Handling Errors | Couchbase Docs (original) (raw)
The following fundamentals help you understand how the SDK makes retry decisions and how errors are surfaced. Later sections will cover how you can influence this behavior.
The Request Lifecycle
The following image shows the high-level phases during a request lifecycle:
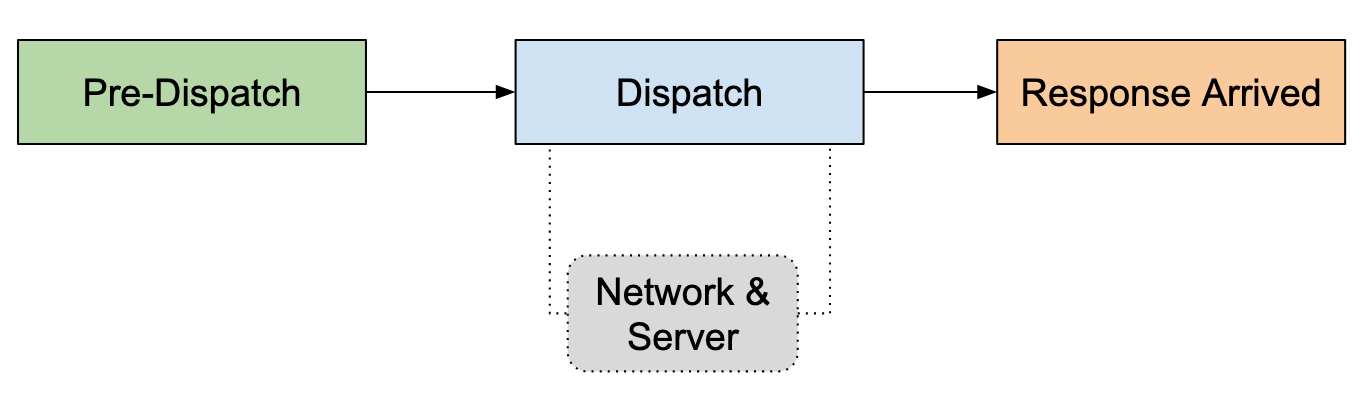
- Pre-Dispatch: This is the initial phase of the request lifecycle. The request is created and the SDK is trying to find the right socket/endpoint to dispatch the operation into.
- Dispatch: The SDK puts the operation onto the network and waits for a response. This is a critical point in the lifecycle because the retryability depends on the idempotence of the request (discussed later).
- Response Arrived: Once a response arrives from the server, the SDK decides what to do with it (in the best case, complete the operation successfully).
All the specifics are discussed below, but a broad categorization of exceptions can be outlined already:
- If a response arrived and it indicates non-success and the SDK determines that it cannot be retried the operation will fail with an explicit exception. For example, if you perform an
insertoperation and the document already exists, the SDK will fail the operation with aDocumentExistsException. - Failures in all other cases, especially during pre-dispatch and dispatch, will result in either a
TimeoutExceptionor aRequestCanceledException.
The Ubiquitous TimeoutException
The one exception that you are inevitably going to hit is the TimeoutException, or more specifically its child implementations the UnambiguousTimeoutException and the AmbiguousTimeoutException.
It is important to establish a mindset that a timeout is never the cause of a problem, but always the symptom. A timeout is your friend, because otherwise your thread will just end up being blocked for a long time instead. A timeout gives you control over what should happen when it occurs, and it provides a safety net and last resort if the operation cannot be completed for whatever reason.
The SDK will raise an AmbiguousTimeoutException unless it can be sure that it did not cause any side effect on the server side (for example if an idempotent operation timed out, which is covered in the next section). Most of the time it is enough to just handle the generic TimeoutException.
Since the timeout is never the cause, always the symptom, it is important to provide contextual information on what might have caused it in the first place. In this newest generation of the SDK, we introduced the concept of an ErrorContext which helps with exactly that.
