Assembly Language (original) (raw)

music
|  | | OSdata.com |
| ------------------------------------------------------------------------------------------ | | ---------- |
| | OSdata.com |
| ------------------------------------------------------------------------------------------ | | ---------- |
This web page examines assembly languages in a general manner. Specific examples of addressing modes and instructions from various processors are used to illustrate the general nature of assembly language.
This summary is now explained in more patient detail in a series of web pages starting at Introduction to Assembly Language.
OSdata.com is used in more than 300 colleges and universities around the world
Find out how to get similar high web traffic and search engine placement.
NOTE: If you have a slow connection, you may want to allow the entire web page to load before attempting to use any of the following in-page links:
- general
- kinds of processors
- data representation
- address space
- register set
- address modes
- executable instructions
- data movement
- address movement
- integer arithmetic
- floating arithmetic
- binary coded decimal
- advanced math
- data conversion
- logical
- shift and rotate
- bit manipulation
- bit field
- table operations
- high level language support
- program control
- condition codes
- input/output
- system control
- coprocessor and multiprocessor
- trap generating
- further reading: books on assembly language
- related software
- further reading: websites
general
Unlike the other programming languages catalogued here, assembly language is not a single language, but rather a group of languages. Each processor family (and sometimes individual processors within a processor family) has its own assembly language.
In contrast to high level languages, data structures and program structures in assembly language are created by directly implementing them on the underlying hardware. So, instead of catalogueing the data structures and program structures that can be built (in assembly language you can build any structures you so desire, including new structures nobody else has ever created), we will compare and contrast the hardware capabilities of various processor families.
This web page does not attempt to teach how to program in assembly language. Because of the close relationship between assembly languages and the underlying hardware, this web page will discuss hardware implementation as well as software.
If you aren’t fairly familiar with how computers work, you should probably first read basics of computer hardware or this page won’t make any sense at all.
history
history: The oldest non-machine language, allowing for a more human readable method of writing programs than writing in binary bit patterns (or even hexadecimal patterns).
comparison of assembly and high level languages
Assembly languages are close to a one to one correspondence between symbolic instructions and executable machine codes. Assembly languages also include directives to the assembler, directives to the linker, directives for organizing data space, and macros. Macros can be used to combine several assembly language instructions into a high level language-like construct (as well as other purposes). There are cases where a symbolic instruction is translated into more than one machine instruction. But in general, symbolic assembly language instructions correspond to individual executable machine instructions.
High level languages are abstract. Typically a single high level instruction is translated into several (sometimes dozens or in rare cases even hundreds) executable machine language instructions. Some early high level languages had a close correspondence between high level instructions and machine language instructions. For example, most of the early COBOL instructions translated into a very obvious and small set of machine instructions. The trend over time has been for high level languages to increease in abstraction. Modern object oriented programming languages are highly abstract (although, interestingly, some key object oriented programming constructs do translate into a very compact set of machine instructions).
Assembly language is much harder to program than high level languages. The programmer must pay attention to far more detail and must have an intimate knowledge of the processor in use. But high quality hand crafted assembly language programs can run much faster and use much less memory and other resources than a similar program written in a high level language. Speed increases of two to 20 times faster are fairly common, and increases of hundreds of times faster are occassionally possible. Assembly language programming also gives direct access to key machine features essential for implementing certain kinds of low level routines, such as an operating system kernel or microkernel, device drivers, and machine control.
High level programming languages are much easier for less skilled programmers to work in and for semi-technical managers to supervise. And high level languages allow faster development times than work in assembly language, even with highly skilled programmers. Development time increases of 10 to 100 times faster are fairly common. Programs written in high level languages (especially object oriented programming languages) are much easier and less expensive to maintain than similar programs written in assembly language (and for a successful software project, the vast majority of the work and expense is in maintenance, not initial development).
For information on how to interface high level languages and assembly languages, see[assembly/high level language interface](./asm/highlvl.htm #highlevelinterface)
availability
availability: Assemblers are available for just about every processor ever made. Native assemblers produce object code on the same hardware that the object code will run on. Cross assemblers produce object code on different hardware that the object code will run on.
structure
format: free form or column (depends on the assembly langauge)
nature: procedural language with one to one correspondence between language mnemonics and executable machine instructions.
“Assembler languages occupy a unique place in the computing world. Since most assmebler-language statements are symbolic of individual machine-language instructions, the assembler-language programmer has the full power of the computer at his disposal in a way that users of other languages do not. Because of the direct relationship between assembler language and machine language, assembler language is used when high efficiency of programs is needed, and especially in areas of application that are so new and amorphous that existing program-oriented languages are ill-suited for describing the procedures to be followed.” —Assembler Language Programming by George W. Struble, page viib1
“Perhaps the most glaring difference among the three types of languages [high level, assembly, and machine] is that as we move from high-level languages to lower levels, the code gets harder to read (with understanding). The major advantages of high-level languages are that they are easy to read and are machine independent. The instructions are written in a combination of English and ordinary mathematical notation, and programs can be run with minor, if any, changes on different computers.” —VAX-11 Assembly Language Programming by Sara Baase, page 1b2
“The second most visible difference among the different types of languages is that several lines of assembly language are needed to encode one line of a high-level language program.” —VAX-11 Assembly Language Programming by Sara Baase, page 2b2
“There are a number of situations in which it is very desirable to use assembler language routines to do part of a job, and use some higher-level language for other parts. It makes sense to use higher-level languages such as Fortran, COBOL, or PL/I for parts of procedures for which they are well-suited, and supplement with assembler language routines for those parts of procedures for which the higher-level language is awkward or inefficient.” —Assembler Language Programming by George W. Struble, page 427b1
“If one has a choice between assembly language and a high-level language, why choose assembly language? The fact that the amount of programming done in assembly language is quite small compared to the amount done in high-level languages indicates that one generally doesn’t choose assembly language. However, there are situations where it may not be convenient, efficient, or possible to write programs in hihg-level languages. … Programs to control and communicate with peripheral devices (input and output devices) are usually written in assembly language because they use special instructions that are not available in high-level languages, and they must be very efficient. Some systems programs are written in assembly language for similar reasons. In general, since high-level languages are designed without the features of a particular machine in mind and a compiler must do its job in a standardized way to accomodate all valid programs, there are situations where to take advantage of special features of a machine, to program some details that are inaccessible from a high-level language, or perhaps to increase the efficiency of a program, one may reasonably choose to write in assembly language.” —VAX-11 Assembly Language Programming by Sara Baase, page 3-4b2
“In situations where programming in a high-level language is not appropriate, it is clear that assembly language is to be preferred to machine language. Assembly language has a number of advantages over machine code aside from the obvious increase in readability. One is that the use of symbolic names for data and instruction labels frees the programmer from computing and recomputing the memory locations whenever a change is made in a program. Another is that assembly languages generally have a feature, called macros, that frees the [programmer] from having to repeat similar sections of code used in several places in a program. Assemblers fo many bookkeeping and other tasks for the user. Often compilers translate into assembly language rather than machine code.” —VAX-11 Assembly Language Programming by Sara Baase, page 3b2
kinds of processors
Processors can broadly be divided into the categories of: CISC, RISC, hybrid, and special purpose.
Complex Instruction Set Computers (CISC) have a large instruction set, with hardware support for a wide variety of operations. In scientific, engineering, and mathematical operations with hand coded assembly language (and some business applications with hand coded assembly language), CISC processors usually perform the most work in the shortest time.
Reduced Instruction Set Computers (RISC) have a small, compact instruction set. In most business applications and in programs created by compilers from high level language source, RISC processors usually perform the most work in the shortest time.
Hybrid processors are some combination of CISC and RISC approaches, attempting to balance the advantages of each approach.
Special purpose processors are optimized to perform specific functions. Digital signal processors and various kinds of co-processors are the most common kinds of special purpose processors.
Hypothetical processors are processors that don’t exist yet (and may never exist). Sometimes these are processors in the design phase. Sometimes these are processors used for theoretical work. The most famous hypothetical processor is MIX (or 1009), a hypothetical teaching processor created by Donald E. Knuth for presenting computer algorithms in his famous series “The Art of Computer Programming” (discussed in the Basic Concepts section of Volume I, Fundamental Algorithms).
data representation
Most data structures are abstract structures and are implemented by the programmer with a series of assembly language instructions. Many cardinal data types (bits, bit strings, bit slices, binary integers, binary floating point numbers, binary encoded decimals, binary addresses, characters, etc.) are implemented directly in hardware for at least parts of the instruction set. Some processors also implement some data structures in hardware for some instructions — for example, most processors have a few instructions for directly manipulating character strings.
An assembly language programmer has to know how the hardware implements these cardinal data types. Some examples: Two basic issues are bit ordering (big endian or little endian) and number of bits (or bytes). The assembly language programmer must also pay attention to word length and optimum (or required) addressing boundaries. Composite data types will also include details of hardware implementation, such as how many bits of mantissa, characteristic, and sign, as well as their order. In many cases there are machine specific encodings for some data types, as well as choice of character codes (such as ASCII or EBCDIC) for character and string implementations.
data size
The basic building block is the bit, which can contain a single piece of binary data (true/false, zero/one, north/south, positive/negative, high/low, etc.).
Bits are organized into larger groupings to store values encoded in binary bits. The most basic grouping is the byte. A byte is the smallest normally addressable quantum of main memory (which can be different than the minimum amount of memory fetched at one time). In modern computers this is almost always an eight bit byte, so much so that many skilled programmers believe that a byte is defined as being always eight bits. In the past there have been computers with seven, eight, twelve, and sixteen bits. There have also been bit slice computers where the common memory addressing approach is by single bit; in these kinds of computers the term byte actually has no meaning, although eight bits on these computers are likely to be called a byte. Throughout the rest of this discussion, assume the standard eight bit byte applies unless specifically stated otherwise.
A nibble is half a byte, or four bits.
A word is the default data size for a processor. The default size does not apply in all cases. The word size is chosen by the processor’s designer(s) and reflects some basic hardware issues (such as internal or external buses). The most common word sizes are 16 and 32, but words have ranged from 16 to 60 bits. Typically there will be additional data sizes that are defined relative to the size of a word: halfword, half the size of a word; longword, usually double the size of a word; doubleword, usually double the size of a word (sometimes double the size of a longword); and quadword, four times the size of a word. Whether or not there is a space between the size designation and “word” is designated by the manufacturer, and varies by processor.
Some processors require that data be aligned. That is, two byte quantities must start on byte addresses that are multiples of two; four byte quantities must start on byte addresses that are multiples of four; etc. The general rule follows a progression of exponents of two (2, 4, 8, 16, ƒ). Some processors allow data to be unaligned, but this usually results in a slow down in performance.
- DEC VAX 16 bit [2 byte] word; 32 bit [4 byte] longword; 64 bit [8 byte]quadword; 132 bit [16 byte] octaword; data may be unaligned at a speed penalty
- IBM 360/370 32 bit [4 byte] word or full word (which is the smallest amount of data that can be fetched, with words being addresses by the highest order byte); 16 bit [2 byte] half-word; 64 bit [8 byte] double word; all data must be aligned on full word boundaries
- Intel 80x86 16 bit [2 byte] word; 32 bit [4 byte] doubleword; data may be unaligned at a speed penalty
- MIX byte of unspecified size, must work for both binary and decimal operations without programmer knowledge of size of byte, must be able to contain the values 0 to 63, inclusive, and must not hold more than 100 distinct values, six bits on a binary implementation, two digits on a decimal implementation; word is one sign and five bytes
- Motorola 680x0 8 bit byte; 16 bit [2 byte] word; 32 bit [4 byte] long or long word; 64 bit [8 byte] quad word; data may be unaligned at a speed penalty, instructions must be on word boundaries
- Motorola 68300 8 bit byte; 16 bit [2 byte] word; 32 bit [4 byte] long or long word; 64 bit [8 byte] quad word; data may be unaligned at a speed penalty, instructions must be on word boundaries
endian
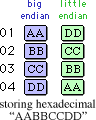
Endian is the ordering of bytes in multibyte scalar data. The term comes from Jonathan Swift’s Gulliver’s Travels. For a given multibyte scalar value, big- and little-endian formats are byte-reversed mappings of each other. While processors handle endian issues invisibly when making multibyte memory accesses, knowledge of endian is vital when directly manipulating individual bytes of multibyte scalar data and when moving data across hardware platforms.
Big endian stores scalars in their “natural order”, with most significant byte in the lowest numeric byte address. Examples of big endian processors are the IBM System 360 and 370, Motorola 680x0, Motorola 68300, and most RISC processors.
Little endian stores scalars with the least significant byte in the lowest numeric byte address. Examples of little endian processors are the Digital VAX and Intel x86 (including Pentium).
Bi-endian processors can run in either big endian or little endian mode under software control. An example is the Motorola/IBM PowerPC, which has two separate bits in the Machine State Register (MSR) for controlling endian: the ILE bit controls endian during interrupts and the LE bit controls endian for all other processes. Big endian is the default for the PowerPC.
number systems
Binary is a number system using only ones and zeros (or two states).
Decimal is a number system based on ten digits (including zero).
Hexadecimal is a number system based on sixteen digits (including zero).
Octal is a number system based on eight digits (including zero).
