AngelikaLanger.com - Java Multithread Support - Threadpools (original) (raw)
Java Multithread Support - Threadpools
| Java Multithread Support Threadpools JavaSPEKTRUM, Mai 2005 Klaus Kreft & Angelika Langer | Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im JavaSPEKTRUM erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar (click here). |
|---|

Der Threadpool ist eine wichtige neue Abstraktion in Java 5.0. Threadpools erlauben es, Tätigkeiten auf bereitstehende Threads verteilen und sogar ggf. Tätigkeiten in einer Taskqueue zu speichern, falls keine Poolthreads verfügbar sind. Bisher mußte man solche Threadpools selber implementieren, wenn man sie brauchte. Das wird in der Zukunft mit Java 5.0 nicht mehr nötig sein, weil der Threadpool in Java 5.0 äußerst flexibel und konfigurierbar ist. In diesem Beitrag sehen wir uns die Details des Threadpools in Java 5.0 und die damit zusammenhängenden Abstraktionen an.
Ein Threadpool ist eine Abstraktion, die eine Anzahl von erzeugten und bereits gestarteten Thread vorrätig hält, um mit ihnen asynchrone Tätigkeiten auszuführen. Zum Beispiel wird ein Application Server einen Threadpool enthalten, um die hereinkommenden Serviceanfragen asynchron damit auszuführen. Die Nutzung eines Threadpools in einem solchen Kontext hat zwei Vorteile:
- Zum einen entfällt der Overhead des Threaderzeugens, -startens und -beenden. Denn dies würde ja für jede asynchrone Tätigkeit immer wieder neu anfallen, wenn jede in einem eigenen Thread ablaufen würde. Zugegebenermaßen gibt es auch bei einem Threadpool einen Aufwand für die interne Synchronisation bei der Zuordnung von asynchronen Tätigkeiten zu Pool-Threads. Der ist aber geringer verglichen mit dem Aufwand für das Threaderzeugen, -starten und -beenden.
- Daneben sorgt ein richtig getunter Threadpool für eine gute Skalierbarkeit des Systems, in dem er genutzt wird. Dies geschieht dadurch, dass er dynamisch neue Pool-Threads bis zu einer vordefinierten maximalen Anzahl erzeugen kann. Wenn wir dabei noch einmal an das Beispiel unseres Application Servers mit Threadpool denken, bedeutet dies, dass der Server bei einer höheren Anzahl von Clients mit mehr Threads im Pool reagiert. Auf der anderen Seite kann aber auch ein noch stärkeres Anwachsen von Clients nicht dazu führen, dass der Server über die Grenzen seiner Leistungsfähigkeit hinausgebracht wird, da die maximale Anzahl der Threads beschränkt ist. Im JDK 5.0 gibt es eine standardisierte Threadpool-Implementierung, die wir uns im Folgenden ansehen wollen. Damit zusammen hängen die in Abbildung 1 gezeigten Interfaces und Klassen.
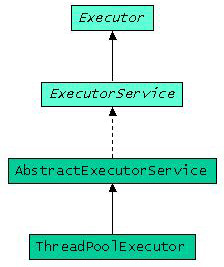
Abbildung 1: Klassen und Interfaces im Zusammenhang mit dem Threadpool
Executor, ExecutorService, AbstractExecutorService und ThreadPoolExcecutor
Executor ist ein relativ unspektakuläres Interface, das die Funktionalität anbietet, eine Tätigkeit, die Runnable implementiert hat, auszuführen. Die einzige Methode, die es dazu anbietet ist:
public void execute(Runnable command)
Abgeleitet davon gibt es das Interface ExecutorService. Es vereint zwei Aspekte: die Beendigung des Services und den Umgang mit Tätigkeiten, die ein Ergebnis liefern. Das Interface ExecutorService bietet also zum einen Service Management Funktionalität an, um den Service zu beenden, seinen Status abzufragen, usw. Die Namen der Methoden sind dabei selbsterklärend: shutdown(), shutdownNow(), awaitTermination(), isShutdown(), isTerminated().
Daneben bietet der ExecutorService Methoden an, mit denen sich Callables ausführen lassen. 1) Die zentrale Methode ist:
public Future submit(Callable task)
Da Callables Ergebnisse produzieren, liefert die submit() Methode Zugriff auf das Ergebnis in Form eines Future zurück . Man kann also eine Tätigkeit direkt als Callable an einen ExecutorService zur Ausführung übergeben und danach mit Future.get() auf das Ergebnis warten. Neben der oben gezeigten submit() Methode gibt es noch zwei Varianten, mit denen man Runnables übergeben kann, für die man dann ebenfalls ein Future zurückbekommt, mit dem man auf die Beendigung der Tätigkeit warten kann. Außerdem gibt es noch die Methode invokeAll(), mit der man gleich mehrere Tätigkeiten als Collection<Callable> auf einmal übergeben kann. Man bekommt dann entsprechend eine Liste von Futures zurück.
