Partition Parallel Pools to Optimize Resource Use - MATLAB & Simulink (original) (raw)
Pool partitions are segments of an existing parallel pool that you configure and use for specific parallel workflows. You can configure the pool partition to target specific workers, cluster hosts, or GPU devices without having to restart the original pool. Using the partition function, you can partition pools that allocate specific workers to different tasks or create multiple pools to run different parallel workflows simultaneously. You can partition local machine or cluster pools.
Both the original pool and its partitions share the same underlying collection of workers, meaning using one pool can delay the execution of work on another. Pool partitions inherit some properties from the original pool and changes to these properties apply to all partitions:
AttachedFilesFileStoreValueStoreIdleTimeout
Pool partitions provide flexibility in managing and optimizing resource use. The information in this table helps you to decide which pool partitioning strategy to use.
The following sections describe advanced workflows that demonstrate the full potential of pool partitioning. While pool partitioning can be useful for specific use cases, you might not need to use them in typical scenarios.
Partition Pool by GPU Resources
If your current parallel pool has access to GPU resources and you want to run tasks on a GPU in the background or on a parallel pool with multiple GPUs, you no longer need to delete the current pool and start a new one. Instead, you can create a pool partition with one worker per available GPU. This setup allows you to run GPU intensive applications on a dedicated GPU pool. Additionally, you can return another partition with the remaining CPU workers, providing access to both GPU and CPU resources. This enables you to execute tasks on the GPU and CPU pool partitions simultaneously, optimizing resource use on a local machine or a remote cluster pool.
Separate GPU Resources
This example shows how to partition a dedicated GPU parallel pool from an existing interactive parallel pool. For GPU intensive applications like deep learning, creating a GPU only pool dedicates resources to these applications.
In this example, the gpuCluster profile requests a parallel pool with four GPUs. Start a parallel pool of 16 workers using the gpuCluster profile.
pool = parpool("gpuCluster",16);
Starting parallel pool (parpool) using the 'gpuCluster' profile ... Connected to parallel pool with 16 workers.
Use the partition function to create a pool partition with one worker for each available GPU for best performance.
gpuPool = partition(pool,"MaxNumWorkersPerGPU",1);
You can now use the gpuPool pool partition for workflows that require multiple GPUs.
For example, if you have Deep Learning Toolbox™, you can use a parfor-loop to train multiple deep learning networks in parallel on the GPU pool partition. This code snippet shows how to perform a parallel parameter sweep of mini-batch sizes by training several networks inside aparfor-loop. To run theparfor-loop on the gpuPool pool partition, specify the gpuPool pool object as the second argument to the parfor function. To try an example showing how to train multiple networks usingparfor, see Use parfor to Train Multiple Deep Learning Networks (Deep Learning Toolbox).
parfor(idx = 1:numMiniBatchSizes,gpuPool)
miniBatchSize = miniBatchSizes(idx);
% Define the training options.
options = trainingOptions("sgdm", ...
MiniBatchSize=miniBatchSize, ... % Set the mini-batch size.
ExecutionEnvironment=gpu,... % Train on the GPU
Verbose=false);% trainedNetworks{idx} = trainnet(...,options); end
Use GPU and CPU Resources Concurrently
This example shows how to partition pools for GPU and CPU tasks and run code on both pools simultaneously.
In this example, you have a GPU on your local machine. You can partition a pool for the GPU worker and another pool for the CPU workers.
Create a pool of process workers on your local machine.
pool = parpool("Processes",6);
Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 6 workers.
Use the partition function to create a pool partition with one worker for the available GPU. Also return a pool partition with the remaining workers that do not have access to a GPU.
[gpuPool,cpuPool] = partition(pool,"MaxNumWorkersPerGPU",1);
Define a function that models the growth of a population by iterating a logistics map equation.
function [r,x] = populationGrowth(N,numIterations) r = gpuArray.linspace(0,4,N); x = rand(1,N,"gpuArray"); for n=1:numIterations x = r.x.(1-x); end end
Submit a parfeval computation to run the populationGrowth function on the gpuPool pool partition. parfeval does not block MATLAB, which means you can continue executing commands.
f = parfeval(gpuPool,@populationGrowth,2,200000,1000);
While the parfeval computation is running on the GPU in the background, run a parfor-loop on the remaining workers in the cpuPool pool partition. Specify the cpuPool object as the second argument to the parfor function.