Duodecimal is a number system based on twelve digits (including zero).
| binary | octal | decimal | duodecimal | hexadecimal |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 |
| 10 | 2 | 2 | 2 | 2 |
| 11 | 3 | 3 | 3 | 3 |
| 100 | 4 | 4 | 4 | 4 |
| 101 | 5 | 5 | 5 | 5 |
| 110 | 6 | 6 | 6 | 6 |
| 111 | 7 | 7 | 7 | 7 |
| 1000 | 10 | 8 | 8 | 8 |
| 1001 | 11 | 9 | 9 | 9 |
| 1010 | 12 | 10 | A | A |
| 1011 | 13 | 11 | B | B |
| 1100 | 14 | 12 | 10 | C |
| 1101 | 15 | 13 | 11 | D |
| 1110 | 16 | 14 | 12 | E |
| 1111 | 17 | 15 | 13 | F |
| 10000 | 20 | 16 | 14 | 10 |
| 10001 | 21 | 17 | 15 | 11 |
| 10010 | 22 | 18 | 16 | 12 |
| 10011 | 23 | 19 | 17 | 13 |
| 10100 | 24 | 20 | 18 | 14 |
| 10101 | 25 | 21 | 19 | 15 |
| 10110 | 26 | 22 | 1A | 16 |
| 10111 | 27 | 23 | 1B | 17 |
| 11000 | 30 | 24 | 20 | 18 |
number representations
integer representations
Sign-magnitude is the simplest method for representing signed binary numbers. One bit (by universal convention, the highest order or leftmost bit) is the sign bit, indicating positive or negative, and the remaining bits are the absolute value of the binary integer. Sign-magnitude is simple for representing binary numbers, but has the drawbacks of two different zeros and much more complicates (and therefore, slower) hardware for performing addition, subtraction, and any binary integer operations other than complement (which only requires a sign bit change).
In one’s complement representation, positive numbers are represented in the “normal” manner (same as unsigned integers with a zero sign bit), while negative numbers are represented by complementing all of the bits of the absolute value of the number. Numbers are negated by complementing all bits. Addition of two integers is peformed by treating the numbers as unsigned integers (ignoring sign bit), with a carry out of the leftmost bit position being added to the least significant bit (technically, the carry bit is always added to the least significant bit, but when it is zero, the add has no effect). The ripple effect of adding the carry bit can almost double the time to do an addition. And there are still two zeros, a positive zero (all zero bits) and a negative zero (all one bits).
In two’s complement representation, positive numbers are represented in the “normal” manner (same as unsigned integers with a zero sign bit), while negative numbers are represented by complementing all of the bits of the absolute value of the number and adding one. Negation of a negative number in two’s complement representation is accomplished by complementing all of the bits and adding one. Addition is performed by adding the two numbers as unsigned integers and ignoring the carry. Two’s complement has the further advantage that there is only one zero (all zero bits). Two’s complement representation does result in one more negative number (all one bits) than positive numbers.
Two’s complement is used in just about every binary computer ever made. Most processors have one more negative number than positive numbers. Some processors use the “extra” neagtive number (all one bits) as a special indicator, depicting invalid results, not a number (NaN), or other special codes.
In unsigned representation, only positive numbers are represented. Instead of the high order bit being interpretted as the sign of the integer, the high order bit is part of the number. An unsigned number has one power of two greater range than a signed number (any representation) of the same number of bits.
| bit pattern | sign-mag. | one’s comp. | two’s comp | unsigned |
|---|---|---|---|---|
| 000 | 0 | 0 | 0 | 0 |
| 001 | 1 | 1 | 1 | 1 |
| 010 | 2 | 2 | 2 | 2 |
| 011 | 3 | 3 | 3 | 3 |
| 100 | -0 | -3 | -4 | 4 |
| 101 | -1 | -2 | -3 | 5 |
| 110 | -2 | -1 | -2 | 6 |
| 111 | -3 | -0 | -1 | 7 |
floating point representations
Floating point numbers are the computer equivalent of “scientific notation” or “engineering notation”. A floating point number consists of a fraction (binary or decimal) and an exponent (bianry or decimal). Both the fraction and the exponent each have a sign (positive or negative).
In the past, processors tended to have proprietary floating point formats, although with the development of an IEEE standard, most modern processors use the same format. Floating point numbers are almost always binary representations, although a few early processors had (binary coded) decimal representations. Many processors (especially early mainframes and early microprocessors) did not have any hardware support for floating point numbers. Even when commonly available, it was often in an optional processing unit (such as in the IBM 360/370 series) or coprocessor (such as in the Motorola 680x0 and pre-Pentium Intel 80x86 series).
Hardware floating point support usually consists of two sizes, called single precision (for the smaller) and double precision for the larger. Usually the double precision format had twice as many bits as the single precision format (hence, the names single and double). Double precision floating point format offers greater range and precision, while single precision floating point format offers better space compaction and faster processing.
F_floating format (single precision floating), DEC VAX, 32 bits, the first bit (high order bit in a register, first bit in memory) is the sign magnitude bit (one=negative, zero=positive or zero), followed by 15 bits of an excess 128 binary exponent, followed by a normalized 24-bit fraction with the redundant most significant fraction bit not represented. Zero is represented by all bits being zero (allowing the use of a longword CLR to set a F_floating number to zero). Exponent values of 1 through 255 indicate true binary exponents of -127 through 127. An exponent value of zero together with a sign of zero indicate a zero value. An exponent value of zero together with a sign bit of one is taken as reserved (which produces a reserved operand fault if used as an operand for a floating point instruction). The magnitude is an approximate range of .29*10-38 through 1.7*1038. The precision of an F_floating datum is approximately one part in 223, or approximately seven (7) decimal digits).
32 bit floating format (single precision floating), AT&T DSP32C, 32 bits, the first bit (high order bit in a register, first bit in memory) is the sign magnitude bit (one=negative, zero=positive or zero), followed by 23 bits of a normalized two’s complement fractional part of the mantissa, followed by an eight bit exponent. The magnitude of the mantissa is always normalized to lie between 1 and 2. The floating point value with exponent equal to zero is reserved to represent the number zero (the sign and mantissa bits must also be zero; a zero exponent with a nonzero sign and/or mantissa is called a “dirty zero” and is never generated by hardware; if a dirty zero is an operand, it is treated as a zero). The range of nonzero positive floating point numbers is N = [1 * 2-127, [2-2-23] * 2127] inclusive. The range of nonzero negative floating point numbers is N = [-[1 + 2-23] * 2-127, -2 * 2127] inclusive.
40 bit floating format (extended single precision floating), AT&T DSP32C, 40 bits, the first bit (high order bit in a register, first bit in memory) is the sign magnitude bit (one=negative, zero=positive or zero), followed by 31 bits of a normalized two’s complement fractional part of the mantissa, followed by an eight bit exponent. This is an internal format used by the floating point adder, accumulators, and certain DAU units. This format includes an additional eight guard bits to increase accuracy of intermediate results.
D_floating format (double precision floating), DEC VAX, 64 bits, the first bit (high order bit in a register, first bit in memory) is the sign magnitude bit (one=negative, zero=positive or zero), followed by 15 bits of an excess 128 binary exponent, followed by a normalized 48-bit fraction with the redundant most significant fraction bit not represented. Zero is represented by all bits being zero (allowing the use of a quadword CLR to set a D_floating number to zero). Exponent values of 1 through 255 indicate true binary exponents of -127 through 127. An exponent value of zero together with a sign of zero indicate a zero value. An exponent value of zero together with a sign bit of one is taken as reserved (which produces a reserved operand fault if used as an operand for a floating point instruction). The magnitude is an approximate range of .29*10-38 through 1.7*1038. The precision of an D_floating datum is approximately one part in 255, or approximately 16 decimal digits).
address space
Address space is the maximum amount of memory that a processor can address. Some processors use a multi-level addressing scheme, with main memory divided into segments or pages and some or all instructions mapping into the current segment(s) or page(s).
- MIX: 4000 words of storage
register set
Registers are fast memory, almost always connected to circuitry that allows various arithmetic, logical, control, and other manipulations, as well as possibly setting internal flags.
Most early computers had only one data register that could be used for arithmetic and logic instructions. Often there would be additional special purpose registers set aside either for temporary fast internal storage or assigned to logic circuits to implement certain instructions. Some early computers had one or two address registers that pointed to a memory location for memory accesses (a pair of address registers typically would act as source and destination pointers for memory operations). Computers soon had multiple data registers, address registers, and sometimes other special purpose registers. Some computers have general purpose registers that can be used for both data and address operations. Every digital computer using a von Neumann architecture has a register (called the program counter) that points to the next executable instruction. Many computers have additional control registers for implementing various control capabilities. Often some or all of the internal flags are combined into a flag or status register.
accumulators
Accumulators are registers that can be used for arithmetic, logical, shift, rotate, or other similar operations. The first computers typically only had one accumulator. Many times there were related special purpose registers that contained the source data for an accumulator. Accumulators were replaced with data registers and general purpose registers. Accumulators reappeared in the first microprocessors.
- Intel 8086/80286: one word (16 bit) accumulator; named AX (high order byte of the AX register is named AH and low order byte of the AX register is named AL)
- Intel 80386: one doubleword (32 bit) accumulator; named EAX (low order word uses the same names as the accumulator on the Intel 8086 and 80286 [AX] and low order and high order bytes of the low order words of four of the registers use the same names as the accumulator on the Intel 8086 and 80286 [AH and AL])
- MIX: one accumulator; named A-register; five bytes plus sign
data registers
Data registers are used for temporary scratch storage of data, as well as for data manipulations (arithmetic, logic, etc.). In some processors, all data registers act in the same manner, while in other processors different operations are performed are specific registers.
- MIX: one extension register; named X-register; five bytes plus sign; can be concatenated on the right hand side of the A-register (accumulator)
- Motorola 680x0, 68300: 8 longword (32 bit) data registers; named D0, D1, D2, D3, D4, D5, D6, and D7
address registers
Address registers store the addresses of specific memory locations. Often many integer and logic operations can be performed on address registers directly (to allow for computation of addresses).
Sometimes the contents of address register(s) are combined with other special purpose registers to compute the actual physical address. This allows for the hardware implementation of dynamic memory pages, virtual memory, and protected memory.
The number of bits of an address register (possibly combined with information from other registers) limits the maximum amount of addressable memory. A 16-bit address register can address 64K of physical memory. A 24-bit address register can address address 16 MB of physical memory. A 32-bit address register can address 4 GB of physical memory. A 64-bit address register can address 1.8446744 x 1019 of physical memory. Addresses are always unsigned binary numbers. See number of bits.
- MIX: one jump registers; named J-register; two bytes and sign is always positive
- Motorola 680x0, 68300: 8 longword (32 bit) address registers; named A0, A1, A2, A3, A4, A5, A6, and A7 (also called the stack pointer)
general purpose registers
General purpose registers can be used as either data or address registers.
- DEC VAX: 16 word (32 bit) general purpose registers; named R0 through R15
- IBM 360/370: 16 full word (32 bit) general purpose registers; named 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A (or 10), B (or 11), C (or 12), D (or 13), E (or 14), and F (or 15)
- Intel 8086/80286: 8 word (16 bit) general purpose registers; named AX, BX, CX, DX, BP, SP, SI, and DI (high order bytes of the AX, BX, CX, and DX registers have the names AH, BH, CH, and DH and low order bytes of the AX, BX, CX, and DX registers have the names AL, BL, CL, and DL)
- Intel 80386: 8 doubleword (32 bit) general purpose registers; named EAX, EBX, ECX, EDX, EBP, ESP, ESI, and EDI (low order words use the same names as the general purpose registers on the Intel 8086 and 80286 and low order and high order bytes of the low order words of four of the registers use the same names as the general purpose registers on the Intel 8086 and 80286)
- Motorola 88100: 32 word (32 bit) general purpose registers; named r0 through r31
constant registers
Constant registers are special read-only registers that store a constant. Attempts to write to a constant register are illegal or ignored. In some RISC processors, constant registers are used to store commonly used values (such as zero, one, or negative one) — for example, a constant register containing zero can be used in register to register data moves, providing the equivalent of a clear instruction without adding one to the instruction set. Constant registers are also often used in floating point units to provide such value as pi or e with additional hidden bits for greater accuracy in computations.
- Motorola 88100: r0 (general purpose register 0) contains the constant 32 bit integer zero
floating point registers
Floating point registers are special registers set aside for floating point math.
index registers
Index registers are used to provide more flexibility in addressing modes, allowing the programmer to create a memory address by combining the contents of an address register with the contents of an index register (with displacements, increments, decrements, and other options). In some processors, there are specific index registers (or just one index register) that can only be used only for that purpose. In some processors, any data register, address register, or general register (or some combination of the three) can be used as an index register.
- IBM 360/370: any of the 16 general purpose registers may be used as an index register
- Intel 80x86: 7 of the 8 general purpose registers may be used as an index register (the ESP is the exception)
- MIX: five index registers; named I-registers I1, I2, I3, I4, and I5; five bytes plus sign
- Motorola 680x0, 68300: any of the 8 data registers or the 8 address registers may be used as an index register
base registers
Base registers or segment registers are used to segment memory. Effective addresses are computed by adding the contents of the base or segment register to the rest of the effective address computation. In some processors, any register can serve as a base register. In some processors, there are specific base or segment registers (one or more) that can only be used for that purpose. In some processors with multiple base or segment registers, each base or segment register is used for different kinds of memory accesses (such as a segment register for data accesses and a different segment register for program accesses).
- IBM 360/370: any of the 16 general purpose registers may be used as a base register
- Intel 80x86: 6 dedicated segment registers: CS (code segment), SS (stack segment), DS (data segment), ES (extra segment, a second data segment register), FS (third data segment register), and GS (fourth data segment register)
- Motorola 680x0, 68300: any of the 8 address registers may be used as a base register
control registers
Control registers control some aspect of processor operation. The most universal control register is the program counter.
program counter
Almost every digital computer ever made uses a program counter. The program counter points to the memory location that stores the next executable instruction. Branching is implemented by making changes to the program counter. Some processor designs allow software to directly change the program counter, but usually software only indirectly changes the program counter (for example, a JUMP instruction will insert the operand into the program counter). An assembler has a location counter, which is an internal pointer to the address (first byte) of the next location in storage (for instructions, data areas, constants, etc.) while the source code is being converted into object code.