Für die submit() und invokeAll() Funktionalität gibt es eine Defaultimplementierung, die von der abstrakten Klasse AbstractExecutorService zur Verfügung gestellt wird. Die Implementierung ist nicht sonderlich aufregend. Die Tätigkeiten werden in FutureTasks verpackt und an die execute() Methode aus dem Superinterface Executor übergeben. Für die Bulk-Operation invokeAll() wird außerdem die Liste der Futures aufgebaut.
Richtig interessant wird es aber, wenn wir zu der Klasse kommen, die die eigentliche Threadpool-Funktionalität implementiert. Das ist die Klasse ThreadPoolExecutor. Sie liefert nun endlich die offizielle Threadpool-Implementierung im JDK, nachdem es seit dem Erscheinen von Java immer wieder Diskussionen in Artikeln, Büchern und dem Internet gab, wie ein Threadpool in Java zu implementieren sei.
Funktionweise des ThreadPoolExecutors
Wie man schon an dieser Diskussion sehen kann, ist eines der wichtigsten Kriterien eines möglichst breit einsetzbaren Threadpools, neben seiner Performance, seine umfangreiche Konfigurierbarkeit und Flexibilität in der Nutzung. Bevor wir uns aber die Tuningparameter und die Benutzungsoptionen des ThreadPoolExecutor ansehen können, sollten wir ein grundsätzliches Verständnis von seiner Funktionsweise haben. Mit der Methode
void execute(Runnable r)
wird dem ThreadPoolExecutors eine Tätigkeit (abgeleitet von Runnable) übergeben, die von einem der internen Pool-Threads ausgeführt werden soll. Da die submit() und invokeAll() Methoden letztlich auf die execute() Methode aufsetzen, können wir unsere Erläuterungen auf die execute() Methode beschränken.
Im ersten Schritt wird die Tätigkeit in einer internen Queue abgelegt. Dabei kann der ThreadPoolExecutor so konfiguriert werden, dass verschiedene Queuetypen aus den Erweiterungen des JDK 5.0 (siehe /KRE7/) zu verschiedenem Verhalten des ThreadPoolExecutor führen können. Dazu später mehr. In einem zweiten Schritt wird die Tätigkeit aus der Queue genommen und an einen freien Pool-Thread zur Ausführung übergeben. Abbildung 4 zeigt dieses zweistufige Vorgehen (wobei auch zusätzliche Elemente dargestellt sind, auf die wir noch kommen werden).
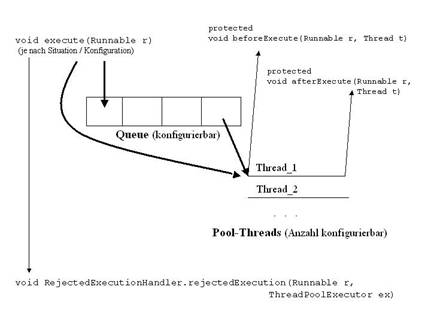
Abbildung 2: Interne Arbeitsweise des Threadpool
Für die Anzahl der Pool-Threads im ThreadPoolExecutors sind zwei Konfigurationsparameter von Bedeutung: die Kerngröße des Pools (core pool size) und die Maximalgröße des Pools (maximum pool size).
Nach dem Erzeugen einer ThreadPoolExecutor Instanz ist erst einmal gar kein Thread enthalten. Mit jedem Aufruf von execute() wird ein neuer Thread erzeugt, auch wenn ein freier Thread im Pool vorhanden ist, solange bis die Kerngröße erreicht ist.
Wenn die Poolgröße gleich der Kerngröße ist und execute() aufgerufen wird, können drei Fälle unterschieden werden:
- Es gibt mindestens einen Pool-Thread, der frei ist. In diesem Fall übernimmt dieser Thread die beim execute() mitgegebene Tätigkeit und führt sie aus.
- Es gibt keinen freien Pool-Thread, aber in der Queue ist noch Platz. Die Tätigkeit wird in die Queue gestellt und wartet dort, bis für sie ein Pool-Thread frei wird.
- Es gibt keinen freien Pool-Thread und in der Queue ist auch kein Platz mehr. Es wird ein neuer Thread gestartet, dem die erste Tätigkeit in der Queue zugewiesen wird. Damit wurde Platz für die beim execute() übergebe Tätigkeit geschaffen. So wird weiter verfahren bis die Maximalgröße des Pools erreicht ist. Wenn es keinen freien Pool-Thread gibt, die Queue voll ist und die Maximalgröße des Pools erreicht ist, so wird in einem konfigurierbaren RejectedExecutionHandler die Methode
void rejectedExecution(Runnable r, ThreadPoolExecutor executor)
aufgerufen. Dabei ist der erste Parameter die Tätigkeit, die nicht angenommen werden konnte, und der zweite Parameter der Threadpool, der sie nicht annehmen konnte.
