ClassificationPartitionedLinear - Cross-validated linear model for binary classification of high-dimensional
data - MATLAB ([original](http://www.mathworks.com/help/stats/classreg.learning.partition.classificationpartitionedlinear.html)) ([raw](?raw))Cross-validated linear model for binary classification of high-dimensional data
Description
ClassificationPartitionedLinear is a set of linear classification models trained on cross-validated folds. You can estimate the quality of classification, or how well the linear classification model generalizes, using one or more kfold functions: kfoldPredict, kfoldLoss, kfoldMargin, and kfoldEdge.
Every kfold object function uses models trained on training-fold (in-fold) observations to predict the response for validation-fold (out-of-fold) observations. For example, suppose that you cross-validate using five folds. The software randomly assigns each observation into five groups of equal size (roughly). The training fold contains four of the groups (roughly 4/5 of the data), and the validation fold contains the other group (roughly 1/5 of the data). In this case, cross-validation proceeds as follows:
- The software trains the first model (stored in
CVMdl.Trained{1}) by using the observations in the last four groups, and reserves the observations in the first group for validation. - The software trains the second model (stored in
CVMdl.Trained{2}) by using the observations in the first group and the last three groups. The software reserves the observations in the second group for validation. - The software proceeds in a similar manner for the third, fourth, and fifth models.
If you validate by using kfoldPredict, the software computes predictions for the observations in group i by using model_i_. In short, the software estimates a response for every observation by using the model trained without that observation.
Note
ClassificationPartitionedLinear model objects do not store the predictor data set.
Creation
You can create a ClassificationPartitionedLinear object by using thefitclinear function and specifying one of the name-value arguments CrossVal,CVPartition, Holdout,KFold, or Leaveout.
Properties
Cross-Validation Properties
Number of cross-validated folds, specified as a positive integer.
Data Types: double
Number of observations in the training data, specified as a positive numeric scalar.
Data Types: double
Data partition indicating how the software splits the data into cross-validation folds, specified as a cvpartition model.
Linear classification models trained on cross-validation folds, specified as a cell array of ClassificationLinear models.Trained has k cells, where_k_ is the number of folds.
Data Types: cell
Observation weights used to cross-validate the model, specified as a numeric vector. W hasNumObservations elements.
The software normalizes W so that the weights for observations within a particular class sum up to the prior probability of that class.
Data Types: single | double
Observed class labels used to cross-validate the model, specified as a categorical or character array, logical or numeric vector, or cell array of character vectors. Y hasNumObservations elements, and is the same data type as the input argument Y that you passed tofitclinear to cross-validate the model. (The software treats string arrays as cell arrays of character vectors.)
Each row of Y represents the observed classification of the corresponding observation in the predictor data.
Data Types: categorical | char | logical | single | double | cell
Other Classification Properties
Categorical predictor indices, specified as a vector of positive integers. CategoricalPredictors contains index values indicating that the corresponding predictors are categorical. The index values are between 1 and p, where p is the number of predictors used to train the model. If none of the predictors are categorical, then this property is empty ([]).
Data Types: single | double
This property is read-only.
Unique class labels used in training, specified as a categorical or character array, logical or numeric vector, or cell array of character vectors. ClassNames has the same data type as the class labels Y.(The software treats string arrays as cell arrays of character vectors.) ClassNames also determines the class order.
Data Types: categorical | char | logical | single | double | cell
This property is read-only.
Data Types: double
Predictor names in order of their appearance in the predictor data, specified as a cell array of character vectors. The length of PredictorNames is equal to the number of variables in the training data X orTbl used as predictor variables.
Data Types: cell
This property is read-only.
Prior class probabilities, specified as a numeric vector.Prior has as many elements as classes in ClassNames, and the order of the elements corresponds to the elements ofClassNames.
Data Types: double
Response variable name, specified as a character vector.
Data Types: char
Data Types: char | function_handle
Object Functions
| kfoldEdge | Classification edge for cross-validated linear classification model |
|---|---|
| kfoldLoss | Classification loss for cross-validated linear classification model |
| kfoldMargin | Classification margins for cross-validated linear classification model |
| kfoldPredict | Classify observations in cross-validated linear classification model |
Examples
Load the NLP data set.
X is a sparse matrix of predictor data, and Y is a categorical vector of class labels. There are more than two classes in the data.
Identify the labels that correspond to the Statistics and Machine Learning Toolbox™ documentation web pages.
Cross-validate a binary, linear classification model that can identify whether the word counts in a documentation web page are from the Statistics and Machine Learning Toolbox™ documentation.
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'CrossVal','on')
CVMdl = ClassificationPartitionedLinear CrossValidatedModel: 'Linear' ResponseName: 'Y' NumObservations: 31572 KFold: 10 Partition: [1×1 cvpartition] ClassNames: [0 1] ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedLinear cross-validated model. Because fitclinear implements 10-fold cross-validation by default, CVMdl.Trained contains ten ClassificationLinear models that contain the results of training linear classification models for each of the folds.
Estimate labels for out-of-fold observations and estimate the generalization error by passing CVMdl to kfoldPredict and kfoldLoss, respectively.
oofLabels = kfoldPredict(CVMdl); ge = kfoldLoss(CVMdl)
The estimated generalization error is less than 0.1% misclassified observations.
To determine a good lasso-penalty strength for a linear classification model that uses a logistic regression learner, implement 5-fold cross-validation.