The VAX uses the 16th of 16 general purpose registers as the program counter (PC). Almost the entire instruction set can directly manipulate the program counter, allowing a very rich set of possible kinds of branching.
The program counter in System/360 and 370 machines is contained in bits 40-63 of the program status word (PSW), which is directly accessible by some instructions.
- IBM 360/370: program counter is bits 40-63 of the program status word (PSW)
- Intel 8086/80286: 16-bit instruction pointer (IP)
- Intel 80386: 32-bit instruction pointer (EIP)
- Motorola 680x0, 68300: 32-bit program counter (PC)
processor flags
Processor flags store information about specific processor functions. The processor flags are usually kept in a flag register or a general status register. This can include result flags that record the results of certain kinds of testing, information about data that is moved, certain kinds of information about the results of compations or transformations, and information about some processor states. Closely related and often stored in the same processor word or status register (although often in a privileged portion) are control flags that control processor actions or processor states or the actions of certain instructions.
- IBM 360/370: program status word (PSW)
- Intel 8086/80286: 16-bit flag register (FLAGS); system flags, control flag, and status flags)
- Intel 80386: 32-bit flag register (EFLAGS); system flags, control flag, and status flags)
- MIX: an overflow toggle and a comparison indicator
- Motorola 680x0, 68300: 16-bit status register (SR); high byte is system byte and requires privileged access, low byte is user byte or condition code register (CCR)
A few typical result flags (with processors that include them):
- auxilary carry Set if a carry out of the most significant bit of a BCD operand occurs (binary coded decimal addition). Also commonly set if a borrow occurs in a BCD subtract. Used in Intel 80x86 [AF].
- carry Set if a carry out of the most significant bit of an operand occurs (addition). Also commonly set if a borrow occurs in a subtract. Used in Digital VAX [C], Intel 80x86 [CF], Motorola 680x0 [C], Motorola 68300 [C], Motorola M68HC16 [C].
- comparison indicator contains one of three values: less, equal, or greater. Used in MIX.
- extend Set to the value of the carry bit for arithmetic operations (used to support implementation of multi-byte arithmetic larger than that implemented directly by the hardware. Used in Motorola 680x0 [X], Motorola 68300 [X].
- half carry Set if a carry out of bit 3 of an operand occurs during BCD addition. Used in Motorola M68HC16 [H].
- negative Set if the most significant bit of a result is set. Used in Digital VAX [N], Motorola 680x0 [N], Motorola 68300 [N], Motorola M68HC16 [N].
- overflow Set if arithmetic overflow occurs. Used in Digital VAX [V], Intel 80x86 [OF], Motorola 680x0 [V], Motorola 68300 [V], Motorola M68HC16 [V].
- overflow toggle a single bit that is either on or off. Used in MIX.
- parity For odd parity machines, set to make an odd number of one bits; for an even parity machine, set to make an even number of one bits. Used in Intel 80x86 [PF]. The IBM 360/370 has odd parity on memory.
- sign Set for negative sign. Used in Intel 80x86 [SF].
- trap Set for traps. Used in Intel 80x86 [TF].
- zero Set if a result equals zero. Used in Digital VAX [Z], Intel 80x86 [ZF], Motorola 680x0 [Z], Motorola 68300 [Z], Motorola M68HC16 [Z].
Some conditions are determined by combining multiple flags. For example, if a processor has a negative flag and a zero flag, the equivalent of a positive flag is the case of both the negative and zero flags both simultaneously being cleared.
A few typical control flags (with processors that include them):
- decimal overflow trap enable Set if decimal overflow occurs (or conversion error on a VAX). Used in Digital VAX [DV].
- direction flag Determines the direction of string operations (set for autoincrement, cleared for autodecrement). Used in Intel 80x86 [DF].
- floating underflow trap enable Set if floating underflow occurs. Used in Digital VAX [FU].
- integer overflow trap enable Set if integer overflow occurs (or conversion error on a VAX). Used in Digital VAX [IV].
- interupt enable Set if interrupts enabled. Used in Intel 80x86 [IF].
- i/o privilege level Used to control access to I/O instructions and hardware (thereby seperating control over I/O from other supervisor/user states). Two bits. Used in Intel 80x86 [IO PL].
- nested task flag Used in Intel 80x86 [NF].
- resume flag Used in Intel 80x86 [RF].
- virtual 8086 mode Used to switch to virtual 8086 emulation. Used in Intel 80x86 [VM].
stack pointer
Stack pointers are used to implement a processor stack in memory. In many processors, address registers can be used as generic data stack pointers and queue pointers. A specific stack pointer or address register may be hardwired for certain instructions. The most common use is to store return addresses, processor state information, and temporary variables for subroutines.
- IBM 360/370: any of the 16 general purpose registers may be used as a stack pointer
- Intel 8086/80286: dedicated stack pointer (SP) combined with stack segment pointer (SS) to create address of stack
- Intel 80386: dedicated stack pointer (ESP) combined with stack segment pointer (SS) and the stack-frame base pointer (EBP) to create address of stack
- Motorola 680x0, 68300: dedicated user stack pointer (USP, A7) and system stack pointer (SSP, A7) for implicit stack pointer operations, as well as allowing any of the 8 address registers to be as explicit stack pointers
subroutine return pointer
Some RISC processors include a special subroutine return pointer rather than using a stack in memory. The return address for subroutine calls is stored in this register rather than in memory. More than one level of subroutine calls requires storing and saving the contents of this register to and from memory.
- Motorola 88100: r1 is a 32 bit register containing the return pointer generated by bsr and jsr instructions; the register can be read or overwritten by software and can even be used as a temporary general purpose data register
address modes
The basic addressing modes are: register direct, moving date to or from a specific register; register indirect, using a register as a pointer to memory; program counter-based, using the program counter as a reference point in memory; absolute, in which the memory addressis contained in the instruction; and immediate, in which the data is contained in the instruction. Some instructions will have an inherent or implicit address (usually a specific register or the memory contents pointed to by a specific register) that is implied by the instruction without explicit declaration.
One approach to processors places an emphasis on flexibility of addressing modes. Some engineers and programmers believe that the real power of a processor lies in its addressing modes. Most addressing modes can be created by combining two or more basic addressing modes, although building the combination in software will usually take more time than if the combination addressing mode existed in hardware (although there is a trade-off that slows down all operations to allow for more complexity).
In a purely othogonal instruction set, every addressing mode would be available for every instruction. In practice, this isn’t the case.
Virtual memory, memory pages, and other hardware mapping methods may be layered on top of the addressing modes.
register direct
In register direct address mode, the source and/or destination is a register.
Many processors distinguish between data and address register operations (note, in some cases a general purpose register can act as eeither an address or data register).
In data register direct operations, flags are typically set or cleared. Data that is smaller than the register may be sign extended or zero filled to fill the entire register, or may be placed only in the portion of the register necessary for the size of the data, leaving the rest of the register unchanged.
- Motorola 680x0, 68300: 32 bit data registers; data register direct operations set or clear flags; byte (8 bit), word (16 bit), and long versions (32 bit), only the low order portion of a destination register is changed; syntax: Dn
In register to register (RR) operations, data is transferred from one register to another register or an instruction uses a source and destination register.
- IBM 360/370: two byte instructions with a source and a destination register; 32 bit data registers; sets or clear flags; full word (32 bit) transfers; syntax: source, destination (as just a hexadecimal number or as a symbolic name)
- Motorola 680x0, 68300: instructions with a source and a destination register; 32 bit data registers; sets or clears flags; byte (8 bit), word (16 bit), and long versions (32 bit), only the low order portion of a destination register is changed; syntax: Dn, Dn
In address register direct operations, flags are not normally set or cleared. The address is usually sign extended to the full address size of the processor.
- Motorola 680x0, 68300: 32 bit address registers; address register direct operations do not modify flags; word (16 bit) and long versions (32 bit, 24 bits for the original 68000), word-size operands are sign-extended to 32 bits; syntax: An
register indirect
In register indirect address mode, the contents of the designated register are used as a pointer to memory. Variations of register indirect include the use of post- or pre- increment, post- or pre- decrement, and displacements.
In address register indirect operations, the designated register is used as a pointer to memory.
- Motorola 680x0, 68300: syntax: (An)
In address register indirect with postincrement operations, the designated register is used as a pointer to memory, and then the register is incremented by the size of the operation. This is useful for a loop where the same or similar operations are performed on consecutive locations in memory. This address mode can be combined with a complimentary predecrement mode for stack and queue operations.
- Motorola 680x0, 68300: syntax: (An)+
In address register indirect with predecrement operations, the designated register is decremented by the size of the operations, and then the designated register is used as a pointer to memory. This is useful for a loop where the same or similar operations are performed on consecutive locations in memory. This address mode can be combined with a complimentary postincrement mode for stack and queue operations.
- Motorola 680x0, 68300: syntax: -(An)
In address register indirect with preincrement operations, the designated register is incremented by the size of the operations, and then the designated register is used as a pointer to memory. This is useful for a loop where the same or similar operations are performed on consecutive locations in memory. This address mode can be combined with a complimentary postdecrement mode for stack and queue operations.
In address register indirect with postdecrement operations, the designated register is used as a pointer to memory, and then the register is decremented by the size of the operation. This is useful for a loop where the same or similar operations are performed on consecutive locations in memory. This address mode can be combined with a complimentary preincrement mode for stack and queue operations.
In address register indirect with displacement operations, the contents of the designated register are modified by adding or subtracting a dispacement integer, then used as a pointer to memory. The displacement integer is stored in the instruction, and if shorter than the length of a the processor’s address space (the normal case), sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 16 bit displacement integers, sign-extended to 32 bits; syntax: d(An)
register indirect with index register
In a register indirect with index register mode, two registers are added together to form the effective address of a pointer to memory. These are sometimes called the base register and index register. Many processors will have limits on which registers can be used for the base register and/or which registers can be used for the index register.
In address/base register indirect with index register operations, the contents of the index register are added to the contents of the base address register to form an effective address in memory. Some processors allow for designating that less than the full size of the index register be used in the computation, with the designated low order portion of the index register being sign-extended for the effective address computation. Some processors require that a designated low order portion of the index register be used in the computation, with the designated low order portion of the index register being sign-extended for the effective address computation.
In address/base register indirect with index register and displacement operations, the contents of the index register are added to the contents of the base address register and then an integer displacement is added or subtracted to form an effective address in memory. Some processors allow for designating that less than the full size of the index register be used in the computation, with the designated low order portion of the index register being sign-extended for the effective address computation. Some processors require that a designated low order portion of the index register be used in the computation, with the designated low order portion of the index register being sign-extended for the effective address computation. The integer displacement is stored in the instruction, and if shorter than the length of a the processor’s address space (the normal case), sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit displacement integer; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: d(An,Xn.s)
absolute address with index register
In absolute address with index register operations, the contents of an index register are added to an absolute address to form an effective address in memory.
- MIX: two byte absolute addresses with contents of one of five index registers
memory indirect
In memory indirect address mode, a location in memory contains a value that is used as a pointer (with or without additional effective address computations) to another location in memory.
In memory indirect postindexed operations, the processor calculates an intermediate memory address using a base register and a base displacement. The processor accesses the designated memory location, and adds the contents of the index register and an outer displacement to the memory value to yield the effective address. If either displacement and/or the index register is shorter than the length of a the processor’s address space (the normal case), each is sign-extended before addition (or subtraction). Base and outer displacements are stored in the instruction.
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit base and outer displacement integers; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: ([bAn], Xn.s, od)
In memory indirect preindexed operations, the processor calculates an intermediate memory address using a base register, a base displacement, and an index register. The processor accesses the designated memory location, and adds an outer displacement to the memory value to yield the effective address. If either displacement and/or the index register is shorter than the length of a the processor’s address space (the normal case), each is sign-extended before addition (or subtraction). Base and outer displacements are stored in the instruction.
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit base and outer displacement integers; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: ([bAn, Xn.s], od)
program counter indirect
In program counter indirect addressing, the program counter is used as a reference for the effective address computation. This is most commonly used for short branching relative to the current program counter, allowing for object code that can be placed anywhere in memory.
In program counter indirect with displacement operations, the effective address is the sum of the address in the program counter and the displacement integer stored in the instruction. If the displacement integer is shorter than the length of a the processor’s address space (the normal case), it is sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 16 bit displacement integer; syntax: dPC
In program counter indirect with index and displacement operations, the effective address is the sum of the address in the program counter, the contents of the index register, and the displacement integer stored in the instruction. If the displacement integer or designated portion of the index register is shorter than the length of a the processor’s address space (the normal case), each is sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit displacement integer; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: dPC,Xn
In program counter memory indirect postindexed operations, the processor calculates an intermediate indirect memory address by adding a base displacement to the contents of the program counter. The value accessed at this memory location is added to the scaled contents of the index register and the outer displacement to yield the effective address. If either the base or outer displacement integer or designated portion of the index register is shorter than the length of a the processor’s address space (the normal case), each is sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit base and outer displacement integers; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: ([dPC],Xn.s,od)
In program counter memory indirect preindexed operations, the processor calculates an intermediate indirect memory address by adding a base displacement and scaled contents of an index register to the contents of the program counter. The value accessed at this memory location is added to the outer displacement to yield the effective address. If either the base or outer displacement integer or designated portion of the index register is shorter than the length of a the processor’s address space (the normal case), each is sign-extended before addition (or subtraction).
- Motorola 680x0, 68300: 8 bit, 16 bit, or 32 bit base and outer displacement integers; index register component can be word (16 bit) or long (32 bit) and can have a scale factor of 0, 1, 2, 4, or 8; syntax: ([dPC,Xn.s],od)
absolute address
In absolute address mode, a pointer to the effective address in memory is part of the instruction. Some processors have full and short versions of absolute addressing (with short versions only pointing to a limited area in memory, normally starting at memory location zero). Unless overridden by hardware for virtual memory mapping, programs that use this address mode can not be moved in memory.