M = 100; N = 1e6; data = rand(M,N); parfor(idx = 1:M,cpuPool) out(idx) = sum(data(idx,:))./N; end
Collect the results from the parfeval computation when it is ready using the fetchOutputs function. The fetchOutputs function waits until the future finishes.
Partition Pool by Unique Host
A host is a machine that runs MATLAB® workers. On a local pool, this is your computer. On a cluster pool, it refers to the machines within the cluster. A cluster pool can have workers running on multiple hosts. Partitioning a pool by unique host is ideal for tasks that benefit from host-specific configurations and full memory or CPU utilization.
Execute Setup Code on Worker Hosts
When your workflow requires running setup code for every host machine that runs the workers in the pool, partitioning the pool by host allows you to run the setup code only once for each host. This example shows how to run a custom setup function for each host in the pool.
Start a parallel pool of 64 workers using the remote cluster profile myCluster.
myClusterPool = parpool("myCluster",64);
Starting parallel pool (parpool) using the 'myCluster' profile ... Connected to parallel pool with 64 workers.
Create a pool partition from the myClusterPool with one worker per host.
hostPool = partition(myClusterPool,"MaxNumWorkersPerHost",1);
Use the parfevalOnAll function to run the downloadData helper function asynchronously on all workers in the hostPool pool. Wait for the future to complete and check for errors from the workers using the fetchOutputs function. The downloadData function is attached to this example as a supporting file.
fSetup = parfevalOnAll(hostPool,@downloadData,1); fetchOutputs(fSetup)
ans = 2×1 string "Data download complete on host: phvjeq9c-01.company.com" "Data download complete on host: phvjeq9c-02.company.com"
Maximize Memory for Data Intensive Computations
This example shows how to maximize the memory available on an existing interactive parallel pool for data intensive computations.
The performance of data intensive computations greatly depends on matrix size. When performing data intensive computations on cluster pools, computations become inefficient if matrices occupy 50% or more of the system memory available to each worker. If a matrix size exceeds this threshold, you can experience a performance decrease as the operating system begins swapping memory to disk. When your data parallel computation requires more memory than what is available to the workers in your pool, consider decreasing the number of workers per host in your pool using the partition function. Although this results in a pool partition with fewer workers, each worker has access to more system memory for data intensive computations.
Start a parallel pool of 16 workers using the remote cluster profile myCluster. In this example, assume every worker has access to 8 GB of system memory. You can use this pool to run general parallel computations.
poolSize = 16; pool = parpool("myCluster",poolSize);
Starting parallel pool (parpool) using the 'myCluster' profile ... Connected to parallel pool with 16 workers.
To perform some data intensive work without creating a new pool, you can increase the amount of memory available to each worker using these steps.
Determine the number of unique hosts in the pool and the number of workers running on each host and summarize the results in a table. The table indicates the parallel pool has two unique hosts and eight workers per host.
allWkrs = pool.Workers; hostnames = {allWkrs.Host}'; [hostnames,ia,ic] = unique(hostnames); numWorkers = accumarray(ic,1); workersPerHost = table(hostnames,numWorkers)
workersPerHost=2×2 table hostnames numWorkers _________________________ __________
"phvjeq9c-01.company.com" 8
"phvjeq9c-02.company.com" 8 Use the information in the table to plan how to partition the pool. For example, to increase the memory available to each worker to 16 GB, you require a pool with four workers from each host instead of eight. Use the partition function to create a pool partition with four workers per host. Display the size of the new highMemPool partition.
highMemPool = partition(pool,"MaxNumWorkersPerHost",4); highMemPoolSize = highMemPool.NumWorkers
Calculate the memory available to the workers in the pool partition. Each worker in the highMemPool partition now has access to 16 GB of memory.
memoryPerWorker = 8; % In GB totalMemory = memoryPerWorker*poolSize; newMemoryPerWorker = totalMemory/highMemPoolSize
Define the size of the largest array you can run on each worker, which corresponds to 45% of the memory available to each worker in the pool partition.
maxMemUsagePerWorker = 0.45newMemoryPerWorker1024^3; % In bytes.
maxMatSize = round(sqrt(maxMemUsagePerWorker*highMemPoolSize/memoryPerWorker));
fprintf("The highMemPool pool can support" + ...
" a matrix size of up to %d-by-%d\n",maxMatSize,maxMatSize)
The highMemPool pool can support a matrix size of up to 87926-by-87926
You can now run computations with arrays of up to 87926-by-87926 on the workers of the highMemPool partition.
