Retrieving metrics with the Performance Insights API (original) (raw)
When Performance Insights is enabled, the API provides visibility into instance performance. Amazon CloudWatch Logs provides the authoritative source for vended monitoring metrics for AWS services.
Performance Insights offers a domain-specific view of database load measured as average active sessions (AAS). This metric appears to API consumers as a two-dimensional time-series dataset. The time dimension of the data provides DB load data for each time point in the queried time range. Each time point decomposes overall load in relation to the requested dimensions, such as Query, Wait-state,Application, or Host, measured at that time point.
Amazon DocumentDB Performance Insights monitors your Amazon DocumentDB DB instance so that you can analyze and troubleshoot database performance. One way to view Performance Insights data is in the AWS Management Console. Performance Insights also provides a public API so that you can query your own data. You can use the API to do the following:
- Offload data into a database
- Add Performance Insights data to existing monitoring dashboards
- Build monitoring tools
To use the Performance Insights API, enable Performance Insights on one of your Amazon DocumentDB instances. For information about enabling Performance Insights, see Enabling and disabling Performance Insights. For more information about the Performance Insights API, see the Performance Insights API Reference.
The Performance Insights API provides the following operations.
Topics
- AWS CLI for Performance Insights
- Retrieving time-series metrics
- AWS CLI examples for Performance Insights
AWS CLI for Performance Insights
You can view Performance Insights data using the AWS CLI. You can view help for the AWS CLI commands for Performance Insights by entering the following on the command line.
aws pi helpIf you don't have the AWS CLI installed, see Installing the AWS Command Line Interface in the AWS CLI User Guide for information about installing it.
Retrieving time-series metrics
The GetResourceMetrics operation retrieves one or more time-series metrics from the Performance Insights data. GetResourceMetrics requires a metric and time period, and returns a response with a list of data points.
For example, the AWS Management Console uses GetResourceMetrics to populate theCounter Metrics chart and the Database Load chart, as seen in the following image.