The ErrorContext is available as a method on the TimeoutException through the context() getter, but most importantly it is automatically attached to the exception output when printed in the logs. Here is an example output of such a TimeoutException with the attached context:
Exception in thread "main" com.couchbase.client.core.error.UnambiguousTimeoutException: GetRequest, Reason: TIMEOUT {"cancelled":true,"completed":true,"coreId":"0x5b36b0db00000001","idempotent":true,"reason":"TIMEOUT","requestId":22,"requestType":"GetRequest","retried":14,"retryReasons":["ENDPOINT_NOT_AVAILABLE"],"service":{"bucket":"travel-sample","collection":"_default","documentId":"airline_10226","opaque":"0x24","scope":"_default","type":"kv"},"timeoutMs":2500,"timings":{"totalMicros":2509049}}
at com.couchbase.client.java.AsyncUtils.block(AsyncUtils.java:51)
// ... (rest of stack omitted) ...The full reference for the ErrorContext can be found at the bottom of the page, but just by looking at it we can observe the following information:
- A
GetRequesttimed out after2500ms. - The document in question had the ID
airline_10226and we used thetravel-samplebucket. - It has been retried 14 times and the reason was always
ENDPOINT_NOT_AVAILABLE.
We’ll discuss retry reasons later in this document, but ENDPOINT_NOT_AVAILABLE signals that we could not send the operation over the socket because it was not connected/available. Since we now know that the socket had issues, we can inspect the logs to see if we find anything related:
2020-10-16T10:28:48.717+0200 WARN endpoint:523 - [com.couchbase.endpoint][EndpointConnectionFailedEvent][2691us] Connect attempt 7 failed because of AnnotatedConnectException: finishConnect(..) failed: Connection refused: /127.0.0.1:11210 {"bucket":"travel-sample","channelId":"5B36B0DB00000001/000000006C7CDB48","circuitBreaker":"DISABLED","coreId":"0x5b36b0db00000001","local":"127.0.0.1:49895","remote":"127.0.0.1:11210","type":"KV"}
com.couchbase.client.core.deps.io.netty.channel.AbstractChannel$AnnotatedConnectException: finishConnect(..) failed: Connection refused: /127.0.0.1:11210
Caused by: java.net.ConnectException: finishConnect(..) failed: Connection refused
at com.couchbase.client.core.deps.io.netty.channel.unix.Errors.throwConnectException(Errors.java:124)
// ... (rest of stack omitted) ...Looks like we tried to connect to the server, but the connection got refused. Next step would be to triage the socket issue on the server side, but in this case it’s not needed since I just stopped the server for this experiment. Time to start it up again and jump to the next section!
Request Cancellations
Since we’ve covered timeouts already, the other remaining special exception is the RequestCanceledException. It will be thrown in the following cases:
- The
RetryStrategydetermined that theRetryReasonmust not be retried (covered later). - Too many requests are being stuck waiting to be retried (signaling backpressure).
- The SDK is already shut down when an operation is performed.
There are potentially other reasons as well, but where it originates is not as important as the information it conveys. If you get a RequestCanceledException, it means the SDK is not able to further retry the operation and it is terminated before the timeout interval.
Transparently retrying should only be done if the RetryStrategy has been customized and you are sure that the retried operation hasn’t performed any side-effects on the server that can lead to data loss. Most of the time the logs need to be inspected after the fact to figure out what went wrong.
To aid with debugging after the fact, the RequestCanceledException also contains an ErrorContext, very similar to what has been discussed in the timeout section above.
Idempotent vs. Non-Idempotent Requests
Operations flowing through the SDK are either idempotent or non-idempotent. If an operation is idempotent, it can be sent to the server multiple times without changing the result more than once.
This distinction is important when the SDK sends the operation to the server and the socket gets closed before it receives a response. If it is not idempotent the SDK cannot be sure if it caused a side-effect on the server side and needs to cancel it. In this case, the application will receive a RequestCanceledException.
If it is idempotent though, the SDK will transparently retry the operation since it has a chance of succeeding eventually. Depending on the type of request, it might be able to send it to another node or the socket connection re-established before the operation times out.