For example, to run data intensive computations using distributed arrays on the pool partition, specify the highMemPool pool object to the spmd function.
spmd(highMemPool) A = rand(maxMatSize,"codistributed"); b = rand(maxMatSize,1,"codistributed"); x = A\b; end
Run Multithreaded Code on Workers
This example shows how to partition and setup workers of an existing interactive parallel pool for multithreaded computations.
Some MATLAB functions by default make use of multithreading on machines with many cores, increasing computational efficiency. Computations that use these functions perform better when multiple threads are available than on a single thread. Parallel pool workers use a single computational thread by default, as they typically associate with a single core. If the MATLAB functions in your code benefit from implicit multithreading, you can partition a pool with fewer workers per host and increase the number of computational threads on the workers to leverage the built-in parallelism. Although this process results in a pool with fewer workers, each worker can perform multithreaded computations which can increase computation efficiency.
Start a parallel pool of 16 workers using the remote cluster profile myCluster.
poolSize = 16; pool = parpool("myCluster",poolSize);
Starting parallel pool (parpool) using the 'myCluster' profile ... Connected to parallel pool with 16 workers.
If you need this same pool to perform multithreaded computations, you can increase the maximum number of computational threads on each worker by following these steps.
Determine the number of unique hosts in the pool and the number of workers running on each host, and summarize the results in a table. Use the information in the table to plan how to partition the pool.
allWkrs = pool.Workers; hostnames = {allWkrs.Host}'; [uniqueHosts,~,hostIndices] = unique(hostnames); numWorkers = accumarray(hostIndices,1); hostWorkers = table(uniqueHosts,numWorkers)
hostWorkers=4×2 table uniqueHosts numWorkers ____________________________ __________
{'phvj9c-00-cm.company.com'} 4
{'phvj9c-01-cm.company.com'} 4
{'phvj9c-02-cm.company.com'} 4
{'phvj9c-03-cm.company.com'} 4 The number of threads across all the workers in the new pool partition must not exceed the maximum number of workers in the original pool, otherwise you might observe reduced performance.
The table indicates that, for this parallel pool, all hosts have the same number of workers. You can apply a simple logic by dividing the number of workers on each host by the desired threads per worker to find the minimum number of workers per host needed to achieve the required number of threads per worker.
Determine the minimum number of workers for the partition pool that results in four threads per worker.
threadsPerWorker = 4; workersPerHost = ceil(min(hostWorkers.numWorkers/threadsPerWorker))
Partition a pool with the calculated number of workers per host.
multiThreadsPool = partition(pool,"MaxNumWorkersPerHost",workersPerHost);
In cases where workers are unevenly distributed across hosts, you must implement additional logic to select a specific number of workers from each host using the Workers argument of the partition function. For an example of a more robust partitioning logic to handle uneven distributions across hosts, see the unevenHostPartitioning supporting file attached to this example.
To setup the workers for multithreaded computations, increase the maximum number of computational threads for all workers in the pool partition. Use the parfevalOnAll function to execute the maxNumCompThreads function with the specified number of threads per worker across all workers in the pool partition. Retain a copy of the previous maximum number of computational threads on the workers.
setNumCompThreads = parfevalOnAll(multiThreadsPool, ... @maxNumCompThreads,1,threadsPerWorker); lastThreads = fetchOutputs(setNumCompThreads);
You can now run multithreaded computations on the workers of the multiThreadsPool partition. For example, to run parfor computations on the pool partition, pass the multiThreadsPool pool object as the second input argument to parfor.
N = randn(5000); numIterations = 10; parfor (idx = 1:numIterations,multiThreadsPool) out = N*N; end
When you have completed your multithreaded computations, reset the maximum number of computational threads for all workers in the pool partition. Use the parfevalOnAll function to execute the maxNumCompThreads function with the previous maximum number of computational threads on all workers in the pool partition. Wait for the future to complete and check for errors from the workers using the fetchOutputs function.
setNumCompThreads = parfevalOnAll(multiThreadsPool,@maxNumCompThreads,0,lastThreads(1)); fetchOutputs(setNumCompThreads)
Target Specific Workers in Pool
When you want to repeatedly execute commands on the same worker, you can partition a pool with one worker. This approach is useful for tasks that require workers to maintain their state between computations or use unique resources. Unlike blocking the worker with a long running parfeval computation, partitioning a single worker pool helps you keep track of the specific worker, and also allows you to use the worker for other parallel work when needed.
Keep Data on Worker
This example shows how to partition a worker from an existing interactive parallel pool, to keep and access a large dataset in the memory of the worker. Use this approach to minimize data transfer between the client and pool workers.