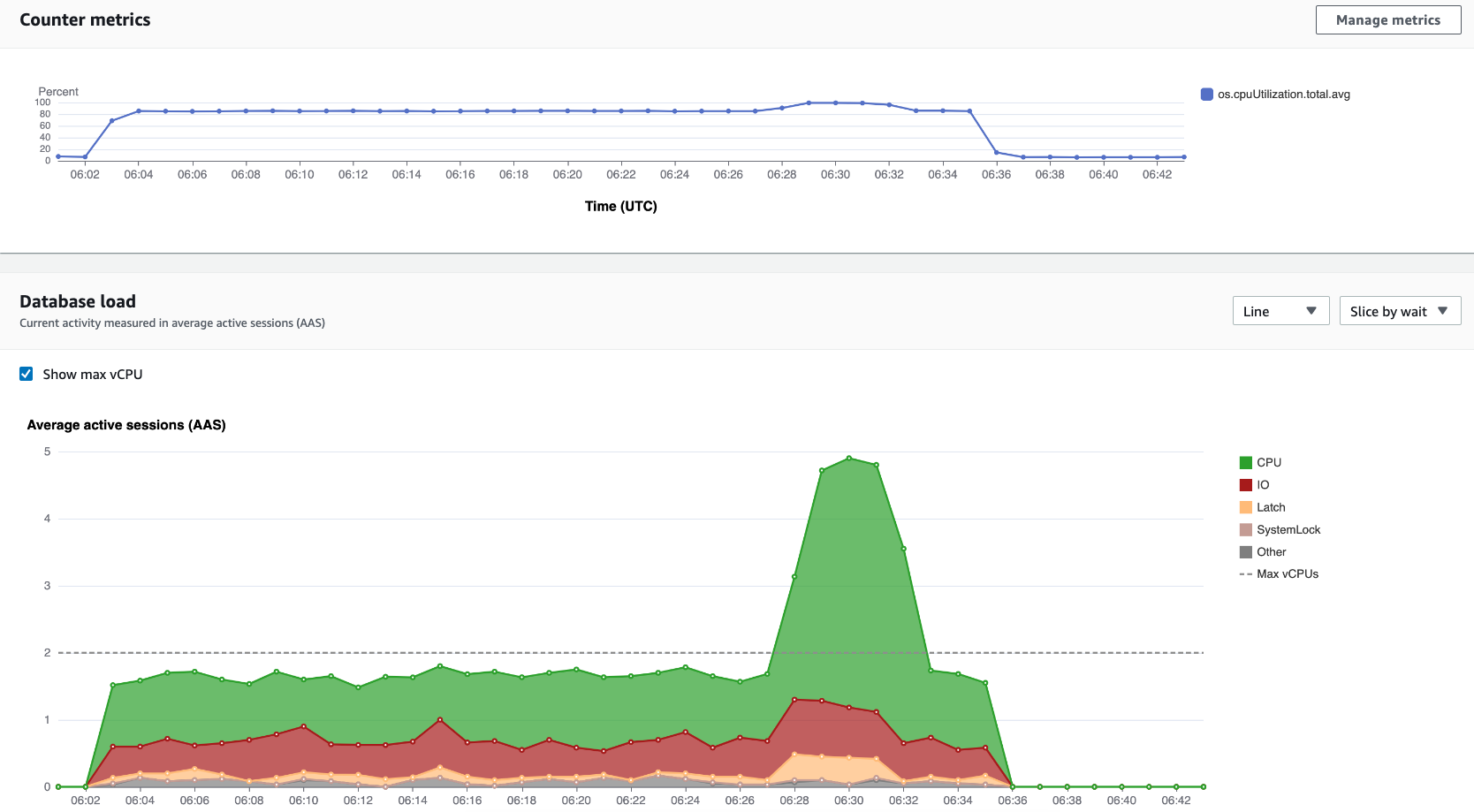
All metrics returned by GetResourceMetrics are standard time-series metrics, with the exception of db.load. This metric is displayed in theDatabase Load chart. The db.load metric is different from the other time-series metrics because you can break it into subcomponents called dimensions. In the previous image,db.load is broken down and grouped by the waits states that make up the db.load.
Note
GetResourceMetrics can also return the db.sampleload metric, but the db.load metric is appropriate in most cases.
For information about the counter metrics returned byGetResourceMetrics, see Performance Insights for counter metrics.
The following calculations are supported for the metrics:
- Average – The average value for the metric over a period of time. Append
.avgto the metric name. - Minimum – The minimum value for the metric over a period of time. Append
.minto the metric name. - Maximum – The maximum value for the metric over a period of time. Append
.maxto the metric name. - Sum – The sum of the metric values over a period of time. Append
.sumto the metric name. - Sample count – The number of times the metric was collected over a period of time. Append
.sample_countto the metric name.
For example, assume that a metric is collected for 300 seconds (5 minutes), and that the metric is collected one time each minute. The values for each minute are 1, 2, 3, 4, and 5. In this case, the following calculations are returned:
- Average – 3
- Minimum – 1
- Maximum – 5
- Sum – 15
- Sample count – 5
For information about using the get-resource-metrics AWS CLI command, see get-resource-metrics.
For the --metric-queries option, specify one or more queries that you want to get results for. Each query consists of a mandatory Metric and optional GroupBy and Filter parameters. The following is an example of a --metric-queries option specification.
{
"Metric": "string",
"GroupBy": {
"Group": "string",
"Dimensions": ["string", ...],
"Limit": integer
},
"Filter": {"string": "string"
...}AWS CLI examples for Performance Insights
The following examples show how to use the AWS CLI for Performance Insights.
Topics
- Retrieving counter metrics
- Retrieving the DB load average for top wait states
- Retrieving the DB load average for top Query
- Retrieving the DB load average filtered by Query
Retrieving counter metrics
The following screenshot shows two counter metrics charts in the AWS Management Console.