- MIX: two byte absolute addresses if I field is zero
- Motorola 680x0, 68300: 16 bit short and 32 bit long versions; syntax: xxx.W or xxx.L
immediate data
In immediate data address mode, the actual data is stored in the instruction. The sizes allowed for immediate data vary by processor and often by instruction (with some instructions having specific implied sizes).
- Motorola 680x0, 68300: byte (8 bit), word (16 bit), and long word (32 bit) versions; sign extended; syntax: #xxx
inherent address
Many instructions will have one or more inherent or implicit addresses. These are addresses that are implied by the instruction rather than explicitly stated. The two most common forms of inherent address are either a specific register or a memory location designated by the contents of a specific register.
executable instructions
Executable instructions can be divided into several broad categories of related operations.
There are four general classes of machine instructions. Some instructions may have characteristics of more than one major group. The four general classes of machine instructions are: computation, data transfer, sequencing, and environment control.
- “Computation: Implements a function from n-tuples of values to m-tuples of values. The function may affect the state. Example: A divide instruction whose arguments are a single-length integer divisor and a double-length integer dividend, whose results are a single-length integer quotient and a single-length integer remainder, and which may produce a divide check interrupt.” —Compiler Construction, by William M. Waite and Gerhard Goos, page 52b5
- “Data Transfer: Copies information, either within one storage class or from one storage class to another. Examples: A move instruction that copies the contents of one register to another; a read instruction that copies information from a disc to main storage.” —Compiler Construction, by William M. Waite and Gerhard Goos, page 52b5
- “Sequencing: Alters the normal execution sequence, either conditionally or unconditionally. Examples: a halt instruction that causes execution to terminate; a conditional jump instruction that causes the next instruction to be taken from a given address if a given register contains zero.” —Compiler Construction, by William M. Waite and Gerhard Goos, page 53b5
- “Environment control: Alters the environment in which execution is carried out. The lateration may involve a trasnfer of control. Examples: An interrupt disable instruction that prohibits certain interrupts from occurring; a procedure call instruction that updates addressing registers, thus changing the program’s addressing environment.” —Compiler Construction, by William M. Waite and Gerhard Goos, page 53b5
data movement
Data movement instructions move data from one location to another. The source and destination locations are determined by the addressing modes, and can be registers or memory. Some processors have different instructions for loading registers and storing to memory, while other processors have a single instruction with flexible addressing modes. Data movement instructions generally have the greatest options for addressing modes. Data movement instructions typically come in a variety of sizes. Data movement instructions destroy the previous contents of the destination. Data movement instructions typically set and clear processor flags. When the destination is a register and the data is smaller than the full register size, the data might be placed only in the low order bits (leaving high order bits unchanged), or might be zero- or sign-extended to fill the entire register (some processors only use one choice, others permit the programmer to choose how this is handled). Register to register operations can usually have the same source and destination register.
Earlier processors had different instructions and different names for different kinds of data movement, while most modern processors group data movement into a single symbolic name, with different kinds of data movement being indicated by address mode and size designation. A load instruction loads a register from memory. A store instruction stores the contents of a register into memory. A transfer instruction loads a register from another register. In processors that have separate names for different kinds of data moves, a memory to memory data move might be specially designated as a “move” instruction.
An exchange instruction exchanges the contents of two registers, two memory locations, or a register and a memory location (although some processors only have register-register exchanges or other limitations).
Some processors include versions of data movement instructions that can perform simple operations during the data move (such as compliment, negate, or absolute value).
Some processors include instructions that can save (to memory) or restore (from memory) a block of registers at one time (useful for implementing subroutines).
Some processors include instructions that can move a block of memory from one location to another at one time. If a processor includes string instructions, then there will usually be a string instruction that moves a string from one location in memory to another.
- MOVE Move Data; Motorola 680x0, Motorola 68300; move a byte (MOVE.B 8 bits), word (MOVE.W 16 bits), or longword (MOVE.L 32 bits) of data; memory to memory, memory to register, register to memory, or register to register; moves of byte and word data to registers leaves high order bits unchanged; sets or clears flags
- MOV Move Data; Intel 80x86; move a byte (8 bits), word (16 bits), or doubleword (32 bits) of data; memory to register, register to memory, or register to register (cannot move data from memory to memory or from segment register to segment register); does not affect flags
- MOV Move Data; DEC VAX; move a byte (MOVB 8 bits), word (MOVW 16 bits), longword (MOVL 32 bits), quadword (MOVQ 64 bits), octaword (MOVQ 128 bits), single precision floating (MOVF 32 bits), double precision floating (MOVD 64 bits), G floating (MOVG 64 bits), or H floating (MOVH 128 bits) of data; memory to memory, memory to register, register to memory, or register to register; moves of byte and word data to registers leaves high order bits unchanged; quadword, D float, and G float moves to or from registers are consecutive register pairs, octaword, and H float moves to or from registers are four consecutive registers; and sets or clears flags
- PUSH Push; Intel 80x86; decrement stack pointer and move a word (16 bits) or doubleword (32 bits) of data from memory or register (or byte of immediate data) onto stack; does not affect flags
- PUSHL Push Long; DEC VAX; decrement stack pointer (R14) and move a longword (32 bits) of data from memory or register onto stack; equivalent to MOVL src, -(SP), but shorter and executes faster; sets or clears flags
- POP Pop; Intel 80x86; move a word (16 bits) or doubleword (32 bits) of data from top of stack to register or memory and increment stack pointer; does not affect flags
- LR Load from Register; IBM 360/370; RR format; move a full word (32 bits) of data; register to register only; does not affect condition code
- L Load (from main storage); IBM 360/370; RX format; move a full word (32 bits) of data; main storage to register only; does not affect condition code
- LH Load Half-word; IBM 360/370; RX format; move a half-word (16 bits) of data; main storage to register only; does not affect condition code
- LDA Load A-register; MIX; move word or partial word field of data; main storage to accumulator only
- LDX Load X-register; MIX; move word or partial word field of data; main storage to extension register only
- LD_i_ Load index-register; MIX; move word or partial word field of data; main storage to one of five index registers only
- ST Store (into main storage); IBM 360/370; RX format; move a full word (32 bits) of data; register to main storage only; does not affect condition code
- STH Store Half-word; IBM 360/370; RX format; move a half-word (16 bits) of data; register to main storage only; does not affect condition code
- STA Store A-register; MIX; move word or partial word field of data; accumulator to main storage only
- STX Store X-register; MIX; move word or partial word field of data; extension register to main storage only
- ST_i_ Store index-register; MIX; move word or partial word field of data; one of five index registers to main storage only
- MVI MoVe Immediate; IBM 360/370; SI format; move a character (8 bits) of data; immediate data to register only; does not affect condition code
- MOVEQ Move Quick; Motorola 680x0, Motorola 68300; moves byte (8 bits) of sign-extended data (32 bits) to a data register; sets or clears flags
- CLR Clear; Motorola 680x0, Motorola 68300; clears a register or contents of a memory location (.B 8, .W 16, or .L 32 bits) to zero; clears flags for memory and data registers, does not modify flags for address register
- CLR Clear; DEC VAX; clears a scalar quantity in register or memory to zero (CLRB 8 bits, CLRW 16 bits, CLRL 32 bits, CLRQ 64 bits, CLRO 128 bits, CLRF 32 bit float, or CLRD 64 bit float), an integer CLR will clear the same size floating point quantity because VAX floating point zero is represented as all zero bits; quadword and D float clears of registers are consecutive register pairs, octaword clears to registers are four consecutive registers; equivalent to MOVx #0, dst, but shorter and executes faster; sets or clears flags
- STZ Store Zero; MIX; move word or partial word field of data, store zero into designated word or field of word of memory
- EXG Exchange; Motorola 680x0, Motorola 68300; exchanges the data (32 bits) in two data registers; does not affect flags
- XCHG Exchange; Intel 80x86; exchanges the data (16 bits or 32 bits) in a register with the AX or EAX register or exchanges the data (8 bits, 16 bits, or 32 bits) in a register with the contents of an effective address (register or memory); LOCK prefix and LOCK# signal asserted in XCGHs involving memory; does not affect flags
- MOVSX Move with Sign Extension; Intel 80x86; moves data from a register or memory to a register, with a sign extension (conversion to larger binary integer: byte to word, byte to doubleword, or word to doubleword); does not affect flags
- MOVZX Move with Zero Extension; Intel 80x86; moves data from a register or memory to a register, with a zero extension (conversion to larger binary integer: byte to word, byte to doubleword, or word to doubleword); does not affect flags
- MOVZ Move Zero Extended; DEC VAX; moves an unsigned integer to a larger unsigned integer with zero extend, source and destination in register or memory (MOVZBW Byte to Word, MOVZBL Byte to Long, MOVZWL Word to Long); sets or clears flags
- MCOM Move Complemented; DEC VAX; moves the logical complement (one’s complement) of an integer to register or memory (MCOMB 8 bits, MCOMW 16 bits, or MCOML 32 bits); sets or clears flags
- LCR Load Complement from Register; IBM 360/370; RR format; fetches a full word (32 bits) of data from one of 16 general purpose registers, complements the data, and stores a full word (32 bits) of data in one of 16 general purpose registers; register to register only; sets or clears flags
- LPR Load Positive from Register (absolute value); IBM 360/370; RR format; fetches a full word (32 bits) of data from one of 16 general purpose registers, creates the absolute value (positive) the data, and stores a full word (32 bits) of data in one of 16 general purpose registers; register to register only; sets or clears flags
- MNEG Move Negated; DEC VAX; moves the arithmetic negative of a scalar quantity to register or memory (MNEGB 8 bits, MNEGW 16 bits, MNEGL 32 bits, MNEGQ 64 bits, MNEGF 32 bit float, or MNEGD 64 bit float); if source is positive zero, result is also positive zero; sets or clears flags
- LNR Load Negative from Register (negative of absolute value); IBM 360/370; RR format; fetches a full word (32 bits) of data from one of 16 general purpose registers, creates the absolute value the data, complements (negative) the absolute value of the data, and stores a full word (32 bits) of data in one of 16 general purpose registers; register to register only; sets or clears flags
- LDAN Load A-register Negative; MIX; move word or partial word field of data, load sign field with opposite sign; main storage to accumulator only
- LDXN Load X-register Negative; MIX; move word or partial word field of data, load sign field with opposite sign; main storage to extension register only
- LD_i_N Load index-register Negative; MIX; move word or partial word field of data, load sign field with opposite sign; main storage to one of five index registers only
- STZ Store Zero; MIX; move word or partial word field of data, store zero into designated word or field of word of memory
- MVC MoVe Character; IBM 360/370; SS format; moves one to 256 characters (8 bits each) of data; main storage to main storage only; does not affect condition code
- MOVE Move (block); MIX; move the number of words specified by the F field from location M to the location specified by the contents of index register 1, incrementing the index register on each word moved
- MOVEM Move Multiple; Motorola 680x0, Motorola 68300; move contents of a list of registers to memory or restore from memory to a list of registers; does not affect condition code
- LM Load Multiple; IBM 360/370; RS format; moves a series of full words (32 bits) of data from memory to a series of general purpose registers; main storage to register only; does not affect condition code
- STM STore Multiple; IBM 360/370; RS format; moves contents of a series of general purpose registers to a series of full words (32 bits) in memory; register to main storage only; does not affect condition code
- PUSHA Push All Registers; Intel 80x86; move contents all 16-bit general purpose registers to memory pointed to by stack pointer (in the order AX, CX, DX, BX, original SP, BP, SI, and DI ); does not affect flags
- PUSHAD Push All Registers; Intel 80386; move contents all 32-bit general purpose registers to memory pointed to by stack pointer (in the order EAX, ECX, EDX, EBX, original ESP, EBP, ESI, and EDI ); does not affect flags
- POPA Pop All Registers; Intel 80x86; move memory pointed to by stack pointer to all 16-bit general purpose registers (except for SP); does not affect flags
- POPAD Pop All Registers; Intel 80386; move memory pointed to by stack pointer to all 32-bit general purpose registers (except for ESP); does not affect flags
- STJ Store jump-register; MIX; move word or partial word field of data; jump register to main storage only
- MOVEP Move Peripheral Data; Motorola 680x0, Motorola 68300; moves data (16 bits or 32 bits) from a data register to memory mapped peripherals or moves data from memory mapped peripherals to a data register, skipping every other byte
address movement
Address movement instructions move addresses from one location to another. The source and destination locations are determined by the addressing modes, and can be registers or memory. Address movement instructions can come in a variety of sizes. Address movement instructions destroy the previous contents of the destination. Address movement instructions typically do not modify processor flags. When the destination is a register and the address is smaller than the full register size, the data might be placed only in the low order bits (leaving high order bits unchanged), or might be zero- or sign-extended to fill the entire register (some processors only use one choice, others permit the programmer to choose how this is handled).
