 |
Knowledge augmented instruction tuning for zero-shot animal species recognition Zalan Fabian,Zhongqi Miao,Chunyuan Li,Yuanhan Zhang,Ziwei Liu,Andrés Hernández,Andrés Montes-Rojas,Rafael Escucha,Laura Siabatto, Andrés Link, Pablo Arbeláez,Rahul Dodhia, Juan Lavista Ferres Instruction Tuning and Instruction Following Workshop@NeurIPS 2023. PDF A knowledge augmented vision-language model for AI conservation. |
 |
What Makes Good Examples for Visual In-Context Learning? Yuanhan Zhang,Kaiyang Zhou, Ziwei Liu NeurIPS, 2023 PDF / Code  Retrieving prompt for visual in-context learning. Retrieving prompt for visual in-context learning. |
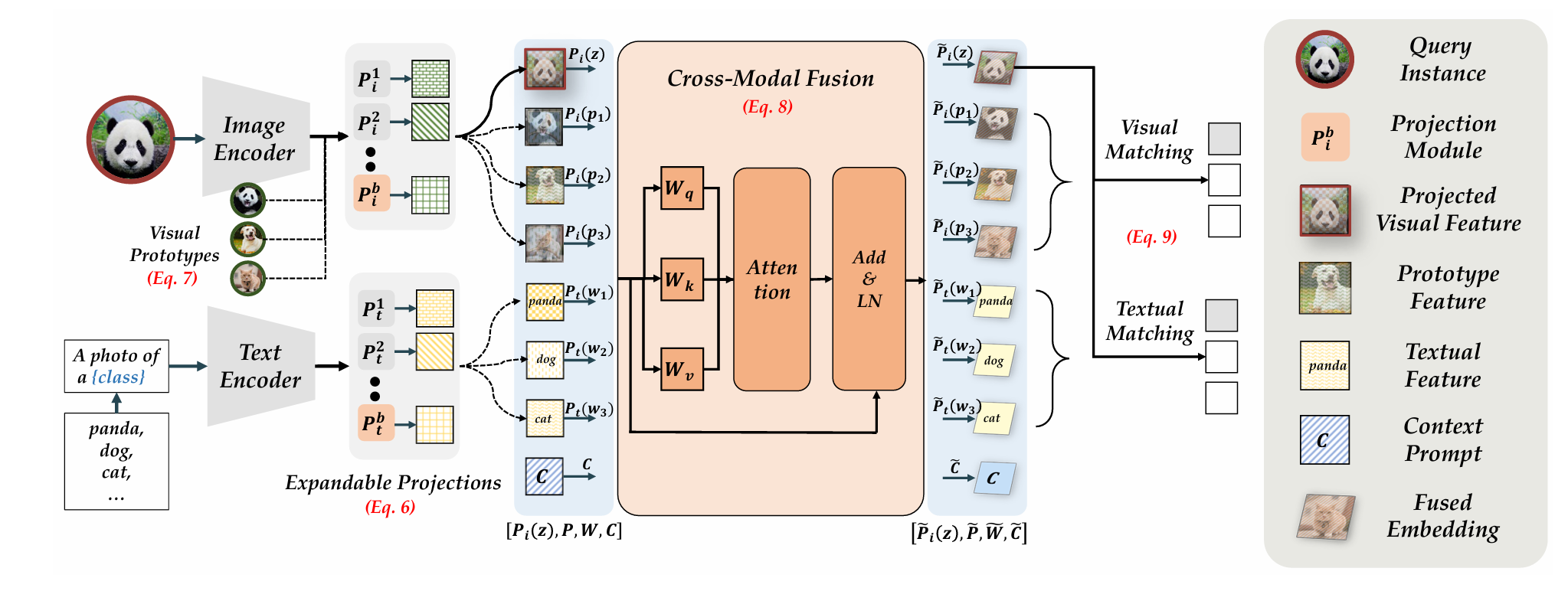 |
Learning without Forgetting for Vision-Language Models Da-Wei Zhou,Yuanhan Zhang;Yan Wang,Jingyi Ning,Han-Jia Ye,De-Chuan Zhan,Ziwei Liu TPAMI PDF / Code  Learning without Forgetting for Vision-Language Models. Learning without Forgetting for Vision-Language Models. |
