Generate SIMD Code from Simulink Blocks for Intel Platforms - MATLAB & Simulink (original) (raw)
You can generate single instruction, multiple data (SIMD) code from certain Simulink® blocks by using Intel® SSE and, if you have Embedded Coder®, Intel AVX technology. SIMD is a computing paradigm in which a single instruction processes multiple data. Many modern processors have SIMD instructions that, for example, perform several additions or multiplications at once. For computationally intensive operations on supported blocks, SIMD intrinsics can significantly improve the performance of the generated code on Intel platforms.
To generate SIMD code by using the Embedded Coder Support Package for ARM® Cortex®-A Processors, see Generate SIMD Code from Simulink Blocks for ARM Platforms.
Blocks That Support SIMD Code Generation for Intel
When certain conditions are met, you can generate SIMD code by using Intel SSE or Intel AVX technology. This table lists blocks that support SIMD code generation. The table also details the conditions under which the support is available. Some other blocks support SIMD code generation when they generate control flow code that the code generator can convert to vectorized code. For example, the code generator can replace some for-loops that contain conditional expressions with SIMD instructions.
| Block | Conditions |
|---|---|
| Add | For AVX, SSE, and FMA, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int8, int16,int32, orint64. For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Subtract | For AVX, SSE, and FMA, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int8, int16,int32, orint64.For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Sum of Elements | For AVX, SSE, and FMA, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int8, int16,int32, orint64. For AVX512F, the input signal has a data type of single,double,int32, orint64.The Optimize reductions configuration parameter is set toon. |
| Product | For AVX, SSE, and FMA, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int16 orint32. For AVX512F, the input signal has a data type of single ordouble.Set Multiplication parameter toElement-wise(.*) |
| Product of Elements | For AVX, SSE, and FMA, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int16 orint32. For AVX512F, the input signal has a data type of single ordouble.Set Multiplication parameter toElement-wise(.*)Set the Optimize reductions configuration parameter toon. |
| Gain | For AVX, and SSE, the input signal has a data type of single ordouble. For AVX2, SSE4.1, and SSE2, the input signal has a data type of single,double,int16, orint32. For Intel AVX512F, the input signal has a data type of single ordouble.Set Multiplication parameter toElement-wise(.*) |
| Divide | The input signal has a data type ofsingle ordouble. |
| Sqrt | The input signal has a data type ofsingle ordouble. |
| Ceil | For AVX2, AVX, SSE4.1, SSE2, and SSE, the input signal has a data type ofsingle ordouble.AVX512F is not supported. |
| Floor | For AVX2, AVX, SSE4.1, SSE2, and SSE, the input signal has a data type ofsingle ordouble.AVX512F is not supported. |
| MinMax | The input signal has a data type ofsingle ordouble. |
| MinMax of Elements | The input signal has a data type ofsingle ordouble.The value of the Support: non-finite numbers configuration parameter is set to off.The Optimize reductions configuration parameter is set toon. |
| MATLAB Function | MATLAB code meets the conditions specified in this topic: Generate SIMD Code from MATLAB Functions for Intel Platforms. |
| For Each Subsystem | The For Each Subsystem block contains a block listed in this table that meets the specified conditions.The value of the Partition Dimension block parameter must be above the value of the Loop unrolling threshold configuration parameter. |
| Bitwise Operator | The value of theOperator block parameter must be AND, OR, or XOR.For SSE2, the input signal has a data type of int8,int16,int32, orint64. For AVX2, and AVX512F, the input signal has a data type of int8,int16,int32, orint64. |
| Shift Arithmetic | The input signal has a data type ofint32. |
| Relational Operator (less than) | For SSE4.1, the input signal has a data type of single,double, orint32. For AVX, the input signal has a data type ofsingle ordouble. For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Relational Operator (less than or equal to) | For SSE4.1 and AVX, the input signal has a data type of single ordouble. For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Relational Operator (greater than) | For SSE4.1, the input signal has a data type of single,double, orint32. For AVX, the input signal has a data type ofsingle ordouble. For AVX2, the input signal has a data type of int32 orint64. For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Relational Operator (greater than or equal to) | For SSE4.1 and AVX, the input signal has a data type of single ordouble. For AVX512F, the input signal has a data type of single,double,int32, orint64. |
| Relational Operator (equality) | For SSE4.1 and AVX, the input signal has a data type of single ordouble.For AVX2 and AVX512F, the input signal has a data type of single,double,int32, orint64. |
If you have DSP System Toolbox™, you can also generate SIMD code from certain DSP System Toolbox blocks. For more information, see Simulink Blocks in DSP System Toolbox that Support SIMD Code Generation (DSP System Toolbox).