- MOVEA.W Move Address (Word); Motorola 680x0, Motorola 68300; move an address word (16 bits) as sign-extended data (32 bits); memory to address register or register to address register; does not modify flags
- MOVEA.L Move Address (Longword); Motorola 680x0, Motorola 68300; move an address longword (32 bits); memory to address register or register to address register; does not modify flags
- LEA Load Effective Address; Motorola 680x0, Motorola 68300; computes an effective address and loads the result into an address register
- LA Load Address; RX format; IBM 360/370; computes an effective address and loads the 24-bit result (zero extended to 32-bits) into a general purpose register; does not affect condition code
- ENTA Enter A-register; MIX; move word or partial word field contents of index register to A-register (accumulator)
- ENTX Enter X-register; MIX; move word or partial word field contents of index register to X-register (extension)
- ENT_i_ Enter I-register; MIX; move word or partial word field contents of index register to designated index register
- ENNA Enter Negative A-register; MIX; move word or partial word field contents of index register to A-register (accumulator), opposite sign loaded
- ENNX Enter Negative X-register; MIX; move word or partial word field contents of index register to X-register (extension), opposite sign loaded
- ENN_i_ Enter Negative I-register; MIX; move word or partial word field contents of index register to designated index register, opposite sign loaded
- INCA Increase A-register; MIX; add word or partial word field contents of memory to A-register (accumulator), overflow toggle possibly set
- INCX Increase X-register; MIX; add word or partial word field contents of memory to X-register (extension), overflow toggle possibly set
- INC_i_ Increase I-register; MIX; add word or partial word field contents of memory to designated index register, overflow toggle possibly set
- DECA Decrease A-register; MIX; subtract word or partial word field contents of memory from A-register (accumulator), overflow toggle possibly set
- DECX Decrease X-register; MIX; subtract word or partial word field contents of memory from X-register (extension), overflow toggle possibly set
- DEC_i_ Decrease I-register; MIX; subtract word or partial word field contents of memory from designated index register, overflow toggle possibly set
- PEA Push Effective Address; Motorola 680x0, Motorola 68300; computes an effective address and pushes the result onto a stack (predecrementing an address register acting as a stack pointer)
- LINK Link Stack; Motorola 680x0, Motorola 68300
- UNLK Unlink Stack; Motorola 680x0, Motorola 68300
integer arithmetic
For most processors, integer arithmetic is faster than floating point arithmetic. This can be reversed in special cases such digital signal processors.
The basic four integer arithmetic operations are addition, subtraction, multiplication, and division. Arithmetic operations can be signed or unsigned (unsigned is useful for effective address computations). Some older processors don’t include hardware multiplication and division. Some processors don’t include actual multiplication or division hardware, instead looking up the answer in a massive table of results embedded in the processor.
A specialized, but common, form of addition is an increment instruction, which adds one to the contents of a register or memory location. For address computations, “increment” may mean the addition of a constant other than one. Some processors have “short” or “quick” addition instructions that extend increment to include a small range of positive values.
A specialized, but common, form of subtraction is an decrement instruction, which subtracts one from the contents of a register or memory location. For address computations, “decrement” may mean the subtraction of a constant other than one. Some processors have “short” or “quick” subtraction instructions that extend decrement to include a small range of values.
Compare instructions are used to examine one or more integers non-destructively. These are usually implemented by performing a subtraction in some shadow register or accumulator and then setting flags accordingly. Compare instructions can compare two integers, or can compare a single integer to zero. Triadic compare instructions compare a test value to an upper and lower limit, which can be useful for bounds and range checking.
Some processors have specific hardware support for large multi-byte integer arithmetic. Even if there is no specific support, generally carry and borrow flags can be used to implement software multi-byte arithmetic routines.
Some processors have other special integer arithmetic operations. A clear instruction sets a register or memory location to zero. Some processors have special instructions for setting a register to a special value (such as pi) with additional guard bits also being set appropriately. A sign extend operation takes a small value and sign extends it to a larger storage format (such as byte to word). An arithmetic complement gives the arithmetic complement of a number (one’s complement). An arithmetic negate gives the arithmetic inverse of a number (subtract from zero; two’s complement).
- ADD Arithmetic Addition; DEC VAX; signed addition of scalar quantities (8, 16, or 32 bit integer or 32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand added to second operand with result replacing second operand) and three operand (first operand added to second operand with result placed in third operand) (ADDB2 add byte 2 operand, ADDB3 add byte 3 operand, ADDW2 add word 2 operand, ADDW3 add word 3 operand, ADDL2 add long 2 operand, ADDL3 add long 3 operand, ADDF2 add float 2 operand, ADDF3 add float 3 operand, ADDD2 add double float 2 operand, ADDD3 add double float 3 operand, ADDG2 add G float 2 operand, ADDG3 add G float 3 operand, ADDH2 add H float 2 operand, ADDH3 add H float 3 operand); clears or sets flags
- ADD Add Integers; Intel 80x86; integer add of the contents of a register or memory (8, 16, or 32 bits) to a memory location or a register; sets or clear flags
- ADD Add; Motorola 680x0, Motorola 68300; signed add of the contents of a data register (8, 16, or 32 bits) to a memory location or adds the contents of a memory location (8, 16, or 32 bits) to a data register; sets or clear flags
- ADD Add; MIX; add word or partial word field contents of memory to A-register (accumulator), overflow toggle set if result is too large for A-register
- AR Add Register; IBM 360/370; RR format; signed add of the contents of a general purpose register (32 bits) to a general purpose register (32 bits); register to register only; sets or clears flags
- A Add; IBM 360/370; RX format; signed add of the contents of a memory location (32 bits) to a general purpose register (32 bits); main memory to register only; sets or clears flags
- AH Add Half-word; IBM 360/370; RX format; signed add of the contents of a memory location (16 bits) to a general purpose register (low order 16 bits); main memory to register only; sets or clears flags
- ADDA Add Address; Motorola 680x0, Motorola 68300; unsigned add of the contents of a memory location or register (16 or 32 bits) to an address register; does not modify flags
- ADDI Add Immediate; Motorola 680x0, Motorola 68300; signed add of immediate data (8, 16, or 32 bits) to a register or memory location; sets or clears flags
- ADDQ Add Quick; Motorola 680x0, Motorola 68300; signed add of an immediate value of 1 to 8 inclusive to a register or memory lcoation; sets or clears flags for data registers and memory locations, does not modify flags for an address register
- INC Increment; DEC VAX; increments the integer contents of a general purpose register or contents of memory (INCB byte, INCW word, INCL longword); equivalent to ADDx2 #1, sum, but shorter and executes faster; clears or sets flags
- INC Increment by 1; Intel 80x86; increments the contents of a register or memory (8, 16, or 32 bits); sets or clear flags (does not modify carry flag)
- ADWC Add With Carry; DEC VAX; integer addition (32 bit) in general purpose registers or memory, first operand added to second operand and the C (carry) flag with result replacing second operand; used for multiprecision arithmetic; clears or sets flags
- ADC Add Integers with Carry; Intel 80x86; integer add of the contents of a register or memory (8, 16, or 32 bits) and the carry flag to a memory location or a register, used to implement multi-precision integer arithmetic; sets or clear flags
- ADDX Add Extended; Motorola 680x0, Motorola 68300; (signed add of a data register [8, 16, or 32 bits] and the extend bit to a data register) or (signed add of the contents of memory location [8, 16, or 32 bits] and the extend bit to the contents of another memory location while predecrementing both the source and destination address pointer registers), used to implement multi-precision integer arithmetic; sets or clears flags
- SUB Subtract; DEC VAX; signed subtraction of scalar quantities (8, 16, or 32 bit integer or 32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand subtracted from second operand with result replacing second operand) and three operand (first operand subtracted from second operand with result placed in third operand) (SUBB2 subtract byte 2 operand, SUBB3 subtract byte 3 operand, SUBW2 subtract word 2 operand, SUBW3 subtract word 3 operand, SUBL2 subtract long 2 operand, SUBL3 subtract long 3 operand, SUBF2 subtract float 2 operand, SUBF3 subtract float 3 operand, SUBD2 subtract double float 2 operand, SUBD3 subtract double float 3 operand, SUBG2 subtract G float 2 operand, SUBG3 subtract G float 3 operand, SUBH2 subtract H float 2 operand, SUBH3 subtract H float 3 operand); clears or sets flags
- SUB Subtract Integers; Intel 80x86; integer subtraction of the contents of a register or memory (8, 16, or 32 bits) from a memory location or a register; sets or clear flags
- SUB Subtract; Motorola 680x0, Motorola 68300; signed subtract of the contents of a data register (8, 16, or 32 bits) from a memory location or subtracts the contents of a memory location (8, 16, or 32 bits) from a data register; sets or clear flags
- SUB Subtract; MIX; subtract word or partial word field contents of memory from A-register (accumulator), overflow toggle possibly set
- SR Subtract Register; IBM 360/370; RR format; signed subtract of the contents of a general purpose register (32 bits) from a general purpose register (32 bits); register to register only; sets or clears flags
- S Subtract; IBM 360/370; RX format; signed subtract of the contents of a memory location (32 bits) from a general purpose register (32 bits); main memory to register only; sets or clears flags
- SH Subtract Half-word; IBM 360/370; RX format; signed subtract of the contents of a memory location (16 bits) from a general purpose register (low order 16 bits); main memory to register only; sets or clears flags
- SUBA Subtract Address; Motorola 680x0, Motorola 68300; unsigned subtract of the contents of a memory location or register (16 or 32 bits) from an address register; does not modify flags
- SUBI Subtract Immediate; Motorola 680x0, Motorola 68300; signed subtract of immediate data (8, 16, or 32 bits) from a register or memory location; sets or clears flags
- SUBQ Subtract Quick; Motorola 680x0, Motorola 68300; signed subtract of an immediate value of 1 to 8 inclusive from a register or memory lcoation; sets or clears flags for data registers and memory locations, does not modify flags for an address register
- DEC Decrement; DEC VAX; decrements the integer contents of a general purpose register or contents of memory (DECB byte, DECW word, DECL longword); equivalent to SUBx2 #1, sum, but shorter and executes faster; clears or sets flags
- DEC Decrement by 1; Intel 80x86; decrements the contents of a register or memory (8, 16, or 32 bits); sets or clear flags (does not modify carry flag)
- SBWC Subtract With Carry; DEC VAX; integer subtraction (32 bit) in general purpose registers or memory, first operand and the C (carry) flag subtracted from second operand with result replacing second operand; used for extended precision subtraction; clears or sets flags
- SBB Subtract Integers with Borrow; Intel 80x86; integer subtraction of the contents of a register or memory (8, 16, or 32 bits) and carry flag from a memory location or a register; sets or clear flags
- SUBX Subtract Extended; Motorola 680x0, Motorola 68300; (signed subtract of a data register [8, 16, or 32 bits] and the extend bit from a data register) or (signed subtract of the contents of memory location [8, 16, or 32 bits] and the extend bit from the contents of another memory location while predecrementing both the source and destination address pointer registers), used to implement multi-precision integer arithmetic; sets or clears flags
- MUL Multiply; DEC VAX; signed multiplication of scalar quantities (8, 16, or 32 bit integer) in general purpose registers or memory, available in two operand (first operand multiplied by second operand with result replacing second operand) and three operand (first operand multiplied by second operand with result placed in third operand) (MULB2 multiply byte 2 operand, MULB3 multiply byte 3 operand, MULW2 multiply word 2 operand, MULW3 multiply word 3 operand, MULL2 multiply long 2 operand, MULL3 multiply long 3 operand); clears or sets flags
- MULS.W Signed Multiply; Motorola 680x0, Motorola 68300; signed multiplication of a word (16 bits) from memory or a register by a word (16 bits) in a data register with a longword (32 bit) result stored in the entire data register; sets or clears flags
- MULS.L Signed Multiply; Motorola 680x0, Motorola 68300; signed multiplication of a longword (32 bits) from memory or a register by a longword (32 bits) in a data register with a longword (32 bit) result stored in the data register (high order 32 bits of product are discarded); sets or clears flags
- MULS.L ,Dh:Dl Signed Multiply; Motorola 680x0, Motorola 68300; signed multiplication of a longword (32 bits) from a data register by a longword (32 bits) in a data register with a quadword (64 bit) result stored in the data registers (high order 32 bits of product in first register, low order 32 bits of product in second data register); sets or clears flags
- MULU.W Unsigned Multiply; Motorola 680x0, Motorola 68300; unsigned multiplication of a word (16 bits) from memory or a register by a word (16 bits) in a data register with a longword (32 bit) result stored in the entire data register; sets or clears flags
- MULU.L Unsigned Multiply; Motorola 680x0, Motorola 68300; unsigned multiplication of a longword (32 bits) from memory or a register by a longword (32 bits) in a data register with a longword (32 bit) result stored in the data register (high order 32 bits of product are discarded); sets or clears flags
- MULU.L ,Dh:Dl Unsigned Multiply; Motorola 680x0, Motorola 68300; unsigned multiplication of a longword (32 bits) from a data register by a longword (32 bits) in a data register with a quadword (64 bit) result stored in the data registers (high order 32 bits of product in first register, low order 32 bits of product in second data register); sets or clears flags
- MUL Unsigned Multiplication of AL or AX; Intel 80x86; unsigned multiplication of a byte (8 bits) from register or memory by the contents of the AL register with a word (16-bit) result in AX register, or unsigned multiplication of a word (16 bits) from register or memory by the contents of the AX register with a doubleword (32-bit) result in DX:AX register pair, or unsigned multiplication of a doubleword (32 bits) from register or memory by the contents of the EAX register with a quadword (64-bit) result in EDX:EAX register pair; uses an early out algorithm to speed up computations when possible; sets or clears flags
- IMUL Signed Integer Multiply; Intel 80x86; signed multiplication of a byte (8 bits), word (16 bits), or doubleword (32 bits) from register or memory by the contents of the EAX and EDX registers with result stored in the EAX and EDX registers, signed multiplication of a byte (8 bits), word (16 bits), or doubleword (32 bits) from register or memory by the contents of a register with truncated results (to size as operands) stored in the register, or signed multiplication of a byte (8 bits), word (16 bits), or doubleword (32 bits) from register or memory by the contents of an immediate value with truncated results (to size as operands) stored in any general register; uses an early out algorithm to speed up computations when possible; sets or clears flags
- MUL Multiply; MIX; multiply word or partial word field contents of memory to A-register (accumulator) with results stored in X-register and A-register pair, overflow toggle possibly set
- MR Multiply Register; IBM 360/370; RR format; signed multiply of the contents of an even numbered general purpose register (32 bits) by the contents of the immediately following odd numbered general purpose register (32 bits) with a 64-bit product in the register pair; register to register only; does not affect condition code