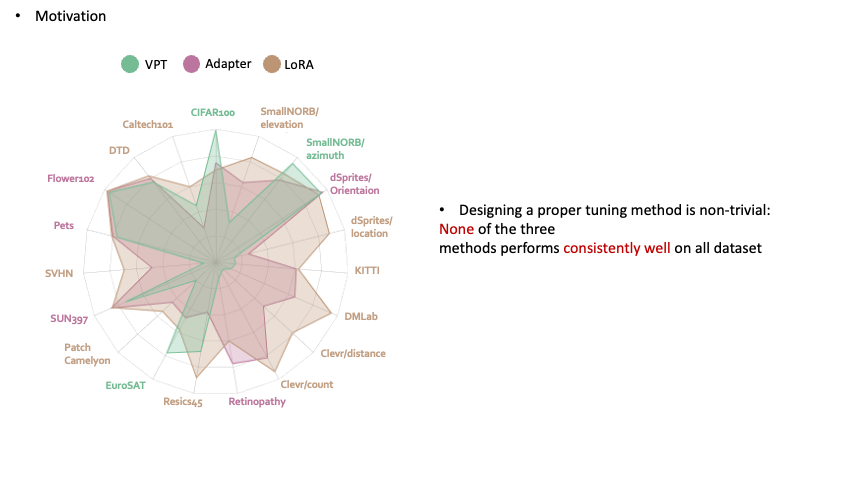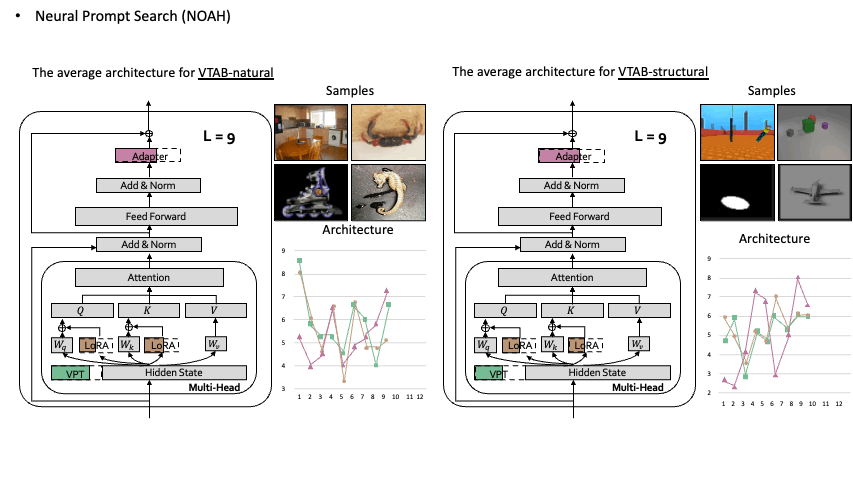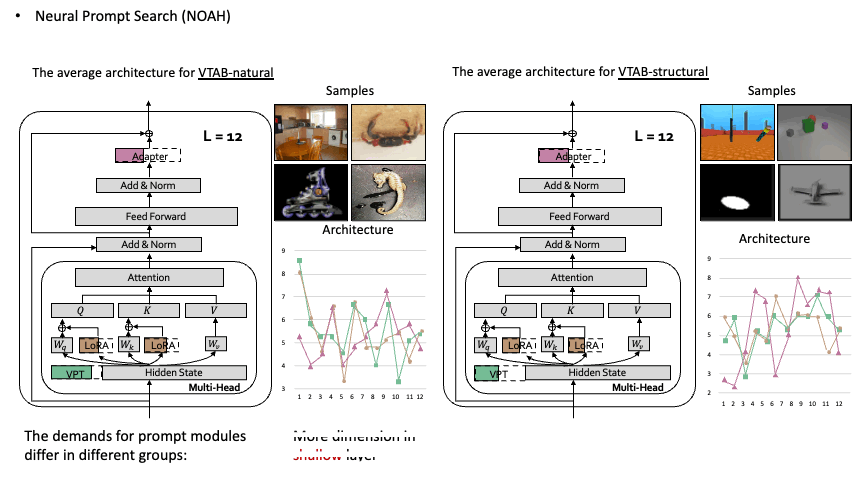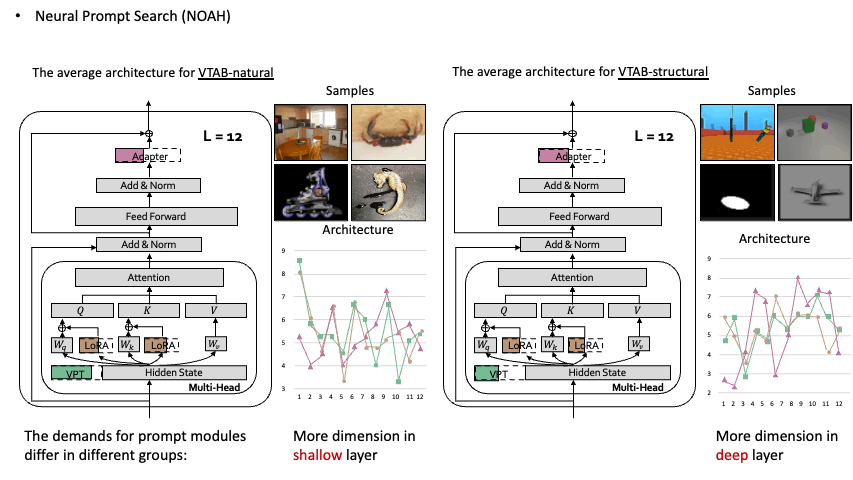 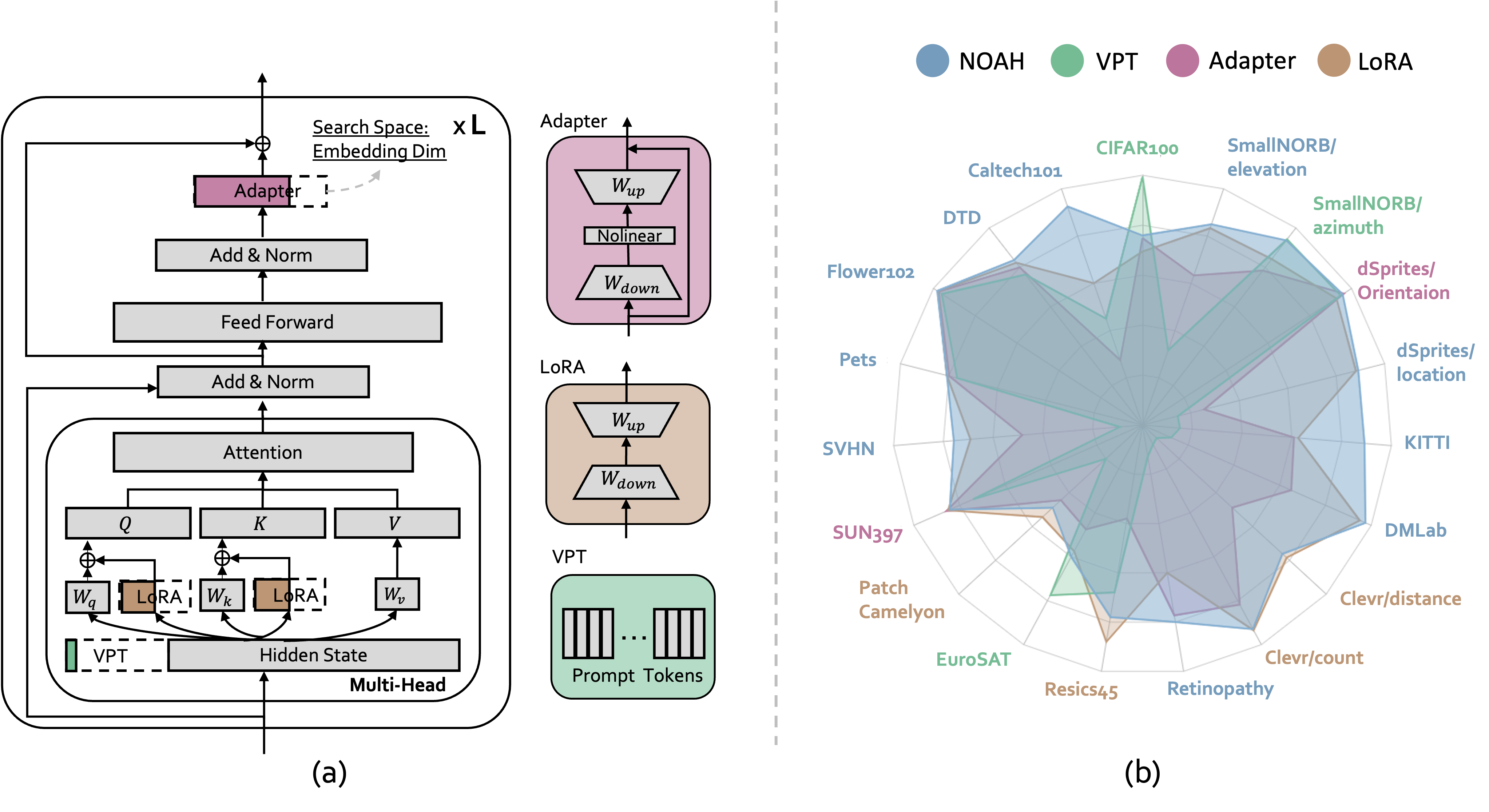 |
Neural Prompt Search Yuanhan Zhang,Kaiyang Zhou, Ziwei Liu TPAMI PDF / Project Page / Code  Searching prompt modules for parameter-efficient transfer learning. Searching prompt modules for parameter-efficient transfer learning. |
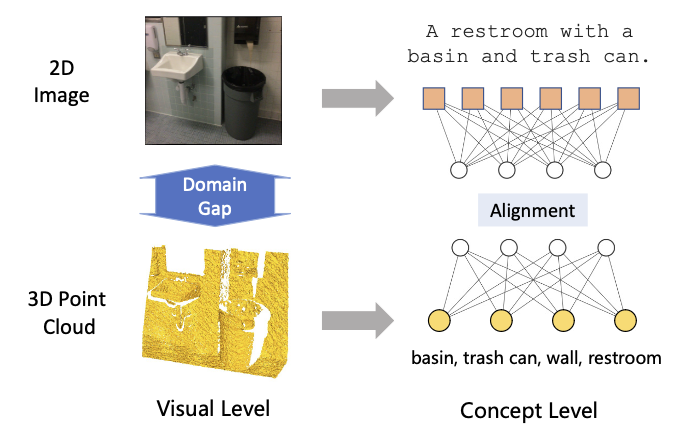 |