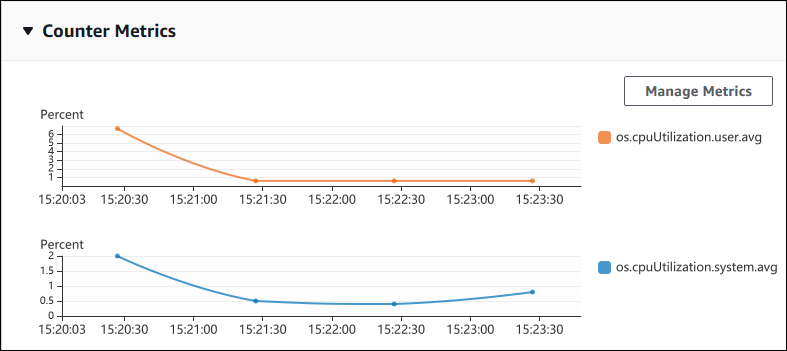
The following example shows how to gather the same data that the AWS Management Console uses to generate the two counter metric charts.
For Linux, macOS, or Unix:
aws pi get-resource-metrics \
--service-type DOCDB \
--identifier db-ID \
--start-time 2022-03-13T8:00:00Z \
--end-time 2022-03-13T9:00:00Z \
--period-in-seconds 60 \
--metric-queries '[{"Metric": "os.cpuUtilization.user.avg" },
{"Metric": "os.cpuUtilization.idle.avg"}]'For Windows:
aws pi get-resource-metrics ^
--service-type DOCDB ^
--identifier db-ID ^
--start-time 2022-03-13T8:00:00Z ^
--end-time 2022-03-13T9:00:00Z ^
--period-in-seconds 60 ^
--metric-queries '[{"Metric": "os.cpuUtilization.user.avg" },
{"Metric": "os.cpuUtilization.idle.avg"}]'You can also make a command easier to read by specifying a file for the--metrics-query option. The following example uses a file called query.json for the option. The file has the following contents.
[
{
"Metric": "os.cpuUtilization.user.avg"
},
{
"Metric": "os.cpuUtilization.idle.avg"
}
]Run the following command to use the file.
For Linux, macOS, or Unix:
aws pi get-resource-metrics \
--service-type DOCDB \
--identifier db-ID \
--start-time 2022-03-13T8:00:00Z \
--end-time 2022-03-13T9:00:00Z \
--period-in-seconds 60 \
--metric-queries file://query.jsonFor Windows:
aws pi get-resource-metrics ^
--service-type DOCDB ^
--identifier db-ID ^
--start-time 2022-03-13T8:00:00Z ^
--end-time 2022-03-13T9:00:00Z ^
--period-in-seconds 60 ^
--metric-queries file://query.jsonThe preceding example specifies the following values for the options:
--service-type–DOCDBfor Amazon DocumentDB--identifier– The resource ID for the DB instance--start-timeand--end-time– The ISO 8601DateTimevalues for the period to query, with multiple supported formats
It queries for a one-hour time range:
--period-in-seconds–60for a per-minute query--metric-queries– An array of two queries, each just for one metric.
The metric name uses dots to classify the metric in a useful category, with the final element being a function. In the example, the function isavgfor each query. As with Amazon CloudWatch, the supported functions aremin,max,total, andavg.
The response looks similar to the following.
{
"AlignedStartTime": "2022-03-13T08:00:00+00:00",
"AlignedEndTime": "2022-03-13T09:00:00+00:00",
"Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4",
"MetricList": [
{
"Key": {
"Metric": "os.cpuUtilization.user.avg"
},
"DataPoints": [
{
"Timestamp": "2022-03-13T08:01:00+00:00", //Minute1
"Value": 3.6
},
{
"Timestamp": "2022-03-13T08:02:00+00:00", //Minute2
"Value": 2.6
},
//.... 60 datapoints for the os.cpuUtilization.user.avg metric
{
"Key": {
"Metric": "os.cpuUtilization.idle.avg"
},
"DataPoints": [
{
"Timestamp": "2022-03-13T08:01:00+00:00",
"Value": 92.7
},
{
"Timestamp": "2022-03-13T08:02:00+00:00",
"Value": 93.7
},
//.... 60 datapoints for the os.cpuUtilization.user.avg metric
]
}
] //end of MetricList
} //end of responseThe response has an Identifier, AlignedStartTime, and AlignedEndTime. B the --period-in-seconds value was 60, the start and end times have been aligned to the minute. If the --period-in-seconds was 3600, the start and end times would have been aligned to the hour.