Wenn die Anzahl der Pool-Threads größer als die Kerngröße ist und ein Pool-Thread frei wird und ihm keine neue Tätigkeit zugewiesen werden kann, weil die Queue leer ist, dann hat dieser Thread nichts zu tun. Damit dieser Thread nicht ewig arbeitslos rumsitzt und nutzlos wertvolle Ressourcen verbraucht, wird dieser Thread nach einer konfigurierbaren Zeit, der sogenannten Idle-Time, aus dem Pool genommen und beendet.
Konfiguration des ThreadPoolExecutors
Nachdem jetzt klar ist, wie der ThreadPoolExecutor funktioniert und wie die Konfigurationsparameter in seine Funktionsweise eingehen, wollen wir uns die Parameter noch einmal genauer ansehen. Alle Konfigurationsparameter werden bei der Konstruktion des ThreadPoolExecutor übergeben. Alle Konstruktoren benötigen mindestens die folgenden Parameter:
- die Kerngröße,
- die Maximalgröße,
- die interne Queue und
- das Zeitintervall, das definiert wie lange freie Pools-Threads im Pool verbleiben, wenn die Anzahl der Pool-Threads die Kerngröße übersteigt Das heißt, dies sind die Pflichtparameter für die Konstruktion eines ThreadPoolExecutor. Die Konstruktoren, prüfen die Pflichtparameter auf folgende Konsistenzen:
- Kerngröße, Maximalgröße und Zeitinterval >= 0,
- Kerngröße <= Maximalgröße und
- Queue-Parameter != null. Der RejectedExecutionHandler, der benutzt wird, wenn der Threadpool eine Anforderung, die ihm mit execute() übergeben wurde, gar nicht unterbringen kann, ist ein optionaler Konstruktor-Parameter. Im Defaultfall wird ThreadPoolExecutor.AbortPolicy benutzt, was dazu führt, dass execute() mit einer Runtime-Exception vom Typ RejectedExecutionException abgebrochen wird. Alternative Implementierungen des RejectedExecutionHandler Interface, die bereits als static Inner Classes von ThreadPoolExecutor zur Verfügung gestellt werden, sind:
- DiscardPolicy – aktuelle Anfrage wird stillschweigend ignoriert, d.h. keine Reaktion,
- DiscardOldestPolicy – die älteste Anfrage, die noch nicht an einen Thread zugewiesen worden ist, d.h. die vorderste in der Queue, wird gelöscht und damit ignoriert und somit Platz für die neue geschaffen,
- CallerRunsPolicy – der Thread, der execute() aufgerufen hat, wird dazu benutzt die Anfrage auszuführen, d.h. der Auftraggeber bearbeitet die Anfrage selber. Neben diesem vorgegebenen Standardverhalten, ist es natürlich jederzeit möglich, bei Bedarf eigene Implementierung des RejectedExecutionHandler zu benutzen, z.B. um eine interne Flusskontrolle zu aktivieren.
Ein weiterer optionaler Konfigurationparameter, den wir bisher noch gar nicht erwähnt haben, ist eine ThreadFactory, die der ThreadPoolExecutor zum Erzeugen seiner Pool-Threads benutzt. Damit ist der ThreadPoolExecutor äußerst flexibel, was die Art der Threaderzeugung angeht. Eine Threadfactory implementiert die Methode:
Thread newThread(Runnable r)
Im Defaultfall, wenn keine eigene ThreadFactory übergeben wird, wird new Thread() zum Erzeugen der Pool-Threads genutzt.
Als Queue-Parameter kann dem ThreadPoolExecutor jede Queue, die das Interface BlockingQueue implementiert, übergeben werden. Ab der Version 5.0 gibt es verschiedene Queue-spezifische Abstraktionen im JDK. Darunter sind verschiedene Klassen im Package java.util.concurrent, die der Synchronisation zwischen zwei Threads dienen, einem lesenden und einem schreibenden Thread (siehe /KRE7/).