3D Point Cloud Pre-training with Knowledge Distillation from 2D Images? Yuan Yao,Yuanhan Zhang,Zhenfei Yin, Jiebo Luo,Wanli Ouyang,Xiaoshui Huang. ICME, 2023 PDF / Code 3D Point Cloud Pre-training with Knowledge Distillation from 2D Images. |
 |
Benchmarking Omni-Vision Representation through the Lens of Visual Realms Yuanhan Zhang, Zhenfei Yin, Jing Shao, Ziwei Liu ECCV, 2022 PDF / Project Page / Leaderboard / Challenge:ImageNet1k-Pretrain Track / Challenge:Open-Pretrain Track /Dataset and Code  New benchmark for evaluating vision foundation models; New supervised contrastive learning framework. New benchmark for evaluating vision foundation models; New supervised contrastive learning framework. |
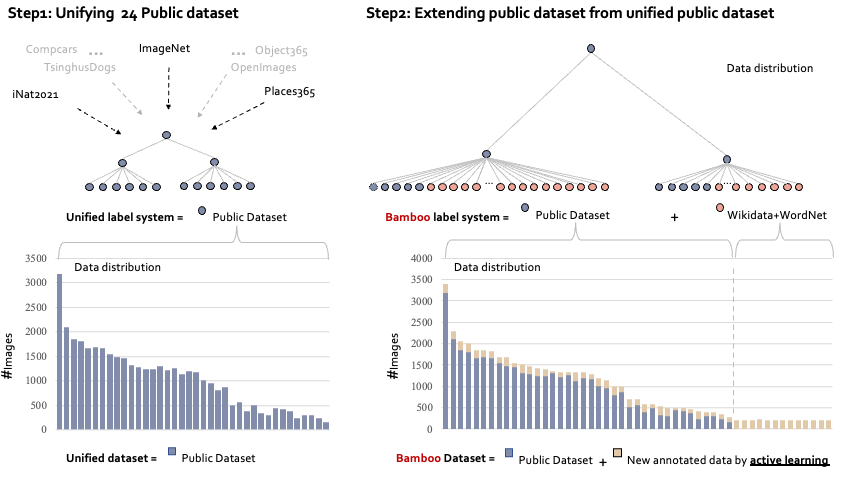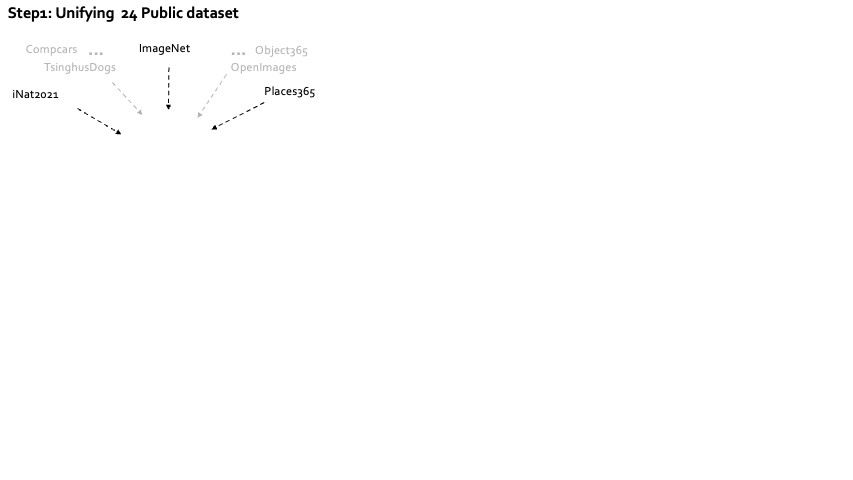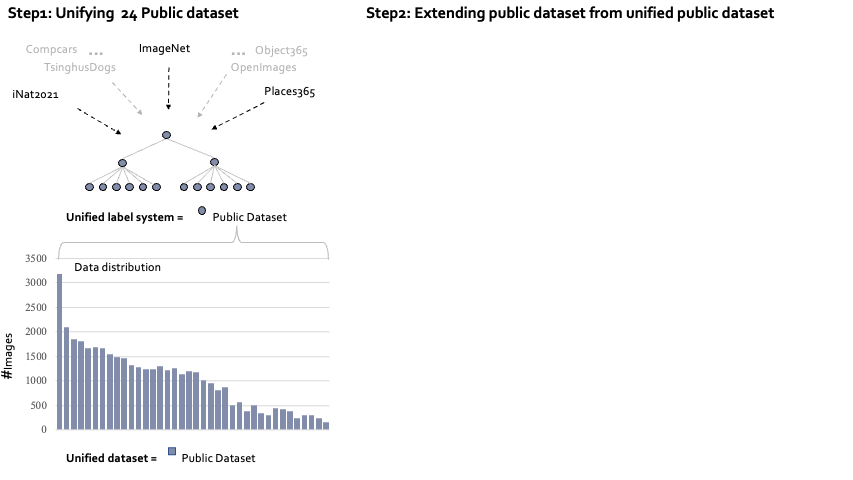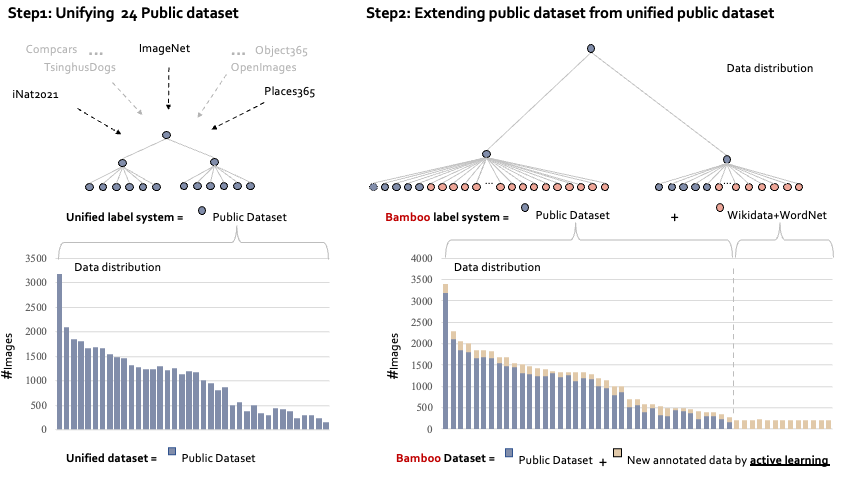 |
Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy Yuanhan Zhang, Qinghong Sun, Yichun Zhou, Zexin He, Zhenfei Yin, Kun Wang,Lu Sheng, Yu Qiao,Jing