If the operation needs to be retried before it is sent onto the network or after the SDK received a response, the idempotency doesn’t matter and other factors are taken into account. The following picture illustrates when idempotency is important in the request lifecycle:
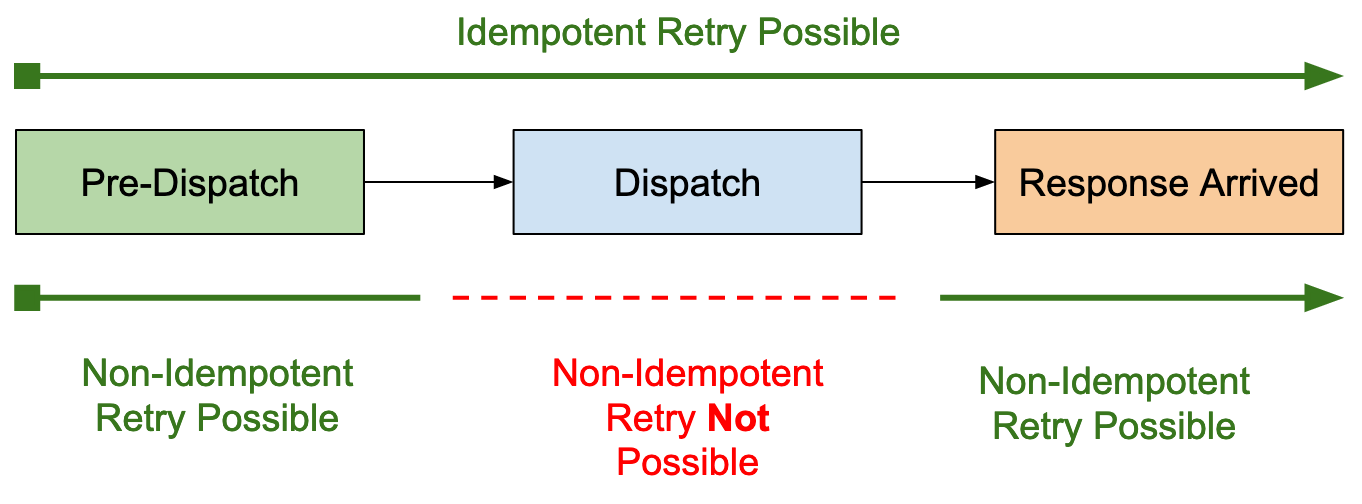
The SDK is very conservative on which operations are considered idempotent, because it really wants to avoid accidential data loss. Imagine a situation where a mutating operation is applied twice by accident but another application server changed it in the meantime. That change is lost without a chance to potentially recover it.
The following operations are considered idempotent out of the box (aside from specific internal requests that are not covered):
- Cluster:
search,ping,waitUntilReady. - Bucket:
view,ping,waitUntilReady. - Collection:
get,lookupIn,getAnyReplica,getAllReplicas,exists. - Management commands that only retrieve information.
Both query and analyticsQuery commands are not in the list because the SDK does not inspect the statement string to check if you are actually performing a mutating operation or not. If you are certain that you are only selecting data you can manually tell the client about it and benefit from idempotent retries:
QueryResult queryResult = cluster.query("SELECT * FROM `travel-sample`", queryOptions().readonly(true));
AnalyticsResult analyticsResult = cluster.analyticsQuery("SELECT * FROM `travel-sample`.inventory.airport",
analyticsOptions().readonly(true));The RetryStrategy and RetryReasons
The RetryStrategy decides whether or not a request should be retried based on the RetryReason. By default, the SDK ships with a BestEffortRetryStrategy which, when faced with a retryable error, retries the request until it either succeeds or the timeout expires.
| | SDK 2 ships with a FailFastRetryStrategy which is intended to be used by an application. SDK 3 also ships with one, but it is marked as @Internal. We recommend extending and customizing the BestEffortRetryStrategy as described in Customizing the RetryStrategy. | | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
The RetryReasons are good to look at (see the Reference section), because they give insight into why an operation got retried. The ErrorContext described in the previous chapters exposes the reasons as a list, since it is certainly possible that a request gets retried more than once because of different reasons. So a request might be retried on one occasion because the socket went down during dispatch, and then on another because the response indicated a temporary failure.
See Customizing the RetryStrategy for more information on how to tailor the default behavior to your needs.