Generate SIMD Code Compared to Plain C Code
For this example, create a simple model simdDemo that has a Subtract block and a Divide block. The Subtract block has an input signal that has a dimension of 240 and an input data type ofsingle. The Divide block has an input signal that has a dimension of 140 and an input data type of double.
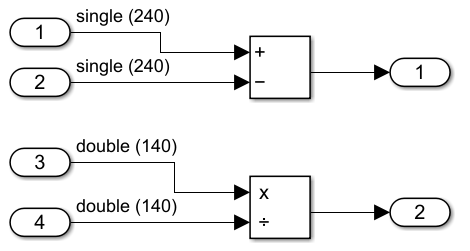
The plain generated C code for this model is:
void simdDemo_step(void) { int32_T i; for (i = 0; i < 240; i++) { simdDemo_Y.Out1[i] = simdDemo_U.In1[i] - simdDemo_U.In2[i]; }
for (i = 0; i < 140; i++) { simdDemo_Y.Out2[i] = simdDemo_U.In3[i] / simdDemo_U.In4[i]; } }
In the plain (non-SIMD) C code, each loop iteration produces one result.
To generate SIMD code:
- Open the Simulink Coder™ app or the Embedded Coder app.
- Click > .
- Set the Device vendor parameter to
IntelorAMD. - Set the Device type parameter to
x86-64(Windows 64)orx86-64(Linux 64). - On the Optimization pane, for the**Leverage target hardware instruction set extensions** parameter, select the instruction set extension that your processor supports. For example, select
SSE2. If you use Embedded Coder, you can also select from the instruction setsSSE,SSE4.1,AVX,AVX2,FMA, andAVX512F. For more information, see https://www.intel.com/content/www/us/en/support/articles/000005779/processors.html. - Optionally, select the Optimize reductions parameter to generate SIMD code for reduction operations.
- Generate code from the model.
void simdDemo_step(void) { int32_T i; for (i = 0; i <= 236; i += 4) { _mm_storeu_ps(&simdDemo_Y.Out1[i], _mm_sub_ps(_mm_loadu_ps(&simdDemo_U.In1[i]), _mm_loadu_ps(&simdDemo_U.In2[i]))); }
for (i = 0; i <= 138; i += 2) { _mm_storeu_pd(&simdDemo_Y.Out2[i], _mm_div_pd(_mm_loadu_pd(&simdDemo_U.In3[i]), _mm_loadu_pd(&simdDemo_U.In4[i]))); } }
This code is for the SSE2 instruction set extension. The SIMD instructions are the intrinsic functions that start with the identifier _mm. These functions process multiple data in a single iteration of the loop because the loop increments by four for single data types and by two for double data types. For models that process more data and are computationally more intensive than this one, the presence of SIMD instructions can significantly speed up the code execution time.
For a list of a Intel intrinsic functions for supported Simulink blocks, see https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html.
Limitations
The generated code is not optimized through SIMD if:
- The input signal of the block has a complex data type and the base data type is not
singleordouble. - The code in a MATLAB Function block contains scalar data types outside the body of loops. For instance, if
a,b, andcare scalars, the generated code does not optimize an operation such asc=a+b. - The code in a MATLAB Function block contains indirectly indexed arrays or matrices. For instance if
A,B,C, andDare vectors, the generated code is not vectorized for an operation such asD(A)=C(A)+B(A). - The blocks within a reusable subsystem might not be optimized.
- If the code in a MATLAB Function block contains parallel for-Loops (
parfor), theparforloop is not optimized with SIMD code, but loops within the body of theparforloop can be optimized with SIMD code. - Polyspace® does not support analysis of generated code that includes SIMD instructions. Disable SIMD code generation by setting theLeverage target hardware instruction set extensions parameter to
None.
Related Topics
- Generate SIMD Code from MATLAB Functions for Intel Platforms
- Generate SIMD Code from Simulink Blocks for ARM Platforms
- Use Intel AVX2 Code Replacement Library to Generate SIMD Code from Simulink Blocks (DSP System Toolbox)
- Use Intel AVX2 Code Replacement Library to Generate SIMD Code from MATLAB Algorithms (DSP System Toolbox)