Als Konstruktorparameter für den ThreadPoolExecutor kommen, abgesehen von Sonderfällen, im wesentlichen folgende Queues in Frage:
- ArrayBlockingQueue (Instanzen haben eine feste Größe, Array-basiert) und
- LinkedBlockingQueue (je nach Konstruktor haben Instanzen eine feste Größe oder können dynamisch wachsen, Linked-List-basiert). Wichtig für das Verhalten des ThreadPoolExecutor ist dabei primär, ob
- die übergebene Queue dynamisch wächst,
- eine feste Kapazität hat
- oder ob es sich gar um den Sonderfall handelt, bei dem man eine Queue gar keine Elemente aufnehmen kann (z.B. weil die Kapazität 0 ist). Wenn die Queue keine Element aufnehmen kann, werden die ausführbaren Tätigkeiten gar nicht zwischengespeichert, sondern direkt auf freie Pool-Threads verteilt. Sind diese bereits ausgeschöpft sind, d.h. die maximale Poolgröße ist erreicht, werden sie an den RejectedExecutionHandler übergeben.
Bei einer dynamisch wachsenden Queue wird der Pool niemals mehr Threads enthalten, als durch die Kerngröße spezifiziert wurde. Der Grund liegt im bereits oben diskutierten Verhalten des ThreadPoolExecutor: es werden erst mehr Threads erzeugt, als durch die Kerngröße spezifiziert, wenn die Queue voll ist. Dies ist bei einer dynamisch wachsenden Queue aber nie der Fall.
Wie sollte man jetzt die Queue und die Poolgrößen wählen?
Eine Queue, die keine Elemente aufnehmen kann, macht dann Sinn, wenn relativ gut vorhersehbar ist, wie viele parallele Tätigkeiten ablaufen werden, und diese Anzahl relativ klein ist. Man wird in diesem Fall für jede Tätigkeit einen Pool-Thread vorsehen.
Die Nutzung einer dynamisch wachsenden Queue ist sinnvoll, um kurzzeitige, erratische Lastspitzen abzufangen. Sie ist aber nicht sinnvoll, wenn über längere Zeit mehr Aufträge an den Threadpool übergeben werden, als abgearbeitet werden können, denn dann würde die Queue extrem wachsen.
In allen anderen Fällen ist eine Queue mit fester Größe und einem passenden RejectedExecutionHandler die beste Wahl. Hier stellt sich dann die Frage, wie Poolgröße und Queuegröße zueinander zu wählen sind. Dabei kann man sich an zwei Extremen orientieren, die es zu vermeiden gilt:
- Zu kleine Poolgröße: Wenn die auszuführenden Tätigkeiten häufig an anderen Systemressourcen als der CPU warten müssen (z.B.: Hardisk-I/O, Netz-I/O, usw. ), kann es vorkommen, dass zwar alle Pool-Threads ausgelastet sind, die CPU-Leistung des Systems aber nicht voll ausgeschöpft wird: die Threads sind voll damit beschäftigt, an anderen Ressourcen als der CPU zu warten und nutzen die CPU praktisch nicht. In diesem Fall ist es sinnvoll, die Poolgröße zu erhöhen und damit mehr potentielle CPU-Nutzer ins System zu bringen.
- Zu große Poolgröße: Wenn sehr viele Threads um die CPU Ressource konkurrieren, bekommen die einzelnen Threads die CPU nur kurz, während das Threadscheduling des Systems, sowie die Verwaltung beim Kontextwechsel, übermäßig viel CPU-Zeit verbraucht. In einem solchen Fall ist es sinnvoll, die Anzahl der Poolthreads zu verringern, um den Scheduling-Overhead zu reduzieren. D.h. in der Praxis ist es sinnvoll, erst über ein Profiling eine angemessene Poolgröße zu bestimmen und ausgehend von dieser, die Queuegröße zu bestimmen. Danach kann man sich noch überlegen, in welchem Maße man Anforderungsspitzen über
- mehr Threads (d.h. maximale Threadgröße erhöhen),
- eine größere Queue oder
- einen geeigneten RejectedExecutionHandler (z.B. eine Wait-Policy, d.h. der Erzeugerthread der auszuführenden Tätigkeit wartet) behandelt.
Alle Konfigurationsparameter, außer der Queue, können übrigens auch dynamisch, in der ThreadPoolExecutor Instanz geändert werden. D.h. die dynamische Anpassung muss nicht allein der ThreadPoolExecutor Instanz selbst überlassen werden, sondern kann zusätzlich noch von außen gesteuert werden. Dies macht eine Lösung aber natürlich auch noch deutlich komplexer und wird gerade auf Grund der hohen Flexibilität des ThreadPoolExecutor nur in Ausnahmefällen nötig sein.