Load the NLP data set.
X is a sparse matrix of predictor data, and Y is a categorical vector of class labels. There are more than two classes in the data.
The models should identify whether the word counts in a web page are from the Statistics and Machine Learning Toolbox™ documentation. So, identify the labels that correspond to the Statistics and Machine Learning Toolbox™ documentation web pages.
Create a set of 11 logarithmically-spaced regularization strengths from 10-6 through 10-0.5.
Lambda = logspace(-6,-0.5,11);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns. Estimate the coefficients using SpaRSA. Lower the tolerance on the gradient of the objective function to 1e-8.
X = X'; rng(10); % For reproducibility CVMdl = fitclinear(X,Ystats,'ObservationsIn','columns','KFold',5,... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8)
CVMdl = ClassificationPartitionedLinear CrossValidatedModel: 'Linear' ResponseName: 'Y' NumObservations: 31572 KFold: 5 Partition: [1×1 cvpartition] ClassNames: [0 1] ScoreTransform: 'none'
Properties, Methods
numCLModels = numel(CVMdl.Trained)
CVMdl is a ClassificationPartitionedLinear model. Because fitclinear implements 5-fold cross-validation, CVMdl contains 5 ClassificationLinear models that the software trains on each fold.
Display the first trained linear classification model.
Mdl1 = ClassificationLinear ResponseName: 'Y' ClassNames: [0 1] ScoreTransform: 'logit' Beta: [34023×11 double] Bias: [-13.2936 -13.2936 -13.2936 -13.2936 -13.2936 -6.8954 -5.4359 -4.7170 -3.4108 -3.1566 -2.9792] Lambda: [1.0000e-06 3.5481e-06 1.2589e-05 4.4668e-05 1.5849e-04 5.6234e-04 0.0020 0.0071 0.0251 0.0891 0.3162] Learner: 'logistic'
Properties, Methods
Mdl1 is a ClassificationLinear model object. fitclinear constructed Mdl1 by training on the first four folds. Because Lambda is a sequence of regularization strengths, you can think of Mdl1 as 11 models, one for each regularization strength in Lambda.
Estimate the cross-validated classification error.
Because there are 11 regularization strengths, ce is a 1-by-11 vector of classification error rates.
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a classifier. For each regularization strength, train a linear classification model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated, classification error rates and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(ce),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} classification error') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') title('Test-Sample Statistics') hold off
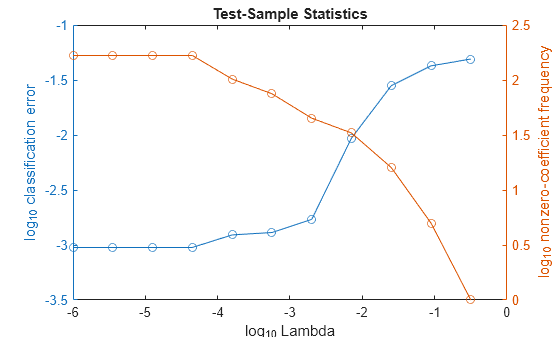
Choose the index of the regularization strength that balances predictor variable sparsity and low classification error. In this case, a value between 10-4 to 10-1 should suffice.
Select the model from Mdl with the chosen regularization strength.
MdlFinal = selectModels(Mdl,idxFinal);
MdlFinal is a ClassificationLinear model containing one regularization strength. To estimate labels for new observations, pass MdlFinal and the new data to predict.
Extended Capabilities
The object functions of a ClassificationPartitionedLinear model fully support GPU arrays.
Version History
Introduced in R2016a
You can fit a ClassificationPartitionedLinear object with GPU arrays by usingfitclinear.ClassificationPartitionedLinear object functions now support GPU array input arguments so that they can execute on a GPU.
Starting in R2022a, the Cost property stores the user-specified cost matrix, so that you can compute the observed misclassification cost using the specified cost value. The software stores normalized prior probabilities (Prior) and observation weights (W) that do not reflect the penalties described in the cost matrix. To compute the observed misclassification cost, specify theLossFun name-value argument as "classifcost" when you call the kfoldLoss function.
Note that model training has not changed and, therefore, the decision boundaries between classes have not changed.
For training, the fitting function updates the specified prior probabilities by incorporating the penalties described in the specified cost matrix, and then normalizes the prior probabilities and observation weights. This behavior has not changed. In previous releases, the software stored the default cost matrix in the Cost property and stored the prior probabilities and observation weights used for training in thePrior and W properties, respectively. Starting in R2022a, the software stores the user-specified cost matrix without modification, and stores normalized prior probabilities and observation weights that do not reflect the cost penalties. For more details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.
Some object functions use the Cost and W properties:
- The
kfoldLossfunction uses the cost matrix stored in theCostproperty if you specify theLossFunname-value argument as"classifcost"or"mincost". - The
kfoldLossandkfoldEdgefunctions use the observation weights stored in theWproperty.
If you specify a nondefault cost matrix when you train a classification model, the object functions return a different value compared to previous releases.
If you want the software to handle the cost matrix, prior probabilities, and observation weights in the same way as in previous releases, adjust the prior probabilities and observation weights for the nondefault cost matrix, as described in Adjust Prior Probabilities and Observation Weights for Misclassification Cost Matrix. Then, when you train a classification model, specify the adjusted prior probabilities and observation weights by using the Prior and Weights name-value arguments, respectively, and use the default cost matrix.