- M Multiply; IBM 360/370; RX format; signed multiply of the contents of a memory location (32 bits) by the contents of an odd numbered general purpose register (32 bits) with a 64-bit product in the register pair; main storage to register only; does not affect condition code
- MH Multiply Half-word; IBM 360/370; RX format; signed multiply of the contents of a memory location (16 bits) by the contents of a general purpose register (32 bits) with a 32-bit product (the high 8 bits of the true 48-bit product are discarded) in the register; main storage to register only; does not affect condition code
- EMUL Extended Multiply; DEC VAX; extended precision multiplication on operands in registers or memory, the first (longword) operand (multiplicand) is multiplied by the second (longword) operand (multiplier) giving a (doubleword) intermediary result which is stored in the fourth (doubleword) operand (product); clears or sets flags
- EMOD Extended Multiply and Integerize; DEC VAX; performs accurate range reduction of math function arguments, the floating point multiplier extension operand (second operand) is concatenated with the floating point multiplier (first operand) to gain eight additional low order fraction bits, the multiplicand operand (third operand) is multiplied by the extended multiplier operand, after multiplication the integer portion (fourth operand) is extracted and a 32 bit (EMODF) or 64 bit (EMODD) floating point number is formed from the fractional part of the product by truncating extra bits, the multiplication is such that the result is equivalent to the exact product truncated (before normalization) to a fraction field of 32 bits in floating or 64 bits in double (fifth operand); clears or sets flags
- DIVS.W Signed Divide; Motorola 680x0, Motorola 68300; signed division of a longword (32 bits) in memory or a register by a word (16 bits) in a data register with a result of the quotient (16 bits) in the lower word and the remainder (16 bits) in the upper word of the data register; clears or sets flags
- DIVS.L ,Dq Signed Divide; Motorola 680x0, Motorola 68300; signed division of a longword (32 bits) in memory or a register by a longword (32 bits) in a data register with a result of a longword (32 bit) quotient in the data register and the remainder being discarded; clears or sets flags
- DIVS.L ,Dr:Dq Signed Divide; Motorola 680x0, Motorola 68300; signed division of a quadword (64 bits) in any two data registers by a longword (32 bits) in a data register with a result of the quotient (32 bits) in the second data register and the remainder (32 bits) in the third data register; clears or sets flags
- DIVSL.L ,Dr:Dq Signed Divide; Motorola 680x0, Motorola 68300; signed division of a longword (32 bits) in a data register by a longword (32 bits) in a second data register with a result of the quotient (32 bits) in the first data register and the remainder (32 bits) in the second data register; clears or sets flags
- DIVU.W Unsigned Divide; Motorola 680x0, Motorola 68300; unsigned division of a longword (32 bits) in memory or a register by a word (16 bits) in a data register with a result of the quotient (16 bits) in the lower word and the remainder (16 bits) in the upper word of the data register; clears or sets flags
- DIVU.L ,Dq Unsigned Divide; Motorola 680x0, Motorola 68300; unsigned division of a longword (32 bits) in memory or a register by a longword (32 bits) in a data register with a result of a longword (32 bit) quotient in the data register and the remainder being discarded; clears or sets flags
- DIVU.L ,Dr:Dq Unsigned Divide; Motorola 680x0, Motorola 68300; unsigned division of a quadword (64 bits) in any two data registers by a longword (32 bits) in a data register with a result of the quotient (32 bits) in the second data register and the remainder (32 bits) in the third data register; clears or sets flags
- DIVUL.L ,Dr:Dq Unsigned Divide; Motorola 680x0, Motorola 68300; unsigned division of a longword (32 bits) in a data register by a longword (32 bits) in a second data register with a result of the quotient (32 bits) in the first data register and the remainder (32 bits) in the second data register; clears or sets flags
- DR Divide Register; IBM 360/370; RR format; signed divide of the contents of a general purpose register pair (64 bits) by the contents of a general purpose register (32 bits) with a 32-bit quotient in the odd numbered register and a 32-bit remainder in the even numbered register of the register pair; register to register only; does not affect condition code
- D Divide; IBM 360/370; RX format; signed divide of the contents of a general purpose register pair (64 bits) by the contents of a memory location (32 bits) with a 32-bit quotient in the odd numbered register and a 32-bit remainder in the even numbered register of the register pair; main storage to register only; does not affect condition code
- DIV Divide; DEC VAX; arithmetic division of scalar quantities (8, 16, or 32 bit integer or 32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand [divisor] divided from second operand [dividend] with result [quotient] replacing second operand) and three operand (first operand [divisor] divided from second operand [dividend] with result placed in third operand [quotient]) (DIVB2 divide byte 2 operand, DIVB3 divide byte 3 operand, DIVW2 divide word 2 operand, DIVW3 divide word 3 operand, DIVL2 divide long 2 operand, DIVL3 divide long 3 operand, DIVF2 divide float 2 operand, DIVF3 divide float 3 operand, DIVD2 divide double float 2 operand, DIVD3 divide double float 3 operand, DIVG2 divide G float 2 operand, DIVG3 divide G float 3 operand, DIVH2 divide H float 2 operand, DIVH3 divide H float 3 operand); clears or sets flags
- EDIV Extended Divide; DEC VAX; extended precision multiplication on operands in registers or memory, the second (longword) operand (dividend) is divided from the first (longword) operand (divisor) giving the third (longword) operand (quotient) and the the fourth (longword) operand (remainder); clears or sets flags
- DIV Unsigned Divide; Intel 80x86; unsigned division of the accumulator by a byte (8 bits), word (16 bits), or doubleword (32 bits) divisor of half the size of the dividend in the accumulator, with the results stored in the accumulator (byte divisor: dividend is in the AX register, quotient in the AL register, and remainder in the AH register; word divisor: dividend is in the DX:AX register pair, quotient in the AX register, and remainder in the DX register; doubleword divisor: dividend is in the EDX:AEX register pair, quotient in the EAX register, and remainder in the EDX register); non-integral quotients are truncated to integers toward 0; sets or clears flags
- IDIV Signed Integer Division; Intel 80x86; Intel 80x86; signed division of the accumulator by a byte (8 bits), word (16 bits), or doubleword (32 bits) divisor of half the size of the dividend in the accumulator, with the results stored in the accumulator (byte divisor: dividend is in the AX register, quotient in the AL register, and remainder in the AH register; word divisor: dividend is in the DX:AX register pair, quotient in the AX register, and remainder in the DX register; doubleword divisor: dividend is in the EDX:AEX register pair, quotient in the EAX register, and remainder in the EDX register); non-integral quotients are truncated to integers toward 0; sets or clears flags
- DIV Divide; MIX; divide word or partial word field contents of memory from A-register (accumulator) and X-register (extension) pair with quotient stored in A-register and remainder stored in X-register, overflow toggle possibly set
- CMP Compare; DEC VAX; arithmetic comparison between two scalar quantities (8, 16, or 32 bit integer or 32 or 64 bit floating point) in general purpose registers or memory (CMPB Byte, CMPW Word, CMPL Longword, CMPF Floating, CMPD Double Float); clears or sets flags
- TST Test; DEC VAX; arithmetic comparison of a scalar quantities (8, 16, or 32 bit integer or 32 or 64 bit floating point) in general purpose registers or memory (TSTB Byte, TSTW Word, TSTL Longword, TSTF Floating, TSTD Double Float) to zero; equivalent to CMPs src, #0, but shorter and executes faster; clears or sets flags
- CMP Compare; Motorola 680x0, Motorola 68300; compares a register or contents of a memory location (8, 16, or 32 bits) to contents of a data register (data register minus effective address contents); clears or sets flags
- CMP Compare Two Operands; Intel 80x86; compares a register or contents of a memory location (8, 16, or 32 bits) to contents of a register or memory location (subtract of second operand from first operand with no storage of results, but setting or clearing of flags); clears or sets flags
- CMPA Compare A-register; MIX; compare word or partial word field contents of memory with same word or partial field of A-register (accumulator), set comparison indicator
- CMPX Compare X-register; MIX; compare word or partial word field contents of memory with same word or partial field of X-register (extension), set comparison indicator
- CMP_i_ Compare I-register; MIX; compare word or partial word field contents of memory with same word or partial field of designated index register, set comparison indicator
- CMPA Compare Address; Motorola 680x0, Motorola 68300; compares a register or contents of a memory location (16 or 32 bits) to contents of an address register (adress register minus effective address contents); clears or sets flags
- CMPI Compare Immediate; Motorola 680x0, Motorola 68300; compares immediate data (8, 16, or 32 bits) to contents of a register or memory (effective address contents minus immediate data); clears or sets flags
- CMPM Compare Memory; Motorola 680x0, Motorola 68300; compares the contents of two memory locations (8, 16, or 32 bits) with a post increment of both address pointer registers (second location minus first location); clears of sets flags
- CMP2 Compare Register Against Bounds; Motorola 680x0, Motorola 68300; compares the contents of register (8, 16, or 32 bits) to a bounds pair (lower bound followed by upper bound), if both bounds are equal then this operation tests for a specific value; sets or clears flags
- CLR Clear; Motorola 680x0, Motorola 68300; clears a register or contents of a memory location (.B 8, .W 16, or .L 32 bits) to zero; clears flags for memory and data registers, does not modify flags for address register
- CLR Clear; DEC VAX; clears a scalar quantity in register or memory to zero (CLRB 8 bits, CLRW 16 bits, CLRL 32 bits, CLRQ 64 bits, CLRO 128 bits, CLRF 32 bit float, or CLRD 64 bit float), an integer CLR will clear the same size floating point quantity because VAX floating point zero is represented as all zero bits; quadword and D float clears of registers are consecutive register pairs, octaword clears to registers are four consecutive registers; equivalent to MOVx #0, dst, but shorter and executes faster; sets or clears flags
- STZ Store Zero; MIX; move word or partial word field of data, store zero into designated word or field of word of memory
- EXT Sign Extend; Motorola 680x0, Motorola 68300; sign extends a byte (8 bits) in a data register to a word (16 bits) or sign extends a word (16 bits) in a data register to a longword (32 bits); sets or clears flags
- EXTB Sign Extend Byte; Motorola 680x0, Motorola 68300; sign extends a byte (8 bits) in a data register to a longword (32 bits); sets or clears flags
- NEG Two’s Complement Negation; Intel 80x86; subtracts the contents of a register or memory (8, 16, or 32 bits) from zero and store the results in the original register or memory location (arithmetic negation or arithmetic inverse); sets or clears flags
- NEG Negate; Motorola 680x0, Motorola 68300; subtracts the contents of a register or memory (8, 16, or 32 bits) from zero and store the results in the original register or memory location (arithmetic negation or arithmetic inverse); sets or clears flags
- NEGX Negate with Extend; Motorola 680x0, Motorola 68300; subtracts the contents of a register or memory location (8, 16, or 32 bits) and the extend bit from zero and stores the results in the original register or memory location (multi-precision negation); sets or clears flags
floating point arithmetic
On many processors, floating point arithmetic is in an optional unit or optional coprocessor rather than being included on the main processor. This allows the manufacturer to charge less for the business machines that don’t need floating point arithmetic.
The basic four floating point arithmetic operations are addition, subtraction, multiplication, and division. Some processors don’t include actual multiplication or division hardware, instead looking up the answer in a massive table of results embedded in the processor.
Compare instructions are used to examine one or more floating point numbers non-destructively. These are usually implemented by performing a subtraction in some shadow register or accumulator and then setting flags accordingly. Compare instructions can compare two floating point numbers, or can compare a single floating point number to zero.
- ADD Arithmetic Addition; DEC VAX; signed addition of scalar quantities (8, 16, or 32 bit integer or 32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand added to second operand with result replacing second operand) and three operand (first operand added to second operand with result placed in third operand) (ADDF2 add float 2 operand, ADDF3 add float 3 operand, ADDD2 add double float 2 operand, ADDD3 add double float 3 operand, ADDG2 add G float 2 operand, ADDG3 add G float 3 operand, ADDH2 add H float 2 operand, ADDH3 add H float 3 operand); clears or sets flags
- SUB Subtract; DEC VAX; signed subtraction of scalar quantities (32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand subtracted from second operand with result replacing second operand) and three operand (first operand subtracted from second operand with result placed in third operand) (SUBF2 subtract float 2 operand, SUBF3 subtract float 3 operand, SUBD2 subtract double float 2 operand, SUBD3 subtract double float 3 operand, SUBG2 subtract G float 2 operand, SUBG3 subtract G float 3 operand, SUBH2 subtract H float 2 operand, SUBH3 subtract H float 3 operand); clears or sets flags
- MUL Multiply; DEC VAX; signed multiplication of scalar quantities (32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand multiplied by second operand with result replacing second operand) and three operand (first operand multiplied by second operand with result placed in third operand) (MULF2 multiply float 2 operand, MULF3 multiply float 3 operand, MULD2 multiply double float 2 operand, MULD3 multiply double float 3 operand, MULG2 multiply G float 2 operand, MULG3 multiply G float 3 operand, MULH2 multiply H float 2 operand, MULH3 multiply H float 3 operand); clears or sets flags
- EMOD Extended Multiply and Integerize; DEC VAX; performs accurate range reduction of math function arguments, the floating point multiplier extension operand (second operand) is concatenated with the floating point multiplier (first operand) to gain eight additional low order fraction bits, the multiplicand operand (third operand) is multiplied by the extended multiplier operand, after multiplication the integer portion (fourth operand) is extracted and a 32 bit (EMODF) or 64 bit (EMODD) floating point number is formed from the fractional part of the product by truncating extra bits, the multiplication is such that the result is equivalent to the exact product truncated (before normalization) to a fraction field of 32 bits in floating or 64 bits in double (fifth operand); clears or sets flags
- DIV Divide; DEC VAX; arithmetic division of scalar quantities (32, 64, or 128 bit floating point) in general purpose registers or memory, available in two operand (first operand [divisor] divided from second operand [dividend] with result [quotient] replacing second operand) and three operand (first operand [divisor] divided from second operand [dividend] with result placed in third operand [quotient]) (DIVF2 divide float 2 operand, DIVF3 divide float 3 operand, DIVD2 divide double float 2 operand, DIVD3 divide double float 3 operand, DIVG2 divide G float 2 operand, DIVG3 divide G float 3 operand, DIVH2 divide H float 2 operand, DIVH3 divide H float 3 operand); clears or sets flags
- CMP Compare; DEC VAX; arithmetic comparison between two scalar quantities (8, 16, or 32 bit integer or 32 or 64 bit floating point) in general purpose registers or memory (CMPF Floating, CMPD Double Float); clears or sets flags
- TST Test; DEC VAX; arithmetic comparison of a scalar quantities (8, 16, or 32 bit integer or 32 or 64 bit floating point) in general purpose registers or memory (TSTF Floating, TSTD Double Float) to zero; equivalent to CMPs src, #0, but shorter and executes faster; clears or sets flags
binary coded decimals
Binary coded decimal (BCD) is a method for implementing lossless decimal arithmetic (including decimal fractions) on a binary computer. The most obvious uses involve money amounts where round-off error from using binary approximations is unacceptable.