Factory Methoden zur Erzeugung von ThreadPoolExecutor Instanzen
Wer sich nicht mit den Details der Konfiguration des ThreadPoolExecutor auseinandersetzen will, dem bietet die Helper-Klasse Executors verschiedene statische Factory-Methoden an, mit denen sich Threadpools mit spezifischen Charakteristika einfach erzeugen lassen. Da gibt es zum Beispiel die Methode newSingleThreadExecutor(), die einen Threadpool mit einem Thread und unbegrenzt wachsender Queue erzeugt. Damit ist sichergestellt, dass alle übergebenen Tätigkeiten streng sequenziell abgearbeitet werden und auch in Fällen von Lastspitzen alle Tätigkeiten gespeichert werden können. Daneben gibt es die Methode newFixedThreadPool(), die einen Threadpool mit einem einer festen Anzahl Threads und unbegrenzt wachsender Queue erzeugt. Mit der Methode newCachedThreadPool() wird ein Threadpool erzeugt, der Threads bei Bedarf erzeugt, wenn keine freien vorhanden sind. Threads, die für 60 Sekunden nicht benutzt wurden, werden aus dem Pool entfernt. Da jedesmal bei Bedarf Threads erzeugt werden, eignet sich die Abstraktion im wesentlichen für kurzlebige Tätigkeiten, die asynchron zueinander ablaufen dürfen und unter Umständen mit starken Schwankungen auftreten können.
Ableiten vom ThreadPoolExecutor
Wem all diese Konfigurationsmöglichkeiten nicht ausreichen, der kann natürlich auch von ThreadPoolExecutor ableiten, denn die Klasse ist nicht final. Sie bietet vielmehr drei Templatemethoden (im Sinne des gereichnamigen GOF-Pattern /GOF/) an. Sie sind protected und können dem Pattern entsprechend von abgeleiteten Klassen überschrieben werden.
Zwei der Templatemethoden werden im Zusammenhang mit der Ausführung einer Tätigkeit durch einen Pool-Thread benutzt. Die Methode:
void beforeExecute(Thread t, Runnable r)
wird aufgerufen, bevor der Thread t die asynchrone Tätigkeit r ausführt und
void afterExecute(Thread t, Runnable r)
wird aufgerufen, nachdem der Thread t die asynchrone Tätigkeit r ausgeführt hat. Überschreibt man zusätzlich zu diesen beiden Templatemethoden noch die execute() Methode und hängt einen passenden RejectedExecutionHandler ein, so lässt sich damit zum Beispiel sehr präzise mittracen, wie und wann die einzelnen Tätigkeiten durch den ThreadPoolExecutor verarbeitet werden.
Die dritte und letzte Template Methode ist:
void terminated()
Sie wird aufgerufen, nachdem der ThreadPoolExecutor beendet worden ist.
ThreadPoolExecutor API
Bis jetzt haben wir im wesentlichen die innere Funktionsweise sowie die Konfigurierbarkeit des ThreadPoolExecutor diskutiert. Kommen wir abschließend noch einmal zu einer kurzen Zusammenfassung des ThreadPoolExecutor API. Dieser besteht erst einmal aus den Methoden des Executor und ExecutorService, die wir beide bereits oben diskutiert haben.
Weiter enthält der API die Methoden, um Konfigurationsparameter (z. B. die Kerngröße des Pools) zu lesen und zu schreiben. Die Methoden heißen setCorePoolSize(), getKeepAliveTime(), usw. Man kann einen oder alle Pool-Threads vorab starten, so dass sie bereits auf Tätigkeiten warten. Dazu dienen die Methoden prestartAllCoreThreads() und prestartCoreThread().
Daneben gibt es noch verschiedene Methoden, die dem Benutzer Profiling-Information über den ThreadPoolExecutor geben:
- int getLargestPoolSize() – Ermittelt die größte Poolgröße, die bisher benötigt wurde.
- int getActiveCount() – Ermittelt die Anzahl der aktiven Pool-Threads.
- long getTaskCount() – Ermittelt die Anzahl der Tätigkeiten, die bisher an den übergeben wurden und nicht zurückgewiesen wurde.
- long getCompletedTaskCount() – Ermittelt die Anzahl Tätigkeiten, die bisher durchgelaufen sind. Man hat auch die Möglichkeit, Tätigkeiten aus der internen Queue zu entfernen. Mit remove(Runnable task) kann beispielsweise eine Tätigkeit, die noch nicht gestartet wurde, aus der Queue entfernt werden. Mit purge() werden alle Tätigkeiten entfernt, die über ihr Future schon abgebrochen worden sind. Es klingt vielleicht etwas seltsam, dass abgebrochene Tätigkeiten in der Queue stehen, aber das kann durchaus vorkommen. Wenn der Benutzer mit submit() eine Tätigkeit übergibt, bekommt er ein Future auf diese Tätigkeit zurück. Über dieses Future kann der Benutzer die Tätigkeit abbrechen. Dieser Abbruch kann passieren, bevor die Tätigkeit zur Ausführung gekommen ist, also wenn sie noch in der Queue steht. Genau solche bereits abgebrochenen Tätigkeiten würde purge() aus der Queue entfernen.