In this example, you create a large voxel image volume on an interactive pool of 10 cluster workers. Each worker stores 500-by-500-by-500 matrix in memory. If you do not have access to cluster workers or if your machine does not have enough memory to create and store the 3 GB volume, decrease the imSize variable before running this example.
Start a parallel pool of 10 workers using the myCluster remote cluster profile.
pool = parpool("myCluster",10);
Starting parallel pool (parpool) using the 'myCluster' profile ... Connected to parallel pool with 10 workers.
In a spmd statement, create a simulated voxel image of bubbles using the workers of the parallel pool. Display a subset of the image.
spmd V = rand(imSize,"single"); BW = false(size(V)); BW(V < 0.000001) = true; V = bwdist(BW); V(V <= 20) = 1; V(V > 20) = 0; end volshow(V{1})

Concatenate the resulting voxel image on the worker whose spmdIndex is 1.
spmd V = spmdCat(V,3,1); end
Now, partition a pool with the worker that stores the voxel image in memory, specifically the worker whose spmdIndex is 1.
Use the getCurrentWorker function in an spmd statement to identify the workers in the pool. The getCurrentWorker function returns a Composite with a parallel.pool.Worker object for each worker in the pool.
spmd wkrs = getCurrentWorker; end
Partition a pool using the parallel.pool.Worker object for the worker whose spmdIndex is 1.
dataWkrPool = partition(pool,"Workers",wkrs{1});
To access the voxel image in a parfor-loop or parfeval computation, create a Constant object with the Composite object of the voxel image, V.
V = parallel.pool.Constant(V);
You can now access the data on the worker in a parfor-loop or parfeval computation.
For example, use parfeval to perform some image processing on the dataWkrPool single worker pool partition using Image Processing Toolbox™ functions. Define a function to count the number of bubbles and volume of each bubble in the voxel image. Specify the dataWkrPool pool partition and the voxel image Constant objects to the parfeval function. Retrieve the results.
function [numBubbles,bubbleVolumes] = myBubbleFunction(V) labeledV = bwlabeln(V.Value); numBubbles = max(labeledV(:)); % Calculate the volume of each bubble stats = regionprops3(labeledV,"Volume"); bubbleVolumes = stats.Volume'; end
f = parfeval(dataWkrPool,@myBubbleFunction,2,V); [numBubbles,bubbleVolumes] = fetchOutputs(f)
bubbleVolumes = 1×645
26709 12319 17329 24559 33401 33401 33401 33401 33401 16665 33401 33401 93972 17329 33401 33401 33401 33401 33401 33038 33401 65942 33401 33401 33401 33401 33401 63062 64938 33401 25660 24559 66584 49502 33401 33401 33401 33401 33401 33401 33401 33401 33401 33401 33401 22237 33401 33401 33401 66596Assign Worker to Specific Task
This example shows how to partition a worker from an existing parallel pool, and use the worker to maintain the same database connection to import image data from a database for processing.
When workflows require unique resources, such as database connections or connection to hardware, assigning these to specific workers ensures that you can easily and repeatedly access the resources when needed. To use any handle-type resources such as file handles, database and hardware connections on a parallel pool, it is recommended that you create the handle-type resource for each worker in the pool using a parallel.pool.Constant object. For database connections, this also means the database has to bear the overhead of maintaining multiple connections with the different workers in your pool.
If you are unable to create a database connection for each worker in your pool, you can use this approach to maintain a database connection on a specific worker that you can repeatedly access.
Start a pool of thread workers on your local machine. Thread-based pools are optimized for less data transfer, faster scheduling, and reduced memory usage, so they can result in a performance gain in applications that involve a lot of data transfer between workers.
pool = parpool("Threads");
Starting parallel pool (parpool) using the 'Threads' profile ... Connected to parallel pool with 6 workers.
