MAgIC: Benchmarking Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration (original) (raw)
National University of Singapore, ByteDance
Stanford Unversity, UC Berkeley
*Equal Contribution #Corresponding authors
Abstract
Large Language Models (LLMs) have marked a significant advancement in the field of natural language processing, demonstrating exceptional capabilities in reasoning, tool usage, and memory. As their applications extend into multi-agent environments, a need has arisen for a comprehensive evaluation framework that captures their abilities in reasoning, planning, collaboration, and more. This work introduces a novel benchmarking framework specifically tailored to assess LLMs within multi-agent settings, providing quantitative metrics to evaluate their judgment, reasoning, deception, self-awareness, collaboration, coordination, and rationality. We utilize games such as Chameleon and Undercover, alongside game theory scenarios like Cost Sharing, Multi-player Prisoner's Dilemma, and Public Good, to create diverse testing environments. Our framework is fortified with the Probabilistic Graphical Modeling (PGM) method, enhancing the LLMs' capabilities in navigating complex social and cognitive dimensions. The benchmark evaluates seven multi-agent systems powered by different LLMs, quantitatively highlighting a significant capability gap over threefold between the strongest, GPT-4, and the weakest, Llama-2-70B. It also confirms that our PGM enhancement boosts the inherent abilities of all selected models by 50\% on average.
How about current LLMs-powered Multi-agent's capabilities
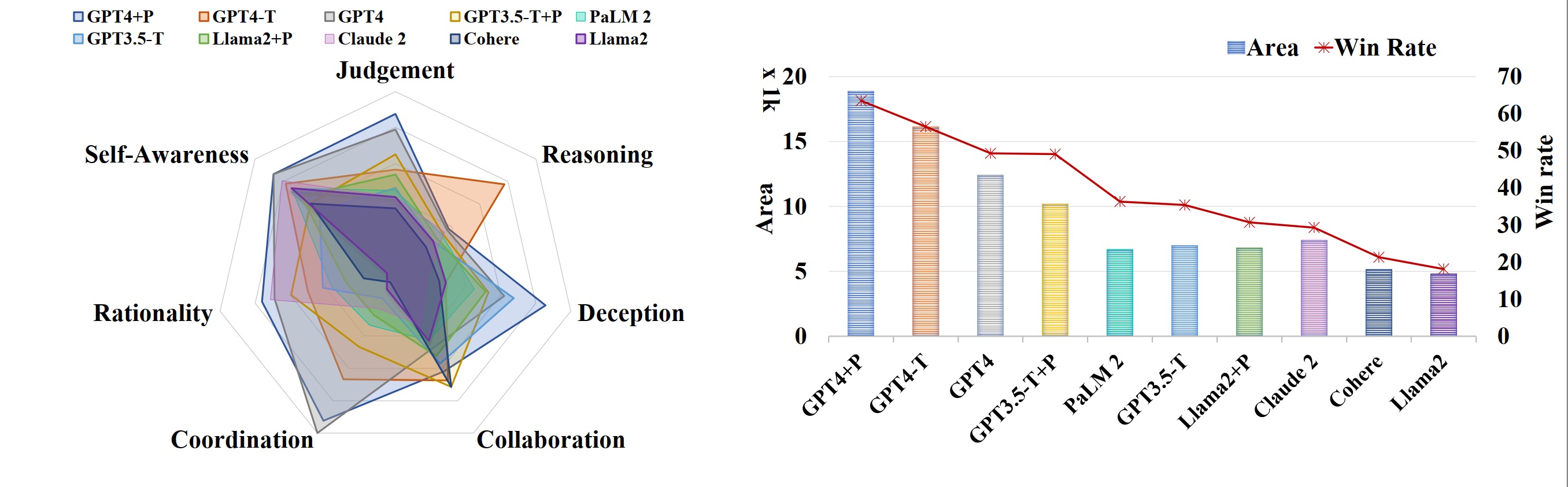
The radar diagram on the left illustrates the performance of LLMs across various metrics. In the figure, "-T" denotes "-turbo", and "+P" denotes that the model has been augmented with PGM. The bar chart on the right denotes the area occupied in the radar diagram and the red line plots the average winning rates in all games. It is clearly observed that the larger the area occupied in the radar diagram, the higher the winning rates are. This justifies that the proposed evaluation metrics are good to reflect the capability of the language models. For more details please refer to Sec.
Benchmarking Environment
We assess Multi-agent's abilities in Chameleon, Undercover, and Game Theory Scenarios (Cost Sharing, Prisoner’s Dilemma and Public Good)
▶ "Start to play different games!"
- To comprehensively assess above mentioned capabilities, we present five distinct scenarios.