Insgesamt ist die Threadpool-Implementierung, die mit der Klasse ThreadPoolExecutor zur Verfügung steht, äußerst flexibel und dynamisch konfigurierbar (durch Parameter und Spezialisierung per Vererbung). Dazu hat die Threadpool-Implementierung ein breites API für die Verwaltung des Threadpools. Das einzige, was noch fehlt, ist Unterstützung beim Aufsammeln der Ergebnisse, die von den Tätigkeiten u.U. erzeugt werden. Diese Funktionalität ist in eine separate Abstraktion, den CompletionService, ausgelagert.
CompletionService und ExecutorCompletionService
Es kann vorkommen, dass man das Erzeugen und Starten von Tätigkeiten entkoppeln möchte vom Abholen und Verarbeiten der Ergebnisse, die diese Tätigkeiten erzeugt haben. Das ist beispielsweise der Fall, wenn mit asynchroner I/O gearbeitet wird. Dann könnte ein Teil der Applikation die Lese-Tasks erzeugen und einem Threadpool zur Ausführung übergeben, während ein ganz anderer Teil der Applikation die eingelesenen Daten später in Empfang nimmt und verarbeitet. Diese Arbeitsteilung wird vom Ergebnisservice (engl. Completion Service) unterstützt.
Definiert ist die Funktionalität durch das Interface CompletionService. Es hat submit() Methoden, mit denen man ähnlich wie beim ExecutorService Callables und Runnables zur Ausführung übergeben kann.
Future submit(Callable task)
Future submit(Runnable task, V result)
Die Idee dabei ist, dass ein Ergebnisservice in der Regel einen Threadpool verwenden wird, der die Tätigkeiten ausführt.
Zusätzlich hat das CompletionService Interface eine take() und zwei poll() Methoden, mit denen das jeweils nächste Ergebnis abgeholt werden kann.
Future take()
Future poll()
Future poll(long timeout, TimeUnit unit)
Die Methode take() wartet, falls kein Ergebnis da ist und die Methode poll() kehrt sofort, oder nach einem Timeout, zurück und liefert null, wenn kein Ergebnis da war. Das Ergebnis wird wie immer in Form eines Future geliefert. Man bekommt also nicht direkt das Ergebnis, sondern ein Future, über das man das Ergebnis abholen kann oder auch darauf warten kann. Die Idee für take() und poll() ist, das der Ergebnisservice intern eine Ergebnisqueue hält, in die er das Future jeder Tätigkeit stellt, sobald diese fertig ist. Dabei ist es unerheblich, ob die Tätigkeit normal beendet oder abgebrochen wurde. Die Futures erscheinen also in der Ergebnisqueue in der Reihenfolge, in der sie fertig geworden sind, und diese Reihenfolge ist im Allgemeinen anders als die Reihenfolge, in der sie mit submit() zur Ausführung übergeben wurden.
Die Klasse ExecutorCompletionService implementiert das CompletionService Interface. Sie hat Konstruktoren, denen man einen Executor (den Threadpool) und optional eine BlockingQueue<Future> (die Ergebnisqueue) mitgibt. Wenn keine Queue mitgegeben wird, dann wird defaultmäßig eine LinkedBlockingQueue<Future> verwendet.
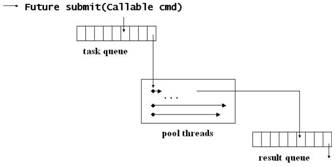
Abbildung 3: Interne Arbeitsweise des Ergebnisservices unter Verwendung seines Threadpools
Sehen wir uns ein einfaches Anwendungsbeispiel an. Nehmen wir an, wir hätten eine Reihe von Tätigkeiten und wir wollen diese Tätigkeiten parallel ablaufen lassen. Anschließend wollen wir uns die Ergebnisse ansehen und verarbeiten. In unserem Beispiel wird die Tätigkeit eine Primzahlberechnung sein und das Ergebnis ist jeweils eine Liste von Integers, nämlich die berechneten Primzahlen. Das Beispiel ist nicht besonders realistisch, weil die Primzahlen redundant berechnet werden, aber für die Illustration des Prinzips ist es ausreichend.
