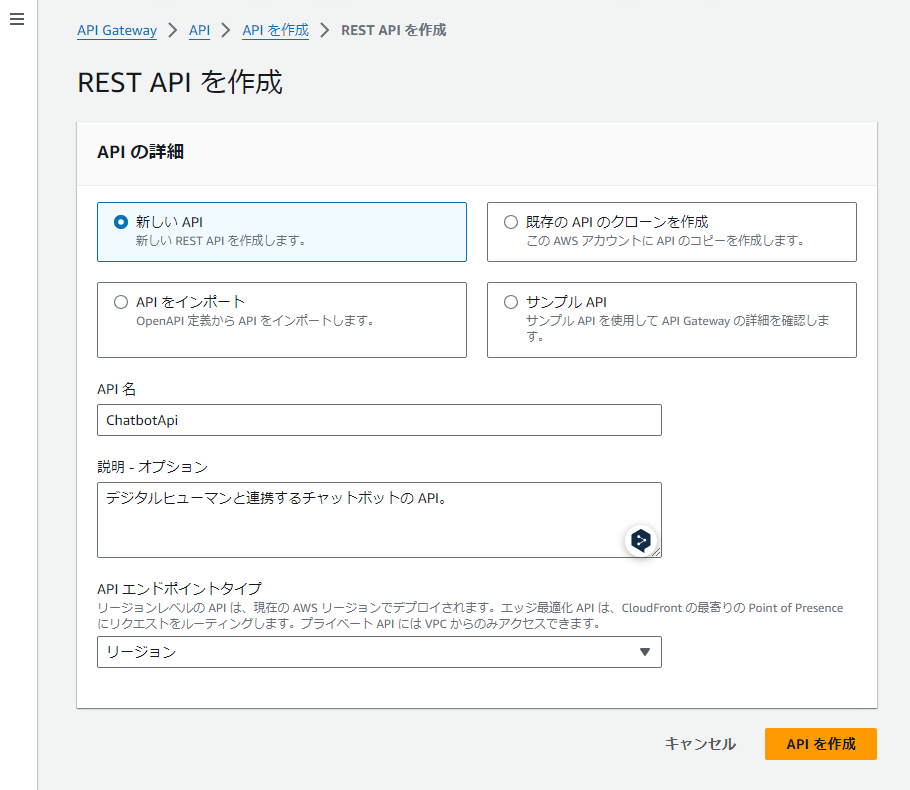
次に作成した API にメソッドを追加して Lambda 関数と紐づけていきます。
「リソース」ページの「メソッドを作成」を選択します。
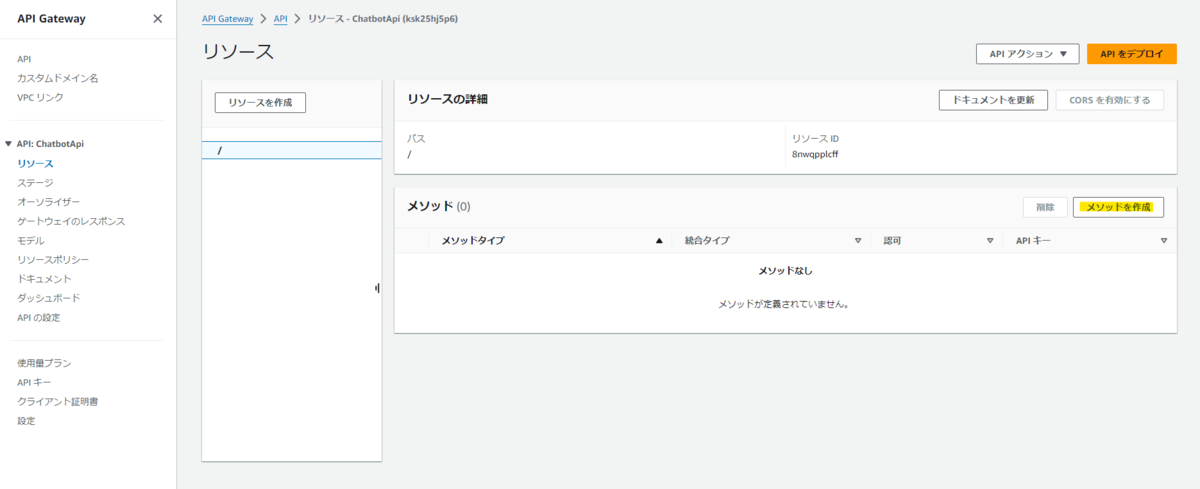
メソッドタイプを POST に、統合タイプを Lambda 関数 に設定して Lambda プロキシ統合を有効化します。
Lambda 関数に 3, 4 で作成した Lambda 関数を指定して「メソッドを作成」を選択します。
メソッドを作成したら API をデプロイしましょう。
「リソース」ページの「API をデプロイ」を選択します。
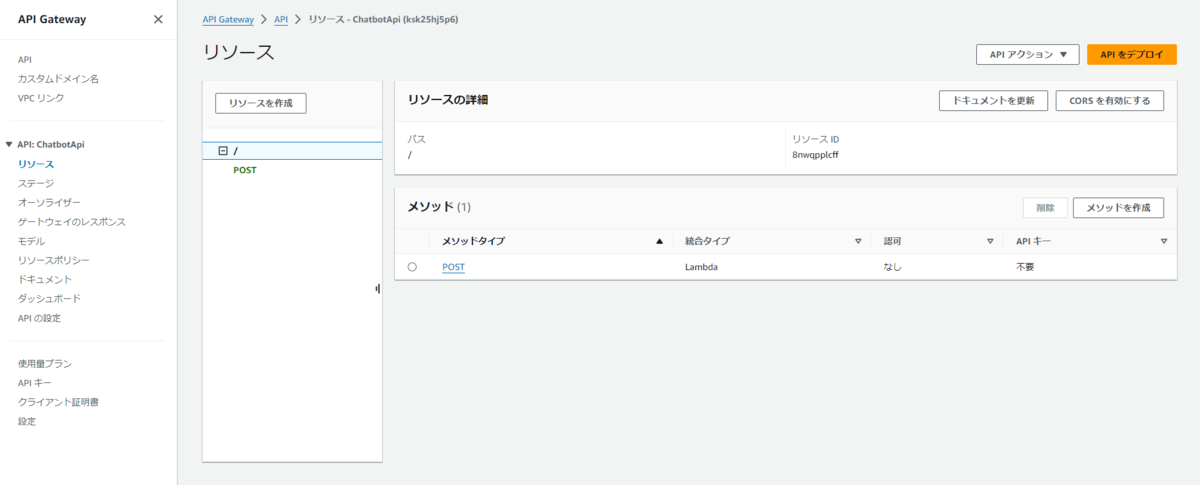
ステージに 新しいステージ を設定してステージ名には devを入力し「デプロイ」を選択します。
これで API を外部から呼び出すことが可能になりました。
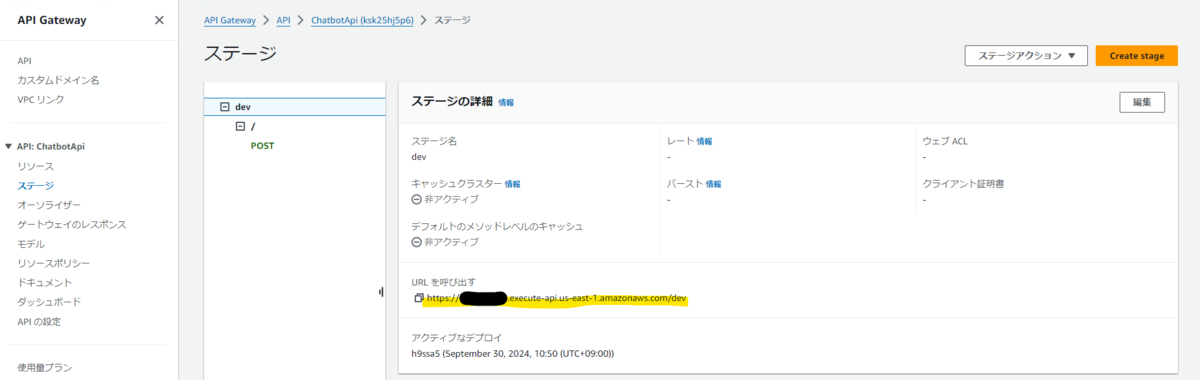
「ステージ」のページから API の URL の情報を取得できます。
動作確認
実際に API を呼び出してみましょう。
CloudShell を開いて次の JSON 文字列を request.json というファイル名で保存します。
{ "sid": "18220511-b8bb-4164-9d43-dcf4e33e07b1", "fm-custom-data": "{}", "fm-question": "こんにちは、質問させてください。", "fm-conversation":"{}", "fm-avatar": "{"type":"WELCOME", "avatarSessionId": "5d8e685f-aa66-4fa4-9e1b-37365d497314"}", "fm-metadata": "{"userSpokenLocale":"en-AU","browserDetectedLocales":"en-GB", "userTimezone":"Pacific/Auckland","userScreenWidth":1977,"userScreenHeight":1343,"userAgent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"},"custom":"{\"putWhateverYouWant\":\"anyValue\"}"}" }