Shao, Ziwei Liu IJCV, 2025 PDF / Project Page / Demo /Code  4 times larger than ImageNet; 2 time larger than Object365; Built by active learning. 4 times larger than ImageNet; 2 time larger than Object365; Built by active learning. |
 |
CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations Yuanhan Zhang, Zhenfei Yin,Yidong Li, Guojun Yin, Junjie Yan, Jing Shao, Ziwei Liu ECCV, 2020 PDF /Dataset /Demo /Code  Large-scale face-antispoofing Dataset. Large-scale face-antispoofing Dataset. |

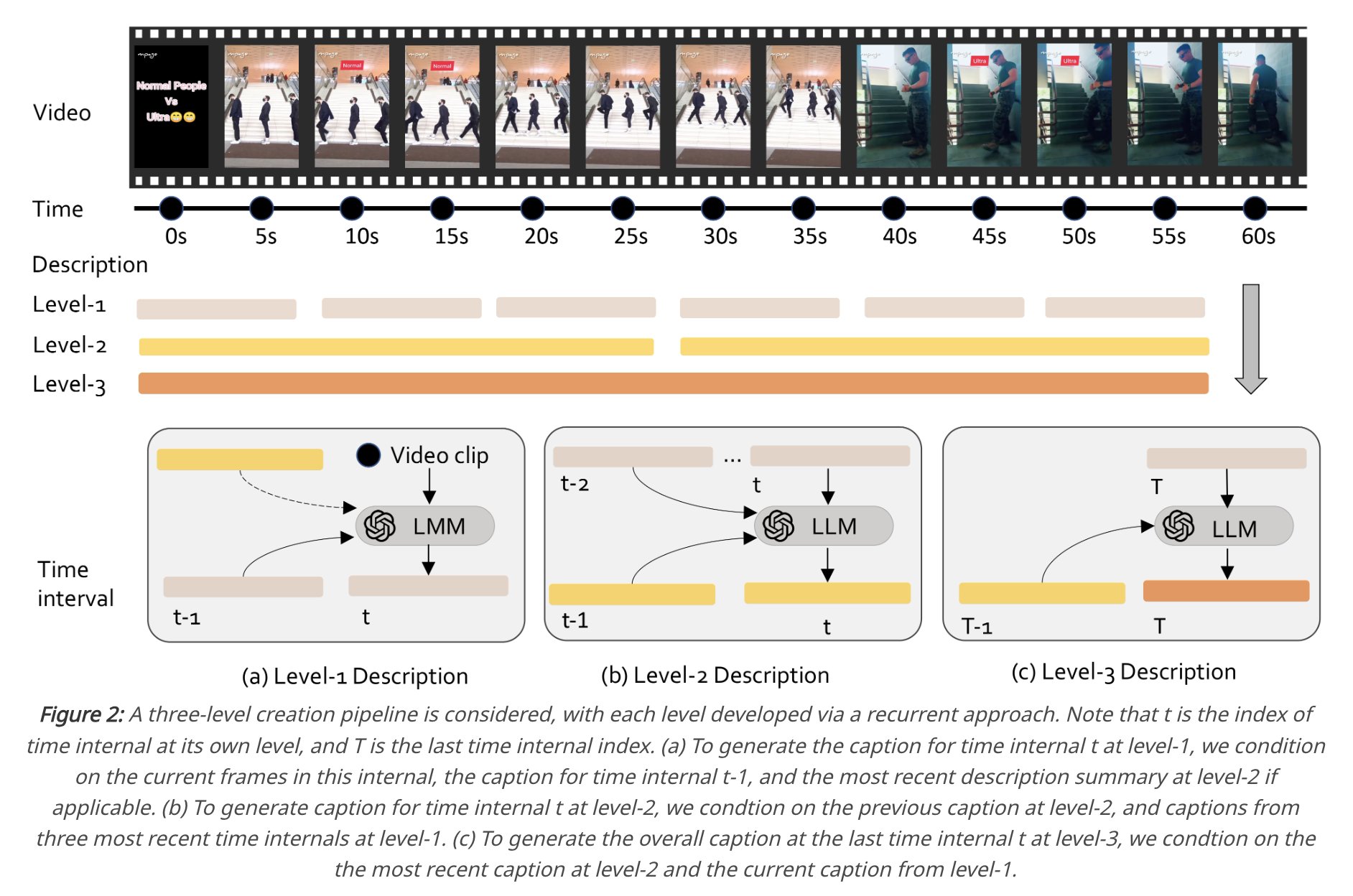
 Fully open-sourced video LMM model with competitive ability, including code, model, and data.
Fully open-sourced video LMM model with competitive ability, including code, model, and data.
 A vision-language model with in-context instruction tuning.
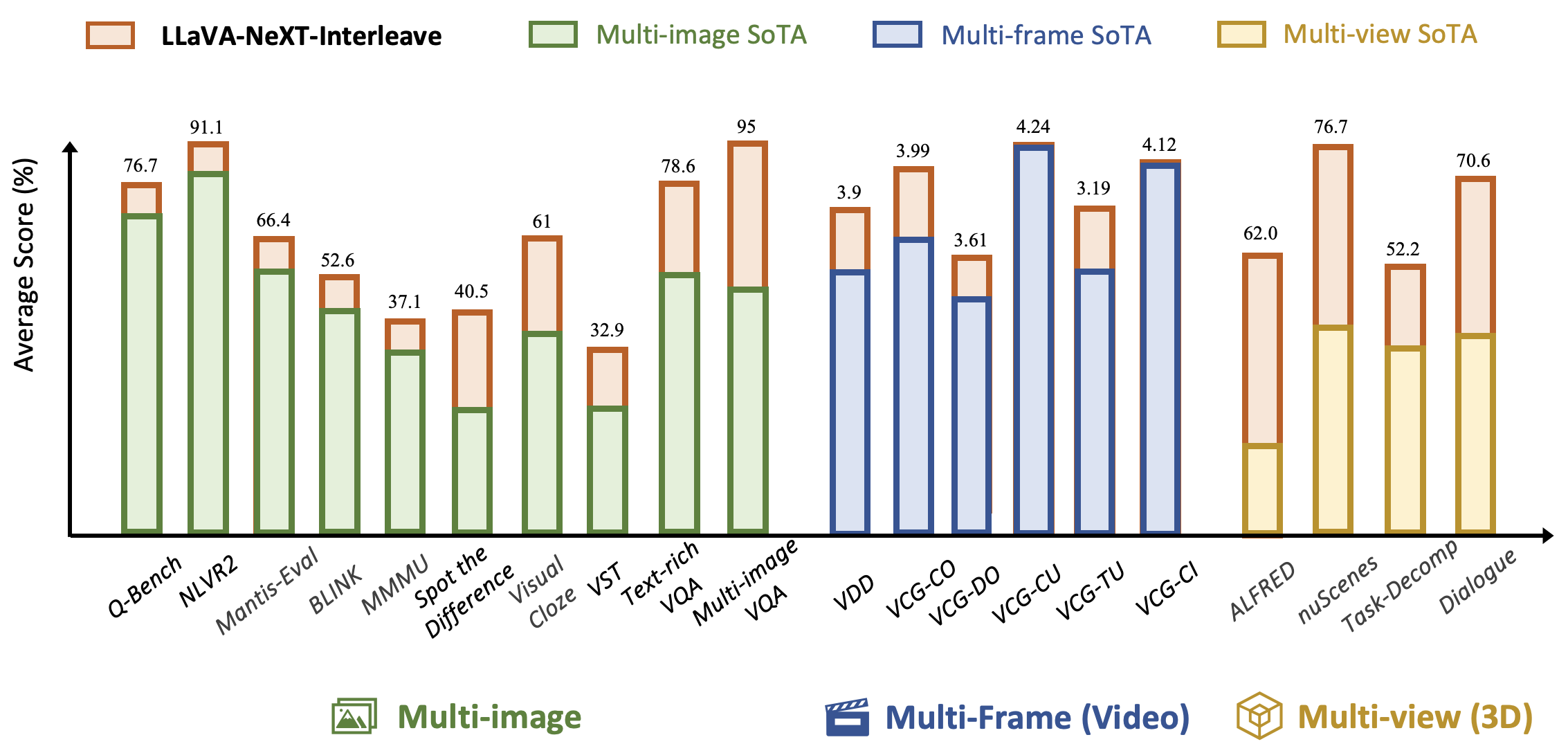
A vision-language model with in-context instruction tuning.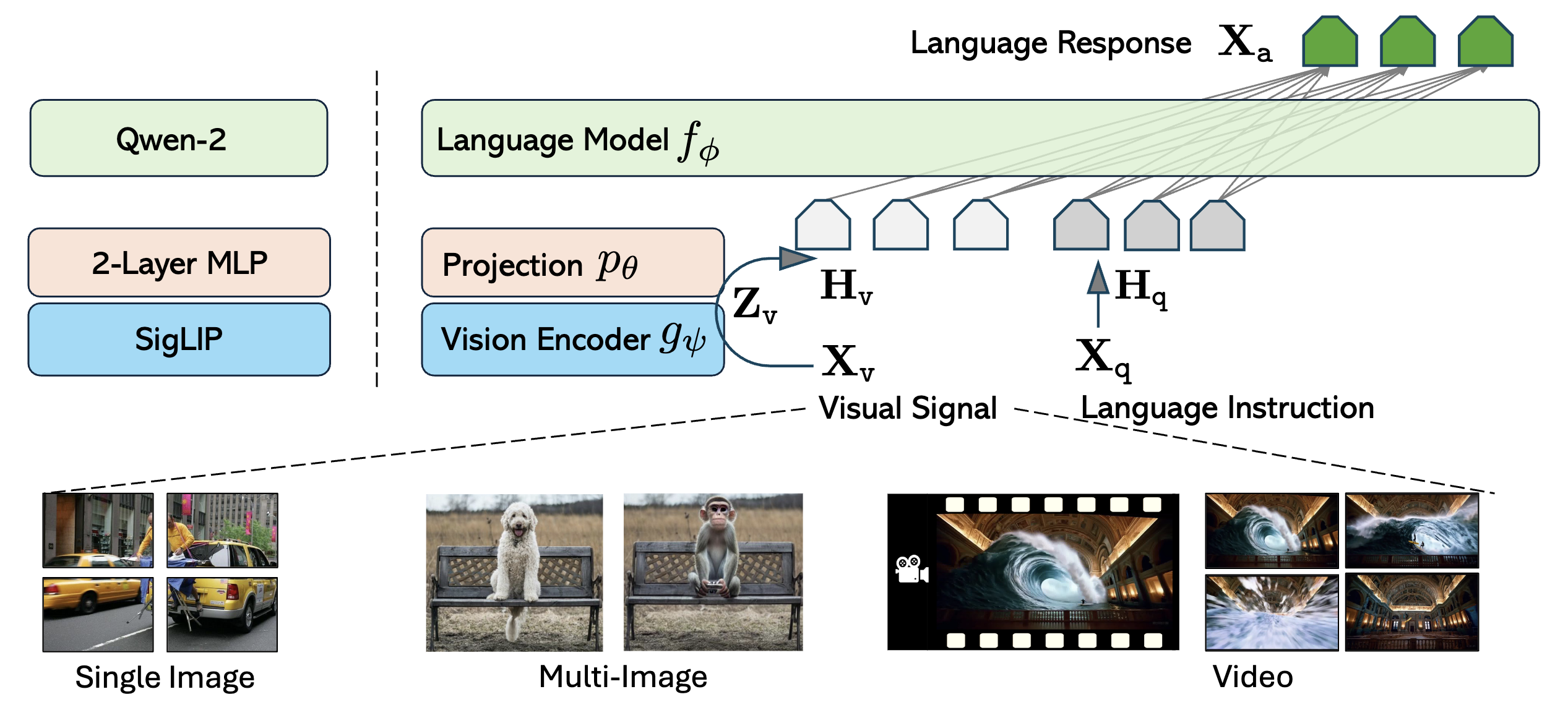
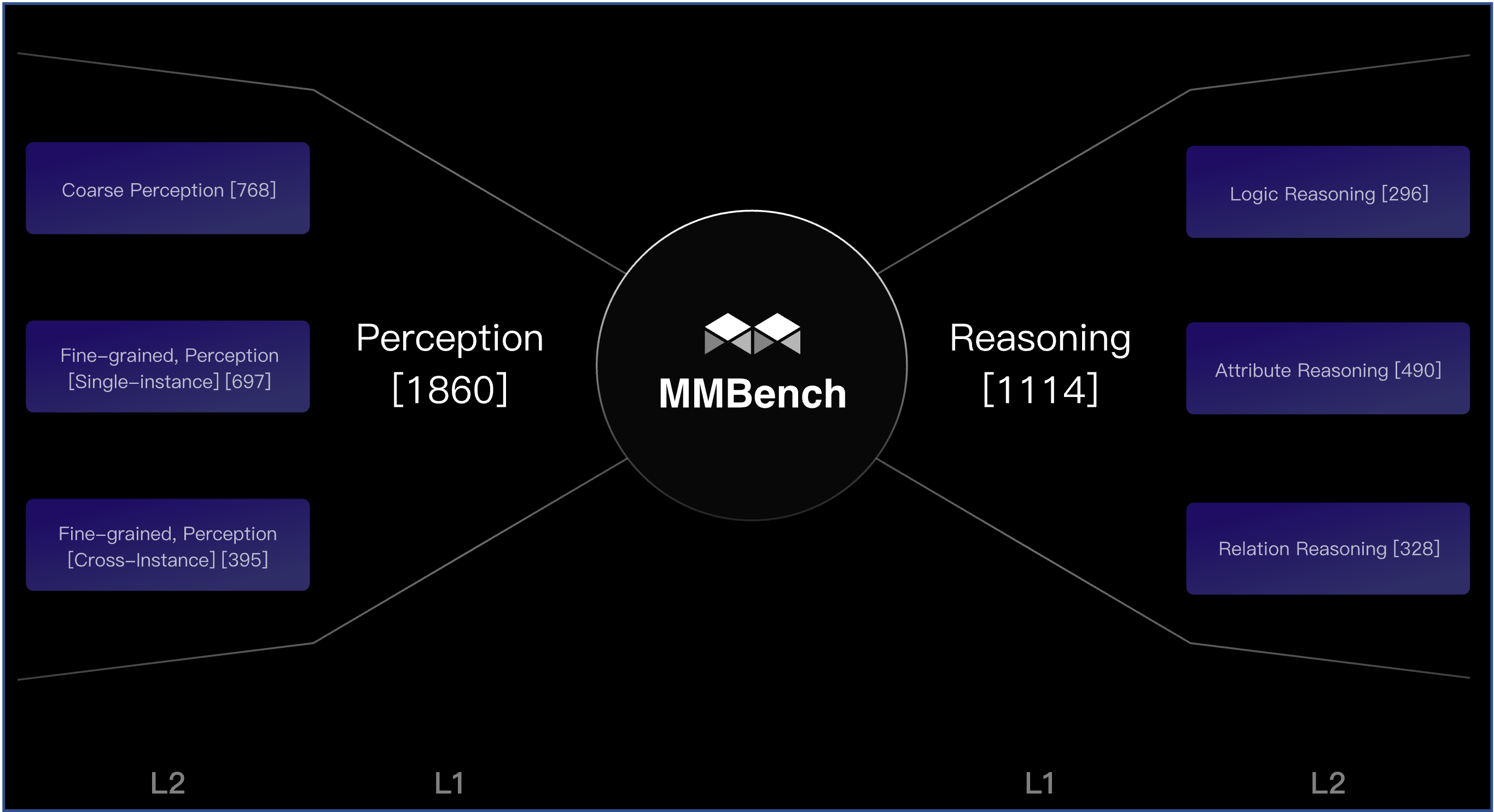
 Benchmarking the 20 abilities of vision-language models.
Benchmarking the 20 abilities of vision-language models. An embodied vision-language model trained with RLEF, emerging superior in embodied visual planning and programming.
An embodied vision-language model trained with RLEF, emerging superior in embodied visual planning and programming. FunQA benchmarks funny, creative, and magic videos for challenging tasks.
FunQA benchmarks funny, creative, and magic videos for challenging tasks.