public final class PrimeNumberCalculator implements Callable<List> {
private List primeNumbers = new ArrayList();
private int upperBound = 0;
public PrimeNumberCalculator(int i) { upperBound = i; }
public List call() {
… Sieb des Eratosthenes …
return primeNumbers;
}
}
public final class Solver {
private static void use(Object result) {
System.out.println(result);
}
private static void solve(Collection<? extends Callable<List>> tasks)
throws InterruptedException, ExecutionException {
gather(scatter(tasks),tasks.size());
}
private static CompletionService<List>
scatter(Collection<? extends Callable<List>> solvers)
throws InterruptedException {
ExecutorService threadPool = Executors.newFixedThreadPool(5); // 1
CompletionService<List> ecs
= new ExecutorCompletionService<List>(threadPool); // 2
for (Callable<List> s : solvers)
ecs.submit(s); // 3
threadPool.shutdown();
return ecs;
}
private static void gather(CompletionService<List> ecs, int n)
throws InterruptedException, ExecutionException {
for (int i = 0; i < n; ++i) {
List r = ecs.take().get(); // 4
if (r != null)
use(r);
}
}
public static void main(String[] args) {
Collection tasks = new ArrayList();
for (int i=0; i<10; i++) {
tasks.add(new PrimeNumberCalculator(10*i));
}
try {
solve(tasks);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
In der Klasse Solver sieht man eine typische Zerlegung der Aufgabe in eine Scatter-Phase, in der die Tätigkeiten gestartet werden, und eine Gather-Phase, in der die Ergebnisse abgeholt und verarbeitet werden. Die Methode scatter() erzeugt einen Threadpool mit Hilfe einer der Factory-Methoden (in Zeile 1), übergibt ihn an einen Ergebnisservice mit Default-Ergebnisqueue (in Zeile 2) und übergibt dann alle Tasks über den Ergebnisservice an den Threadpool (in Zeile 3). Die Methode gather() holt sich aus der Ergebnisqueue des Ergebnisservice alle Ergebnisse ab (in Zeile 4) und verarbeitet sie. Das Resultat könnte dann beispielsweise so aussehen:
[]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89]
[2, 3, 5, 7]
[2, 3, 5, 7, 11, 13, 17, 19]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
Man sieht deutlich, dass die Reihenfolge der Ergebnisse von der Reihenfolge abweicht, in der die Primzahlberechnungen gestartet wurden.
ScheduledExecutorService und ScheduledThreadPoolExecutor
Bisher nicht betrachtet haben wir solche Tätigkeiten, die entweder periodisch oder aber nach einer bestimmten Zeitspanne ausgeführt werden sollen. Dafür gibt es einen speziellen Threadpool, beschrieben über das Interface ScheduledExecutorService und die implementierende Klasse ScheduledThreadPoolExecutor, jeweils abgeleitet von ihren Namensvettern. In dieser Art von Threadpool gibt es zusätzlich zu den Methoden execute() und submit(), die wir aus dem normalen Threadpool kennen, diverse schedule() Methoden, mit denen sich das gewünschte Timing erreichen läßt. Eine ausführliche Diskussion des Threadpools für periodische oder terminabhängige Tätigkeiten würde den Rahmen des Artikels sprengen. Nur ganz kurzein paar Bemerkungen zur Abgrenzung gegen den Timer aus dem JDK 1.3.
Eine ähnliche Abstraktion für die Ausführung von periodischen und terminabhängigen Tätigkeiten gibt es schon seit JDK 1.3 mit java.util.Timer. Der Timer führt alle Tätigkeiten in einem einzigen Thread aus, wohingegen der ScheduledThreadPoolExecutor ein Threadpool ist, der je nach Konfiguration beliebig viele Threads für das termingerechte Ausführen der Tätigkeiten zur Verfügung hat. Das ist natürlich sicherer, weil es bei Verwendung eines Pools nicht vorkommen kann, dass eine Tätigkeit alle anderen aufhält, weil sie schrecklich lange dauert. Beim Timer, der ja nur einen einzigen Thread zur Verfügung hat, kann es tatsächlich passieren, dass sich die Tätigkeiten stauen und deshalb nicht zum gewünschten Termin ausgeführt werden können, sondern erst mit Verspätung. In solchen Situationen ist der ScheduledExecutorService natürlich die bessere Alternative.
Tuning-Tipps
Jetzt haben wir uns ausführlich alle Features des Standard-Threadpools in Java 5.0 angesehen. Da stellt sich abschließend die Frage: wann braucht man überhaupt einen Threadpool oder wann sollte man die Verwendung eines Pools vermeiden? Der Threadpool ist eine gute Lösung in Anwendungen, in denen eine große Anzahl von kurzlebigen, voneinander unabhängigen Aufgaben erledigt werden muß. Das ist typisch für Server, die jeden Request von einem eigenen Worker-Thread bearbeiten lassen.