Use the Workers property of the pool object to obtain the parallel.Worker objects of the workers in the pool. Partition the pool to isolate the first worker in the allWkrs array.
allWkrs = pool.Workers; dBWkrPool = partition(pool,"Workers",allWkrs(1));
Create a Constant object for the database connection using the connectToDatabase helper function. If you have Database Toolbox™, you can use the database (Database Toolbox) function to connect to a database. The connectToDatabase helper function is attached to this example as a supporting file.
cDbase = parallel.pool.Constant(@() connectToDatabase("Database"));
Define a function to create and maintain a connection to the database. To run this example, the getDbaseData function simulates creating a connection to a database and stores the connection in the Value property of the Constant object. The function also simulates importing data using the same database connection each time it runs on the worker. If you have Database Toolbox, you can use the fetch (Database Toolbox) function to import data from a database. The fetchQuery helper function is attached to this example as a supporting file.
function imgs = getDbaseData(C,query) conn = C.Value; imgs = fetchQuery(conn,query); end
Specify queries for the database. Create a Constant object for the image processing filter.
imageNames = ["outdoors" "indoors" "daytime" "nightime"]; sqlqueries = "SELECT * FROM " + imageNames; cFilter = parallel.pool.Constant(randn(16,1));
To import data, schedule the getDbaseData function to run asynchronously with parfeval on the dBWkrPool pool partition. By specifying the dBWkrPool partition to the parfeval function, the same worker always runs the getDbaseData function, using the same database connection from the Constant object to import the data.
fImport = parfeval(dBWkrPool,@getDbaseData,1,cDbase,sqlqueries(1));
In a loop, import the data using parfeval and process the imported data in a parfor-loop. To minimize the time the workers wait to receive data, stagger the data import and processing computations.
for j = 1:length(sqlqueries) % Fetch data asynchronously data = fetchOutputs(fImport); % Wait for the data to be fetched % Schedule the next parfeval computation to run in the background. if j < length(imageNames) fImport = parfeval(dBWkrPool,@getDbaseData,1,cDbase,sqlqueries(j+1)); end parfor k=1:size(data,2) % Zero-pad filter to the length of data, and transform [rows,~] = size(data); filterF = fft(cFilter.Value,rows); % Transform each column of the input data imgFft = fft2(data{k}); % Multiply each column by filter and compute inverse transform out{k} = ifft2(filterF.*imgFft) end processedImages.(imageNames(j)) = out; fprintf("'%s' images processed\n",imageNames(j)) end
'outdoors' images processed 'indoors' images processed 'daytime' images processed 'nightime' images processed
Maintain State on Workers
This example shows how to use pool partitions to ensure workers maintain their state across multiple function calls. You can partition a parallel pool into multiple single-worker pool partitions. This setup allows you to direct computations to the same worker, enabling the use of persistent variables to continue computations between function calls.
This example simulates a simple financial trading system where each worker processes market data, updates its state, and makes trading decisions based on its current state and individual risk factors.
Start by accessing the current parallel pool. If no pool is available, the gcp function creates one using the default profile. Use the Workers property of the current pool object to obtain the parallel.Worker objects of the workers in the pool.
pool = gcp; poolWkrs = pool.Workers;
Partition the pool three times to isolate the first three workers in the poolWkrs array into individual pool partitions. Store the pool partitions in an array of pool objects.
traderPools(1) = partition(pool,"Workers",poolWkrs(1)); traderPools(2) = partition(pool,"Workers",poolWkrs(2)); traderPools(3) = partition(pool,"Workers",poolWkrs(3));
Define a function for the trading system. The tradingWorker function maintains a persistent state between function calls, processes new market data, and uses averages to make trading decisions based on the current state. The decision-making incorporates a worker-specific risk factor to introduce variability between workers.
function decision = tradingWorker(marketData,riskFactor) % Initialize or update the state persistent state if isempty(state) state = struct("history",[],"position","none"); end
% Process new market data state.history = [state.history;marketData];
% Calculate short-term and long-term averages shortTermAvg = mean(marketData); longTermAvg = mean(state.history);
% Trading logic with a worker-specific risk factor randomFactor = 1 + riskFactor*randn; % Worker-specific randomness
if strcmp(state.position,"none") && (shortTermAvg > longTermAvgrandomFactor) state.position = "buy"; elseif strcmp(state.position,"buy") && (shortTermAvg < longTermAvg*randomFactor) state.position = "sell"; elseif strcmp(state.position,"sell") && (shortTermAvg >= longTermAvgrandomFactor) state.position = "none"; end
decision = state.position; pause(1) % Simulate processing time end
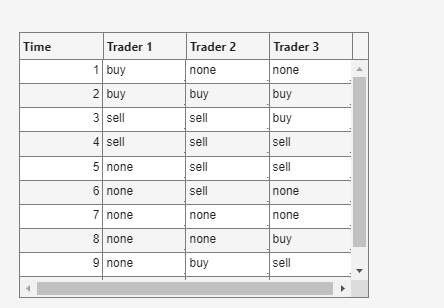
Create a user interface table to display the decision data from the workers.