The MetricList in the response has a number of entries, each with a Key and a DataPoints entry. EachDataPoint has a Timestamp and aValue. Each Datapoints list has 60 data points because the queries are for per-minute data over an hour, withTimestamp1/Minute1, Timestamp2/Minute2, and so on, up to Timestamp60/Minute60.
Because the query is for two different counter metrics, there are two elements in the response MetricList.
Retrieving the DB load average for top wait states
The following example is the same query that the AWS Management Console uses to generate a stacked area line graph. This example retrieves the db.load.avg for the last hour with load divided according to the top seven wait states. The command is the same as the command in Retrieving counter metrics. However, the query.json file has the following contents.
[
{
"Metric": "db.load.avg",
"GroupBy": { "Group": "db.wait_state", "Limit": 7 }
}
]Run the following command.
For Linux, macOS, or Unix:
aws pi get-resource-metrics \
--service-type DOCDB \
--identifier db-ID \
--start-time 2022-03-13T8:00:00Z \
--end-time 2022-03-13T9:00:00Z \
--period-in-seconds 60 \
--metric-queries file://query.jsonFor Windows:
aws pi get-resource-metrics ^
--service-type DOCDB ^
--identifier db-ID ^
--start-time 2022-03-13T8:00:00Z ^
--end-time 2022-03-13T9:00:00Z ^
--period-in-seconds 60 ^
--metric-queries file://query.jsonThe example specifies the metric of db.load.avg and aGroupBy of the top seven wait states. For details about valid values for this example, see DimensionGroup in the Performance Insights API Reference.
The response looks similar to the following.
{
"AlignedStartTime": "2022-04-04T06:00:00+00:00",
"AlignedEndTime": "2022-04-04T06:15:00+00:00",
"Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4",
"MetricList": [
{//A list of key/datapoints
"Key": {
//A Metric with no dimensions. This is the total db.load.avg
"Metric": "db.load.avg"
},
"DataPoints": [
//Each list of datapoints has the same timestamps and same number of items
{
"Timestamp": "2022-04-04T06:01:00+00:00",//Minute1
"Value": 0.0
},
{
"Timestamp": "2022-04-04T06:02:00+00:00",//Minute2
"Value": 0.0
},
//... 60 datapoints for the total db.load.avg key
]
},
{
"Key": {
//Another key. This is db.load.avg broken down by CPU
"Metric": "db.load.avg",
"Dimensions": {
"db.wait_state.name": "CPU"
}
},
"DataPoints": [
{
"Timestamp": "2022-04-04T06:01:00+00:00",//Minute1
"Value": 0.0
},
{
"Timestamp": "2022-04-04T06:02:00+00:00",//Minute2
"Value": 0.0
},
//... 60 datapoints for the CPU key
]
},//... In total we have 3 key/datapoints entries, 1) total, 2-3) Top Wait States
] //end of MetricList
} //end of response
In this response, there are three entries in the MetricList. There is one entry for the total db.load.avg, and three entries each for the db.load.avg divided according to one of the top three wait states. Since there was a grouping dimension (unlike the first example), there must be one key for each grouping of the metric. There can't be only one key for each metric, as in the basic counter metric use case.
Retrieving the DB load average for top Query
The following example groups db.wait_state by the top 10 query statements. There are two different groups for query statements:
db.query– The full query statement, such as{"find":"customers","filter":{"FirstName":"Jesse"},"sort":{"key":{"$numberInt":"1"}}}db.query_tokenized– The tokenized query statement, such as{"find":"customers","filter":{"FirstName":"?"},"sort":{"key":{"$numberInt":"?"}},"limit":{"$numberInt":"?"}}
When analyzing database performance, it can be useful to consider query statements that only differ by their parameters as one logic item. So, you can use db.query_tokenized when querying. However, especially when you're interested in explain(), sometimes it's more useful to examine full query statements with parameters. There is a parent-child relationship between tokenized and full queries, with multiple full queries (children) grouped under the same tokenized query (parent).