Eine ganz andere Situation liegt vor, wenn die Anwendung eine geringe Zahl von lang andauernden Aufgaben auf Threads verteilen will. Dann ist der Threadpool nicht unbedingt die ideale Lösung. Eine lang andauernde Tätigkeit, die beispielsweise auf I/O wartet oder auf Benutzereingaben an einer Benutzeroberfläche, blockiert einen Pool-Thread unnötig lange. Der blockierte Pool-Thread könnte wesentlich effektiver genutzt werden, um andere kurzlebige Tätigkeiten erledigen. Um eine höhere Auslastung des Pools zu erreichen, kann man die langwierigen Tätigkeiten nach einer gewissen Zeit abbrechen und das Scheitern melden, oder die Aufgabe einfach noch einmal in die Queue stellen für eine erneute Bearbeitung zu einem späteren Zeitpunkt. Das muß aber explizit so programmiert werden; automatisch passiert das im Standard-Threadpool nicht. Lang-andauernde Aufgaben sollten daher nur mit Bedacht an einen Pool übergeben werden.
Prinzipiell kann man auch lang andauernden Tätigkeiten über einen Standard-Threadpool erledigen lassen, aber dieser Pool muß anders konfiguriert sein als ein Pool, der viele kurzlebige Aufgaben zu erledigen hat. Für ein effektives Tuning eines Threadpools ist daher immer eine gute Einschätzung der Eigenschaften der Aufgaben erforderlich. Sind die Aufgaben CPU-intensiv, oder warten sie lange auf I/O oder anderes? Dauern sie lange oder geht es schnell? Wenn es in der Anwendung radikal verschiedenen Aufgaben gibt, dann ist es u.U. sinnvoll, anstelle von nur einem Threadpool mehrere unterschiedlich konfigurierte Threadpools zu verwenden.
Vorsicht ist nicht nur bei den langwierigen Aufgaben geboten, sondern auch bei Tätigkeiten, die stark voneinander abhängen. Wenn Aufgaben auf einen Threadpool verteilt werden, die aufeinander warten., dann kann es passieren, daß alle Pool-Threads eine Aufgabe erledigen, die auf ein Ergebnis einer anderen Aufgabe warten, die noch in der Task-Queue hängt und nicht ausgeführt werden kann, weil es keine, freien Pool-Thread mehr gibt. Das ist eine Art Deadlock, weil die aktiven Pool-Threads auf ein Ergebnis warten, das aber nicht produziert werden kann, weil alle verfügbaren Threads mit Warten „beschäftigt“ sind. Ein Threadpool ist deshalb für kooperierende Thread nicht unbedingt die geeignete Lösung. Man sollte daher darauf achten, daß die an einen Pool übergebenen Aufgaben nach Möglichkeit voneinander unabhängig sind.
Ideal ist der Threadpool, wie schon gesagt, für Anwendungen, in denen eine große Anzahl von kurzlebigen, voneinander unabhängigen Aufgaben erledigt werden muß.
Zusammenfassung
Für das Ausführen von Threads sind in Java 5.0 viele neue Abstraktionen zum JDK hinzugekommen. Es gibt eine flexibel konfigurierbare Threadpool-Implementierung, mit deren Hilfe sich Tätigkeiten auf bereitstehende Threads verteilen und sogar ggf. in einer Taskqueue cachen lassen. Hinzu kommt der Ergebnisservice, der die Resultate in einer Ergebnisqueue zur Abholung bereitstellt. Zusammen mit den Queues und den Synchronisatoren, die wir im vorletzten Artikel besprochen haben, ist es jetzt relativ einfach, stabile und fehlerfreie Multithread-Programme zu schreiben. Viele der fehleranfälligen Details der Synchronisation sind jetzt in den neuen Abstraktionen des java.util.concurrent Packages gekapselt und dort zuverlässig gelöst.
Damit endet unsere Reihe über Multithread-Programmierung. In der nächsten Ausgabe wenden wir uns einem neuen Themenkreis zu.
Literaturverweise
Fußnoten
| 1) | Callables haben wir in /KRE8/ besprochen. Callable ist ein Interface wie Runnable. Statt der run() Methode hat es eine call() Methode. Der wesentliche Unterschied zum Runnable besteht darin, dass die call() Methode des Callable ein Ergebnis liefert und auch Exceptions werfen kann, was die run() methode des Runnable nicht tut. Das Callable ist außerdem parametrisiert, also ein Callable, und der Typparameter V ist der Returntyp von call().Futures haben wir ebenfalls in /KRE8/ besprochen. Ein Future ist eine Abstraktion, mit der man das Ergebnis einer Tätigkeit abholen kann und ggf. auf das Ergebnis warten kann, falls nötig. | BACK |
|---|
 If you are interested to hear more about this and related topics you might want to check out the following seminar: If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|---|
Seminar  Concurrent Java - Java Multithread Programming 4 day seminar (open enrollment and on-site) Concurrent Java - Java Multithread Programming 4 day seminar (open enrollment and on-site) |