- In the game of Chameleon and Undercover, quickly comprehending global information and making corresponding actions are the keys to winning the game. Thus we mainly measure the cognition and adaptability in these two scenarios.
- Moving to game theory scenarios, which require the agent to make optimal decisions based on the given premise, they are more apt for reflecting rationality and collaboration. As such, we center our evaluation on these latter two attributes in the context of three game theory scenarios.
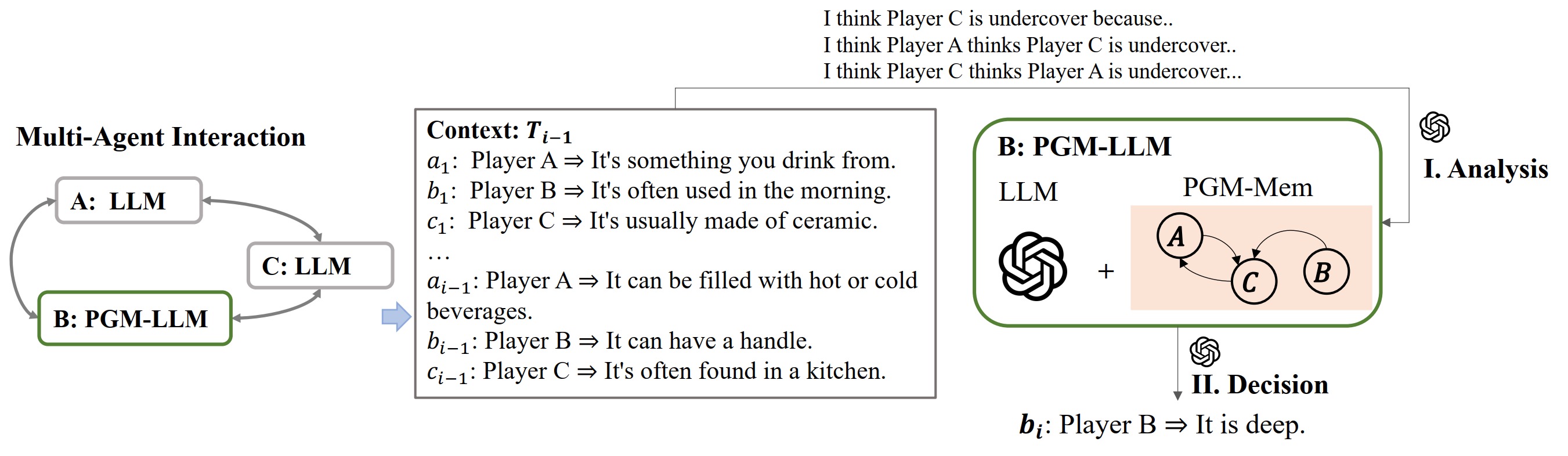
PGM-Aware Agent
PGM enhancement boosts the inherent abilities of all selected models by 50% on average!
Results
Ability Measurement of LLMs
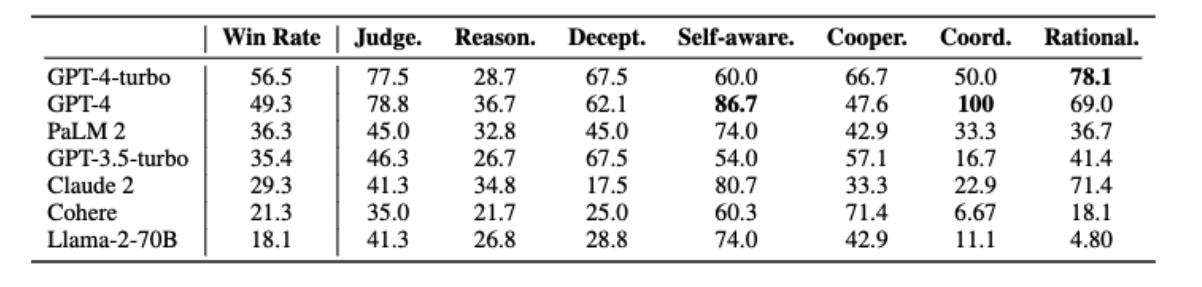
- The most prominent performer is the GPT-4-turbo method, showcasing outstanding overall performance with a remarkable win rate of 56.5%.
- Following closely is GPT-4, which achieves a win rate of 49.3%, demonstrating its competitiveness. While GPT-3.5-turbo remains superior to LLaMa-2-70B.
- We also assess other popular commercial LLMs such as PaLM 2, Claude 2, and Cohere; the experimental results indicate their abilities in multi-agent settings are between GPT-3.5-turbo and Llama-2-70B.