BCD arithmetic includes BCD addition, BCD subtraction, BCD multiplication, BCD division, and BCD negate.
The Intel 80x86 series uses a two step approach for BCD arithmetic. Instead of having separate BCD instructions, the normal binary addition and subtraction instructions are used, then hardware instructions are used to adjust the results to correct BCD results. There are instuctions for both packed and unpacked adjustments.
Pack (Motorola 680x0) converts byte encoded numeric data (such as ASCII or EBCDIC characters) into binary coded decimals. Unpack (Motorola 680x0) converts binary coded decimals into byte encoded numeric data (such as ASCII or EBCDIC characters). The ASCII adjustment field is 3030;theEBCDICadjustmentfieldis3030; the EBCDIC adjustment field is 3030;theEBCDICadjustmentfieldisF0F0.
- ABCD Add Decimal with Extend; Motorola 680x0, Motorola 68300; performs binary coded decimal addition of source plus destination plus extend bit, source and destination can be two data registers or two locations in memory with the two address pointer registers being predecremented; sets or clears flags
- SBCD Subtract Decimal with Extend; Motorola 680x0; performs binary coded decimal subtraction of source and extend bit from destination, source and destination can be two data registers or two locations in memory with the two address pointer registers being predecremented; sets or clears flags
- NBCD Negate Decimal with Extend; Motorola 680x0, Motorola 68300; performs tens complement of contents of a data register or memory location by performing decimal coded binary subtraction of destination and extend bit from zero; sets or clears flags
- DAA Decimal Adjust after Addition; Intel 80x86; adjusts the result of adding two valid packed decimal operands in AL register; sets or clears flags
- DAS Decimal Adjust after Subtraction; Intel 80x86; adjusts the result of subtracting two valid packed decimal operands in AL register; sets or clears flags
- AAA ASCII Adjust after Addition; Intel 80x86; changes the contents of register AL to a valid unpacked decimal number, and zeros the top 4 bits; sets or clears flags
- AAS ASCII Adjust after Subtraction; Intel 80x86; changes the contents of register AL to a valid unpacked decimal number, and zeros the top 4 bits; sets or clears flags
- AAM ASCII Adjust after Multiplication; Intel 80x86; corrects the result of a multiplication of two valid unpacked decimal numbers, the high order digit is left in AH, the low order digit in AL; sets or clears flags
- AAD ASCII Adjust before Division; Intel 80x86; modifies the numerator in AH and AL to prepare for the division of two valid unpacked decimal operands so that the quotient produced by the division will be a valid unpacked decimal number, AH should contain the high-order digit and AL the low-order digit, this instruction adjusts the value and places the result in AL, AH will contain zero.; sets or clears flags
- NUM Convert to Numeric; MIX; converts byte encoded character code (MIX character code) in A-register/X-register pair to numeric data in the A-register (accumulator), does not change sign, overflow possible
- CHAR Convert to Characters; MIX; converts numeric data in the A-register (accumulator) into byte encoded character code (MIX character code) in A-register/X-register pair, does not change signs
- PACK Pack; Motorola 680x0; converts byte encoded numeric data (such as ASCII or EBCDIC characters) into binary coded decimals using an adjustment field ($3030 for ASCII, $F0F0 for EBCDIC), either from data register to data register or memory location to memory location with predecrement of address pointers; does not modify flags
- UNPK Unpack; Motorola 680x0; converts binary coded decimals into byte encoded numeric data (such as ASCII or EBCDIC characters) using an adjustment field ($3030 for ASCII, $F0F0 for EBCDIC), either from data register to data register or memory location to memory location with predecrement of address pointers; does not modify flags
advanced math operations
- EMOD Extended Multiply and Integerize; DEC VAX; performs accurate range reduction of math function arguments, the floating point multiplier extension operand (second operand) is concatenated with the floating point multiplier (first operand) to gain eight additional low order fraction bits, the multiplicand operand (third operand) is multiplied by the extended multiplier operand, after multiplication the integer portion (fourth operand) is extracted and a 32 bit (EMODF) or 64 bit (EMODD) floating point number is formed from the fractional part of the product by truncating extra bits, the multiplication is such that the result is equivalent to the exact product truncated (before normalization) to a fraction field of 32 bits in floating or 64 bits in double (fifth operand); clears or sets flags
- TBLS Table Lookup and Interpolate (Signed, Rounded); Motorola 68300; signed lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) + {(ENTRY(n+1) - ENTRY(n)) * Dx[7:0]} / 256 into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) is subtracted from the next consecutive table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is subtracted from the second data register-based table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; rounding is selected by the ‘R’ instruction field, for a rounding adjustment of -1, 0, or +1; sets or clears flags
- TBLSN Table Lookup and Interpolate (Signed, Not Rounded); Motorola 68300; signed lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) * 256 + (ENTRY(n+1) - ENTRY(n)) * Dx[7:0] into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) multiplied by 256, then added to the value determined by (selected table entry subtracted from the next consecutive table entry, then multiplied by the interpolation fraction), and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is multiplied by 256, then added to the value determined by (first data register-based table entry subtracted from the second data register-based table entry, then multiplied by the interpolation fraction), and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; sets or clears flags
- TBLU Table Lookup and Interpolate (Unsigned, Rounded); Motorola 68300; unsigned lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) + {(ENTRY(n+1) - ENTRY(n)) * Dx[7:0]} / 256 into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) is subtracted from the next consecutive table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is subtracted from the second data register-based table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; rounding is selected by the ‘R’ instruction field, for a rounding adjustment of 0 or +1; sets or clears flags
- TBLUN Table Lookup and Interpolate (Unsigned, Not Rounded); Motorola 68300; unsigned lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) * 256 + (ENTRY(n+1) - ENTRY(n)) * Dx[7:0] into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) multiplied by 256, then added to the value determined by (selected table entry subtracted from the next consecutive table entry, then multiplied by the interpolation fraction), and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is multiplied by 256, then added to the value determined by (first data register-based table entry subtracted from the second data register-based table entry, then multiplied by the interpolation fraction), and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; sets or clears flags
- POLY Polynomial Evaluation; DEC VAX; performs fast calculation of math functions, for degree times (second operand) evaluate a function using Horner’s method, where d=degree (second operand), x=argument (first operand), and result = C[0] + x*(C[1] + x*(C[2] + … x*C[d])), float result stored in D0 register, double float result stored in D0:D1 register pair, the table address operand (third operand) points to a table of polynomial coefficients ordered from highest order term of the polynomial through lower order coefficients stored at increasing addresses, the data type of the coefficients must be the same as the data type of the argument operand (first operand), the unsigned word degree operand (second operand) specifies the highest numbered coefficient to participate in the evaluation (POLYF polynomial evaluation floating, POLYD polynomial evaluation double float); D0 through D4 registers modified by POLYF, D0 through D5 registers modified by POLYD; sets or clears flags
data conversion
Data conversion instructions change data from one format to another.
A sign extension operation takes a small value and sign extends it to a larger storage format (such as byte to word).
A type conversion operation changes data from one format to another (such as signed two’s complement integer into binary coded decimal).
- EXT Sign Extend; Motorola 680x0, Motorola 68300; sign extends a byte (8 bits) in a data register to a word (16 bits) or sign extends a word (16 bits) in a data register to a longword (32 bits); sets or clears flags
- CVT Convert; DEC VAX; converts a signed quantity to a different signed data type, source and destination in register or memory, special rounded versions for certain floating conversions; sets or clears flags
- CVTBW Convert Byte to Word; sign extend
- CVTBL Convert Byte to Long; sign extend
- CVTWB Convert Word to Byte; truncated
- CVTWL Convert Word to Long; sign extend
- CVTLB Convert Long to Byte; truncated
- CVTLW Convert Long to Word; truncated
- CVTBF Convert Byte to Floating; exact
- CVTBD Convert Byte to Double float; exact
- CVTWF Convert Word to Floating; exact
- CVTWD Convert Word to Double float; exact
- CVTLF Convert Long to Floating; rounded
- CVTLD Convert Long to Double float; exact
- CVTFB Convert Floating to Byte; truncated
- CVTDB Convert Double float to Byte; truncated
- CVTFW Convert Floating to Word; truncated
- CVTDW Convert Double float to Word; truncated
- CVTFL Convert Floating to Long; truncated
- CVTRFL Convert Rounded Floating to Long; rounded
- CVTDL Convert Double float to Long; truncated
- CVTRDL Convert Rounded Double float to Long; rounded
- CVTFD Convert Floating to Double float; exact
- CVTDF Convert Double float to Floating; rounded
- CBW Convert Byte to Word; Intel 80x86; sign extends a byte (8 bits) in register AL to create a word (16 bits) in the AX register; does not affect flags
- CWD Convert Word to Doubleword; Intel 80x86; sign extends a word (16 bits) in register AX throughout the DX register to create a doubleword (32 bits); does not affect flags
- CWDE Convert Word to Doubleword Extended; Intel 80386; sign extends a word (16 bits) in register AX to create a doubleword (32 bits) in the EAX register; does not affect flags
- CDQ Convert Doubleword to Quadword; Intel 80386; sign extends a doubleword (32 bits) in register EAX to create a quadword (64 bits) in the EDX register; does not affect flags
- EXTB Sign Extend Byte; Motorola 680x0, Motorola 68300; sign extends a byte (8 bits) in a data register to a longword (32 bits); sets or clears flags
- MOVSX Move with Sign Extension; Intel 80x86; moves data from a register or memory to a register, with a sign extension (conversion to larger binary integer: byte to word, byte to doubleword, or word to doubleword); does not affect flags
- MOVZX Move with Zero Extension; Intel 80x86; moves data from a register or memory to a register, with a zero extension (conversion to larger binary integer: byte to word, byte to doubleword, or word to doubleword); does not affect flags
- MOVZ Move Zero Extended; DEC VAX; converts an unsigned integer to a larger unsigned integer, source and destination in register or memory (MOVZBW Byte to Word, MOVZBL Byte to Long, MOVZWL Word to Long); sets or clears flags
- PACK Pack; Motorola 680x0; converts converts byte encoded numeric data (such as ASCII or EBCDIC characters) into binary coded decimals using an adjustment field ($3030 for ASCII, $F0F0 for EBCDIC), either from data register to data register or memory location to memory location with predecrement of address pointers; does not modify flags
- UNPK Unpack; Motorola 680x0; converts converts converts binary coded decimals into byte encoded numeric data (such as ASCII or EBCDIC characters) using an adjustment field ($3030 for ASCII, $F0F0 for EBCDIC), either from data register to data register or memory location to memory location with predecrement of address pointers; does not modify flags
logical
Logical instructions typically work on a bit by bit basis, although some processors use the entire contents of the operands as whole flags (zero or not zero input, zero or negative one output). Typical logical operations include logical negation or logical complement (NOT), logical and (AND), logical inclusive or (OR or IOR), and logical exclusive or (XOR or EOR). Logical tests are a comparison of a value to a bit string (or operand treated as a bit string) of all zeros. Some processors have an instruction that sets or clears a bit or byte in registers or memory based on the processor condition codes.