$ curl -i -X POST -H "Content-Type:application/json" -d @request.json "{前節で設定した API の URL}"
問題がなければ次のようなレスポンスが返ってきます。
HTTP/2 200 date: Mon, 30 Sep 2024 02:06:27 GMT content-type: application/json content-length: 237 x-amzn-requestid: cf0d2d8c-acef-4354-a419-62a8e80dbe83 x-amz-apigw-id: e5YgzFCGoAMEhyA= x-amzn-trace-id: Root=1-66fa079e-66daaec66ea98eef5da31ed5;Parent=62e8d3d487916ae9;Sampled=0;Lineage=1:d3115e38:0
{"answer": "{"answer": "はい、どうぞ。どのようなご質問でしょうか?お手伝いできることがあれば喜んでお答えします。", "instructions": {}}", "matchedContext": "", "conversationPayload
この API の URL 情報をデジタルヒューマン株式会社様に連絡することでデジタルヒューマンプラットフォームとの連携の手続きを進めてもらえます。 連携完了後にデジタルヒューマンのフロントエンドにアクセスすれば、今回実装したチャットボットをバックエンドとするデジタルヒューマンと会話できるはずです。
おわりに
第1回ではデジタルヒューマンと AWS 上に構築したチャットボットを連携させるところまでの手順を解説しました。
デジタルヒューマンプラットフォームや Amazon Bedrock を利用することで手早くデジタルヒューマンと会話できる環境を構築できることを知っていただけたと思います。
次回は自然な会話を実現するためにチャットボットに会話履歴機能を追加する手順について解説していきます。 また、プロンプト (生成 AI へ与える命令文) を工夫することでより事務員らしく振る舞うように調整する手法についても説明します。
次回以降もどうぞよろしくお願いします。