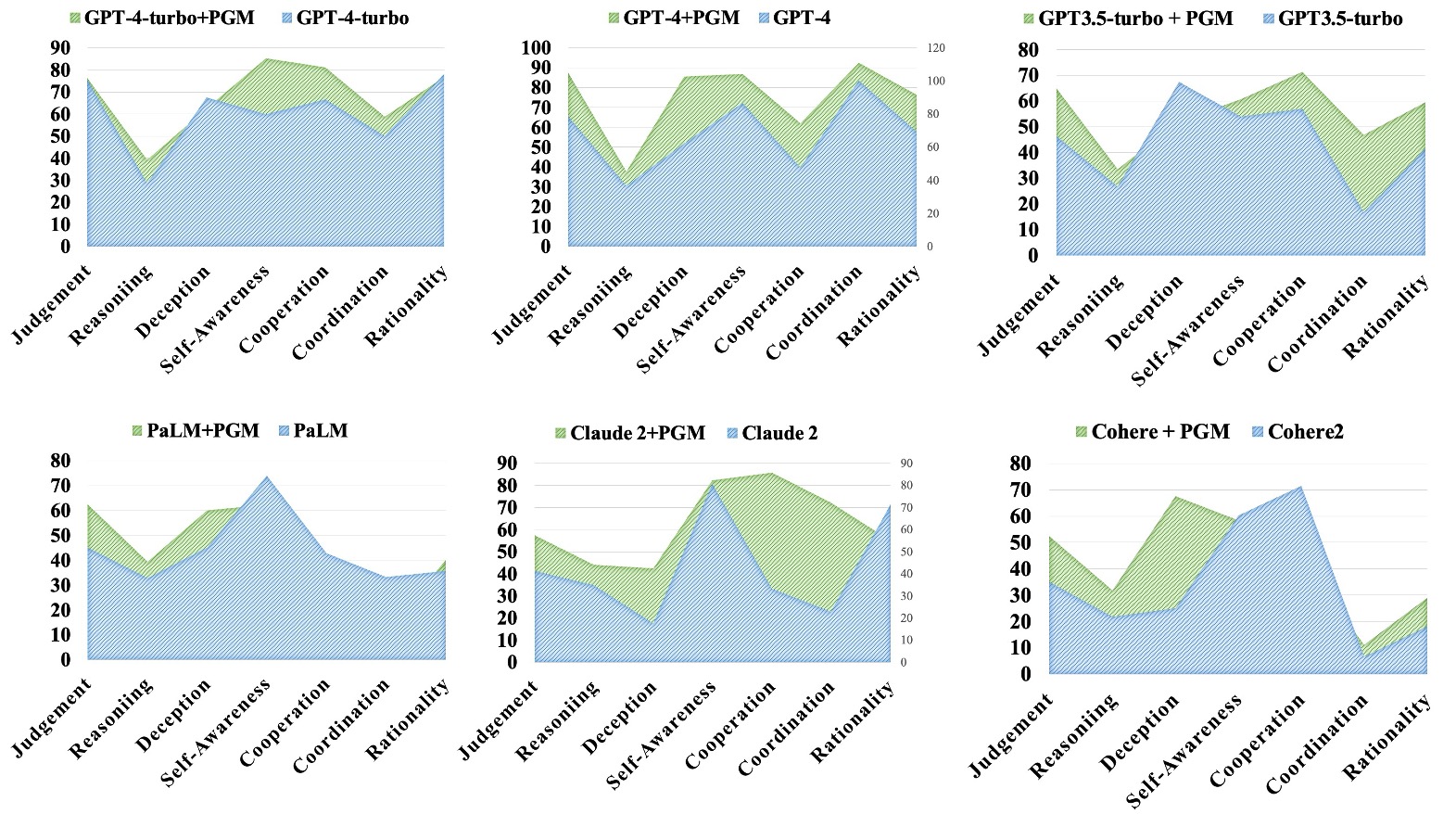
- Most PGM-aware agents significantly outperform their vanilla counterparts in 3 or 4 out of the 7 abilities
- It is confirmed that our PGM enhancement boosts the inherent abilities of all selected models by 45% on average.
- o1+PGM outperform o1 even is already been enhanced with rethinking.
BibTeX
@article{xu2023magic,
title={MAgIC: Benchmarking Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration},
author={Xu, Lin and Hu, Zhiyuan and Zhou, Daquan and Ren, Hongyu and Dong, Zhen and Keutzer, Kurt and Ng, See Kiong and Feng, Jiashi},
journal={arXiv preprint arXiv:2311.08562},
year={2023}
}