fig = uifigure(Position=[619 525 443 308]); decisionTable = table(Size=[0 4], ... VariableTypes=["double","string","string","string"], ... VariableNames=["Time","Trader 1","Trader 2","Trader 3"]); uit = uitable(fig,Data=decisionTable,Position=[20 11 350 266]);
Simulate real-time market data and process it using the partitioned pools. Assign a unique risk factor that introduces variability in trading decisions to each worker. To ensure that each pool worker uses the same risk factor every time it runs the tradingWorker function and updates it's state, use the same pool partition for each risk factor. Retrieve the decisions for each time step and update the table.
riskFactors = [0.1 0.2 0.3]; for t = 1:10 % % Simulate real-time market data marketData = rand(100,1)*100; % Random price data
% Create futures to process data in parallel
futures(1) = parfeval(traderPools(1),@tradingWorker,1,marketData,riskFactors(1));
futures(2) = parfeval(traderPools(2),@tradingWorker,1,marketData,riskFactors(2));
futures(3) = parfeval(traderPools(3),@tradingWorker,1,marketData,riskFactors(3));
decisions = fetchOutputs(futures);
decisionTable(end+1,:) = {t,decisions(1),decisions(2),decisions(3)};
uit.Data = decisionTable;
drawnow limitrate nocallbacksend
Clear the persistent state in the worker function. When you clear the function with the persistent variable from the client, MATLAB® also clears the function on all the workers.
Partition Multiple Pools for Different Workflows
In certain applications where you need to manage multiple or concurrent workflows, creating multiple pool partitions can help you balance the resource use of the different workflows. This approach is particularly useful for parallel workflows that run independent of each other.
Run Multiple Workflows Simultaneously
If you have multiple workflows with different resource requirements that need to run concurrently, partitioning the pool into multiple pool partitions allows each workflow to operate independently without interfering with each other. For an example that uses multiple pool partitions to manage resources in a data processing pipeline, see Partition Pools for Efficient Resource Management in Concurrent Parallel Workflows.
Scale Pool to Fit Workflow
This example shows to use pool partitions to manage resources efficiently when transitioning between different workflows without restarting the pool.
In this example, you run a parfor-loop that utilizes all available workers in the pool. After completing this process, you want to run a memory-intensive task that can only use half of the available cores to avoid memory issues. Pool partitions allow you to manage this transition seamlessly without restarting the existing pool.
Start a parallel pool with 10 workers using the default cluster profile. Use a parfor-loop to generate audio samples of 30 second duration at a sample rate of 44.kHz. The frequency in the audio signal changes to a random value every 3 seconds. The generateAudio function is attached to this example as a supporting file.
Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 10 workers.
fs = 44100; frequencyDuration = 3; audioDuration = 30; numAudio = 50; audioSamples = cell(1,numAudio); parfor idx = 1:numAudio audioSamples{idx} = generateAudio(audioDuration,frequencyDuration,fs); end
Next, extract the Short Time Fourier Transform (STFT) of the audio samples in the background. STFT computations involve performing multiple FFT computations, which can be memory intensive on the workers. To reduce the number of parfeval computation running at the same time, create a pool partition with a smaller number of workers to run the parfeval computations.
poolWkrs = pool.Workers; smallPool = partition(pool,"Workers",poolWkrs(1:2:end));
Submit the extractFeatures parfeval computations to the pool partition by specifying the smallPool pool object to the parfeval function.
futures(1:numAudio) = parallel.FevalFuture; for a = 1:numAudio futures(a) = parfeval(smallPool,@extractFeatures,1,audioSamples{a},fs); end
You can continue to run computations on the client or the workers that are not in the smallPool partition. For this example, collect the results from the parfeval computations when they are ready using the fetchOutputs function. The fetchOutputs function waits until the futures finishes.
sftfData = fetchOutputs(futures);
Local Functions
The extractFeatures function processes the input audio signal audio sampled at frequency fs, and returns a structure containing the Short-Time Fourier Transform (STFT) features of the original and reverberated audio. The addReverb and getSTFT helper functions are attached to this example as a supporting file.
function output = extractFeatures(audio,fs) reverbAud = addReverb(audio,fs); [audT,audF,audStftX] = getSTFT(audio,fs); [reverbT,reverbF,reverbStftX] = getSTFT(reverbAud,fs); output = struct("audT",audT,"audF",audF,"audStftX",audStftX, ... "reverbT",reverbT,"reverbF",reverbF,"reverbStftX",reverbStftX); end