The command in this example is the similar to the command in Retrieving the DB load average for top wait states. However, the query.json file has the following contents.
[
{
"Metric": "db.load.avg",
"GroupBy": { "Group": "db.query_tokenized", "Limit": 10 }
}
]The following example uses db.query_tokenized.
For Linux, macOS, or Unix:
aws pi get-resource-metrics \
--service-type DOCDB \
--identifier db-ID \
--start-time 2022-03-13T8:00:00Z \
--end-time 2022-03-13T9:00:00Z \
--period-in-seconds 3600 \
--metric-queries file://query.json For Windows:
aws pi get-resource-metrics ^
--service-type DOCDB ^
--identifier db-ID ^
--start-time 2022-03-13T8:00:00Z ^
--end-time 2022-03-13T9:00:00Z ^
--period-in-seconds 3600 ^
--metric-queries file://query.json This example queries over 1 hour, with a one minute period-in-seconds.
The example specifies the metric of db.load.avg and aGroupBy of the top seven wait states. For details about valid values for this example, see DimensionGroup in the Performance Insights API Reference.
The response looks similar to the following.
{
"AlignedStartTime": "2022-04-04T06:00:00+00:00",
"AlignedEndTime": "2022-04-04T06:15:00+00:00",
"Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4",
"MetricList": [
{//A list of key/datapoints
"Key": {
"Metric": "db.load.avg"
},
"DataPoints": [
//... 60 datapoints for the total db.load.avg key
]
},
{
"Key": {//Next key are the top tokenized queries
"Metric": "db.load.avg",
"Dimensions": {
"db.query_tokenized.db_id": "pi-1064184600",
"db.query_tokenized.id": "77DE8364594EXAMPLE",
"db.query_tokenized.statement": "{\"find\":\"customers\",\"filter\":{\"FirstName\":\"?\"},\"sort\":{\"key\":{\"$numberInt\":\"?\"}},\"limit\"
:{\"$numberInt\":\"?\"},\"$db\":\"myDB\",\"$readPreference\":{\"mode\":\"primary\"}}"
}
},
"DataPoints": [
//... 60 datapoints
]
},
// In total 11 entries, 10 Keys of top tokenized queries, 1 total key
] //End of MetricList
} //End of responseThis response has 11 entries in the MetricList (1 total, 10 top tokenized query), with each entry having 24 per-hourDataPoints.
For tokenized queries, there are three entries in each dimensions list:
db.query_tokenized.statement– The tokenized query statement.db.query_tokenized.db_id– The synthetic ID that Performance Insights generates for you. This example returns thepi-1064184600synthetic ID.db.query_tokenized.id– The ID of the query inside Performance Insights.
In the AWS Management Console, this ID is called the Support ID. It's named this because the ID is data that AWS Support can examine to help you troubleshoot an issue with your database. AWS takes the security and privacy of your data extremely seriously, and almost all data is stored encrypted with your AWS KMS key. Therefore, nobody inside AWS can look at this data. In the example preceding, both thetokenized.statementand thetokenized.db_idare stored encrypted. If you have an issue with your database, AWS Support can help you by referencing the Support ID.
When querying, it might be convenient to specify a Group inGroupBy. However, for finer-grained control over the data that's returned, specify the list of dimensions. For example, if all that is needed is the db.query_tokenized.statement, then aDimensions attribute can be added to the query.json file.
[
{
"Metric": "db.load.avg",
"GroupBy": {
"Group": "db.query_tokenized",
"Dimensions":["db.query_tokenized.statement"],
"Limit": 10
}
}
]Retrieving the DB load average filtered by Query
The corresponding API query in this example is similar to the command in Retrieving the DB load average for top Query. However, the query.json file has the following contents.
[
{
"Metric": "db.load.avg",
"GroupBy": { "Group": "db.wait_state", "Limit": 5 },
"Filter": { "db.query_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }
}
]In this response, all values are filtered according to the contribution of tokenized query AKIAIOSFODNN7EXAMPLE specified in the query.json file. The keys also might follow a different order than a query without a filter, because it's the top five wait states that affected the filtered query.