- NOT Logical Complement; Motorola 680x0, Motorola 68300; calculates the one’s complement (logical negation) of the contents of memory or a register (8, 16, or 32 bits); sets or clears flags
- NOT One’s Complement Negation; Intel 80x86; calculates the one’s complement (logical negation) of the contents of memory or a register (8, 16, or 32 bits); does not modify flags
- AND And Logical; Motorola 680x0, Motorola 68300; performs a logical AND of a source operand with a destination operand and stores the result in the destination operand (8, 16, or 32 bits), one of the two operands must be a data register, the other operand can be the contents of any register or memory location; sets or clears flags
- ANDI And Immediate; Motorola 680x0, Motorola 68300; performs a logical AND of the contents of a register or memory location (8, 16, or 32 bits) with an immediate; sets or clears flags
- AND Logical AND; Intel 80x86; performs a logical AND between two registers, a register and contents of a memory location, or an immediate operand and either the contents of a register or the contents of a memory location; byte (8 bits), word (16 bits), or doubleword (32 bits); sets or clears flags
- OR Inclusive Or Logical; Motorola 680x0, Motorola 68300; performs a logical inclusive OR of a source operand with a destination operand and stores the result in the destination operand (8, 16, or 32 bits), one of the two operands must be a data register, the other operand can be the contents of any register or memory location; sets or clears flags
- ORI Inclusive Or Immediate; Motorola 680x0, Motorola 68300; performs a logical inclusive OR of the contents of a register or memory location (8, 16, or 32 bits) with an immediate; sets or clears flags
- OR Logical Inclusive OR; Intel 80x86; performs a logical OR between two registers, a register and contents of a memory location, or an immediate operand and either the contents of a register or the contents of a memory location; byte (8 bits), word (16 bits), or doubleword (32 bits); sets or clears flags
- BIS Bit Set; DEC VAX; performs a logical inclusive OR of the bit mask (first operand, register or memory) with the source (second operand, register or memory), available in two operand (results stored in second operand) and three operand (results stored in third operand) (BISB2 bit set byte 2 operand, BISB3 bit set byte 3 operand, BISW2 bit set word 2 operand, BISW3 bit set word 3 operand, BISL2 bit set longword 2 operand, BISL3 bit set longword 3 operand); sets or clears flags
- XOR Exclusive OR; DEC VAX; performs a logical exclusive OR of the bit mask (first operand, register or memory) with the source (second operand, register or memory), available in two operand (results stored in second operand) and three operand (results stored in third operand) (XORB2 exclusive or byte 2 operand, XORB3 exclusive or byte 3 operand, XORW2 exclusive or word 2 operand, XORW3 exclusive or word 3 operand, XORL2 exclusive or longword 2 operand, XORL3 exclusive or longword 3 operand); sets or clears flags
- EOR Exclusive Or Logical; Motorola 680x0, Motorola 68300; performs a logical exclusive or (XOR) of a source operand with a destination operand and stores the result in the destination operand (8, 16, or 32 bits), one of the two operands must be a data register, the other operand can be the contents of any register or memory location; sets or clears flags
- EORI Exclusive Or Immediate; Motorola 680x0, Motorola 68300; performs a logical exclusive or (XOR) of the contents of a register or memory location (8, 16, or 32 bits) with an immediate; sets or clears flags
- XOR Logical Exclusive OR; Intel 80x86; performs a logical exclusive OR between two registers, a register and contents of a memory location, or an immediate operand and either the contents of a register or the contents of a memory location; byte (8 bits), word (16 bits), or doubleword (32 bits); sets or clears flags
- BIC Bit Clear; DEC VAX; performs a complimented logical AND of the bit mask (first operand, register or memory) with the source (second operand, register or memory), available in two operand (results stored in second operand) and three operand (results stored in third operand) (BICB2 bit clear byte 2 operand, BICB3 bit clear byte 3 operand, BICW2 bit clear word 2 operand, BICW3 bit clear word 3 operand, BICL2 bit clear longword 2 operand, BICL3 bit clear longword 3 operand); sets or clears flags
- TST Test an Operand; Motorola 680x0, Motorola 68300; compares the contents of a register or memory location (8, 16, or 32 bits) with zero; sets or clears flags
- TEST Logical Compare; Intel 80x86; compares the contents of a register or memory location (8, 16, or 32 bits) with an immediate value or the contents of a register; sets or clears flags
- BIT Bit Test; DEC VAX; performs a logical AND of the bit mask (first operand, register or memory) with the source (second operand, register or memory) without modifying either operand and tests the resulting bits for being all zero (BITB byte, BITW word, BITL longword); sets or clears flags
- Scc Set According to Condition; Motorola 680x0, Motorola 68300; tests a condition code, if the condition is true then sets a byte (8 bits) of a data register or memory location to TRUE (all ones), if the condition is false then sets a byte (8 bits) of a data register or memory location to FALSE (all zeros): SCC, SCS, SEQ, SF, SGE, SGT, SHI, SLE, SLS, SLT, SMI, SNE, SPL, ST, SVC, SVS
- SETcc Set Byte on Condition cc; Intel 80x86; tests a condition code, if the condition is true then sets a byte (8 bits) of a data register or memory location to TRUE (all ones), if the condition is false then sets a byte (8 bits) of a data register or memory location to FALSE (all zeros): SETA, SETAE, SETB, SETBE, SETC, SETE, SETG, SETGE, SETL, SETLE, SETNA, SETNAE, SETNB, SETNBE, SETNC, SETNE, SETNG, SETNGE, SETNL, SETNLE, SETNO, SETNP, SETNS, SETNZ, SETO, SETP, SETPE, SETPO, SETS, SETZ
shift and rotate
Shift and rotate instructions move bit strings (or operand treated as a bit string).
Shift instructions move a bit string (or operand treated as a bit string) to the right or left, with excess bits discarded (although one or more bits might be preserved in flags). In arithmetic shift left or logical shift left zeros are shifted into the low-order bit. In arithmetic shift right the sign bit (most significant bit) is shifted into the high-order bit. In logical shift right zeros are shifted into the high-order bit.
Rotate instructions are similar to shift instructions, ecept that rotate instructions are circular, with the bits shifted out one end returning on the other end. Rotates can be to the left or right. Rotates can also employ an extend bit for multi-precision rotates.
A swap instruction swaps the high and low order portions of a register or contents of a series of memory locations.
The carry bit typically receives the last bit shifted out of the operand. Sometimes an extend bit will receive the last bit shifted out also. Somtimes an overflow bit is used to indicate a sign change has occurred.
- ASH Arithmetic Shift; DEC VAX; performs a bit shift on a longword or quadword, the first operand is a byte count, the second operand is the source longword or quadword in registers or memory, the third operand is the destination longword or quadword in registers or memory, positive counts causes a left shift with zeros entering in the least significant bits, negative count causes a right shift with the most significant bit being copied into the most significant bit, a zero count results in the destination being replaced by the unmodified source (ASHL arithmetic shift longword, ASHQ arithmetic shift quadword); sets or clears flags
- ASL Arithmetic Shift Left; Motorola 680x0, Motorola 68300; shifts the contents of a data register (8, 16, or 32 bits) or memory location (16 bits) to the left (towards most significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the high-order bit being shifted into the carry and extend flags, zeros shifted into the low-order bit, overflow flag indicating a change of sign; sets or clear flags
- SAL Shift Arithmetic Left; Intel 80x86; shifts the contents of a data register or memory location (8, 16, or 32 bits) to the left (towards most significant bit) by a specified amount (by 1, by 0 to 31 bits specified by an immediate operand, or by 0-31 bits specified by the contents of the CL register), with the high-order bit being shifted into the carry flag, zeros shifted into the low-order bit; sets or clear flags
- ASR Arithmetic Shift Right; Motorola 680x0, Motorola 68300; shifts the contents of a data register (8, 16, or 32 bits) or memory location (16 bits) to the right (towards the least significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the low-order bit being shifted into the carry and extend flags, the original high-order bit being replicated and shifted into the high-order bit; sets or clear flags
- SAR Shift Arithmetic Right; Intel 80x86; shifts the contents of a data register or memory location (8, 16, or 32 bits) to the right (towards least significant bit) by a specified amount (by 1, by 0 to 31 bits specified by an immediate operand, or by 0-31 bits specified by the contents of the CL register), with the low-order bit being shifted into the carry flag, the original high-order bit being replicated and shifted into the high-order bit; sets or clear flags
- SLA Shift Left A-register; MIX; byte shift the contents of the A-register (leaving sign unchanged) to the left by the designated number of bytes, with zeros shifted in to low order bytes
- SLAX Shift Left AX-register; MIX; byte shift the contents of the A-register and X-register pair (leaving signs unchanged) to the left by the designated number of bytes, with zeros shifted in to low order bytes
- LSL Logical Shift Left; Motorola 680x0, Motorola 68300; shifts the contents of a data register (8, 16, or 32 bits) or memory location (16 bits) to the left (towards most significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the high-order bit being shifted into the carry and extend flags, zeros shifted into the low-order bit; sets or clear flags
- SHL Shift Logical Left; Intel 80x86; shifts the contents of a data register or memory location (8, 16, or 32 bits) to the left (towards most significant bit) by a specified amount (by 1, by 0 to 31 bits specified by an immediate operand, or by 0-31 bits specified by the contents of the CL register), with the high-order bit being shifted into the carry flag, zeros shifted into the low-order bit; sets or clear flags
- SRA Shift Right A-register; MIX; byte shift the contents of the A-register (leaving sign unchanged) to the right by the designated number of bytes, with zeros shifted in to high order bytes
- SRAX Shift Right AX-register; MIX; byte shift the contents of the A-register and X-register pair (leaving signs unchanged) to the right by the designated number of bytes, with zeros shifted in to high order bytes
- LSR Logical Shift Right; Motorola 680x0, Motorola 68300; shifts the contents of a data register (8, 16, or 32 bits) or memory location (16 bits) to the right (towards the least significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the low-order bit being shifted into the carry and extend flags, and zeros shifted into the high-order bit; sets or clear flags
- SHR Shift Logical Right; Intel 80x86; shifts the contents of a data register or memory location (8, 16, or 32 bits) to the right (towards least significant bit) by a specified amount (by 1, by 0 to 31 bits specified by an immediate operand, or by 0-31 bits specified by the contents of the CL register), with the low-order bit being shifted into the carry flag, and zeros shifted into the high-order bit; sets or clear flags
- SHLD Double Precision Shift Left; Intel 80x86; shifts the contents of a general purpose register (16 or 32 bits) to the left (towards most significant bit) by a specified amount (by 0 to 31 bits specified by an immediate operand or by 0-31 bits specified by the contents of the CL register) with the high-order bits being shifted into a general purpose register or memory location (the source register is unchanged); used to implement multiprecision shifts, “bit blts” (BIT BLock Transfers), or bit string extracts and inserts; sets or clear flags
- SHRD Double Precision Shift Right; Intel 80x86; shifts the contents of a general purpose register (16 or 32 bits) to the right (towards least significant bit) by a specified amount (by 0 to 31 bits specified by an immediate operand or by 0-31 bits specified by the contents of the CL register) with the low-order bits being shifted into a general purpose register or memory location (the source register is unchanged); used to implement multiprecision shifts, “bit blts” (BIT BLock Transfers), or bit string extracts and inserts; sets or clear flags
- ROL Rotate Left; Motorola 680x0, Motorola 68300; rotates the contents of a data register (8, 16, or 32 bits) or a memory location (16 bits) to the left (towards the most significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the high-order bit rotating into both the carry flag and the low-order bit; sets or clear flags
- ROL Rotate Left; Intel 80x86; rotates the contents of a general purpose register or a memory location (8, 16, or 32 bits) to the left (towards the most significant bit) by a specified amount (by 1 bit or by 0 to 31 bits specified by an immediate operand or by the contents of the CL register); sets or clear flags
- SLC Shift Left AX-register Circularly; MIX; byte shift the contents of the A-register and X-register pair (leaving signs unchanged) to the left by the designated number of bytes, with bytes shifted off low order end entering on high order end
- ROTL Rotate Long; DEC VAX; performs a bit rotate on a longword, the first operand is a byte count, the second operand is the source longword in registers or memory, the third operand is the destination longword in registers or memory, positive counts causes a left rotate, negative count causes a right rotate, a zero count results in the destination being replaced by the unmodified source, bits shifted out one end are rotated back in the other end; sets or clears flags
- ROR Rotate Right; Motorola 680x0, Motorola 68300; rotates the contents of a data register (8, 16, or 32 bits) or a memory location (16 bits) to the right (towards the least significant bit) by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the low-order bit rotating into both the carry flag and the high-order bit; sets or clear flags
- ROR Rotate Right; Intel 80x86; rotates the contents of a general purpose register or a memory location (8, 16, or 32 bits) to the right (towards the least significant bit) by a specified amount (by 1 bit or by 0 to 31 bits specified by an immediate operand or by the contents of the CL register); sets or clear flags
- SRC Shift Right AX-register Circularly; MIX; byte shift the contents of the A-register and X-register pair (leaving signs unchanged) to the right by the designated number of bytes, with bytes shifted off high order end entering on low order end
- ROXL Rotate Left with Extend; Motorola 680x0, Motorola 68300; rotates the contents of a data register (8, 16, or 32 bits) or a memory location (16 bits) to the left (towards the most significant bit) through the extend bit by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the high-order bit rotating into both the carry flag and the extend bit and the extend bit rotating into the low-order bit; sets or clear flags
- RCL Rotate Through Carry Left; Intel 80x86; rotates the contents of a general purpose register or a memory location (8, 16, or 32 bits) to the left (towards the most significant bit) by a specified amount (by 1 bit or by 0 to 31 bits specified by an immediate operand or by the contents of the CL register) with the carry flag (CF) being treated as a high-order one-bit extension of the destination operand; sets or clear flags
- ROXR Rotate Right with Extend; Motorola 680x0, Motorola 68300; rotates the contents of a data register (8, 16, or 32 bits) or a memory location (16 bits) to the right (towards the least significant bit) through the extend bit by a specified amount (by 1 to 8 bits for an immediate operation on a data register, by the contents of a data register modulo 64 for a data register, or by 1 bit only for a memory location), with the low-order bit rotating into both the carry flag and the extend bit and the extend bit rotating into the high-order bit; sets or clear flags
- RCR Rotate Through Carry Right; Intel 80x86; rotates the contents of a general purpose register or a memory location (8, 16, or 32 bits) to the right (towards the least significant bit) by a specified amount (by 1 bit or by 0 to 31 bits specified by an immediate operand or by the contents of the CL register) with the carry flag (CF) being treated as as a low-order one-bit extension of the destination operand; sets or clear flags
- SWAP Swap; Motorola 680x0, Motorola 68300; exchanges the high order word (16 bits) with the low order word (16 bits) of a data register; sets or clears flags
bit manipulation
Bit manipulation instructions manipulate a specific bit of a bit string (or operand treated as a bit string). Bit clear changes the specified bit to zero. Bit set changes the specified bit to one. Bit change modifies a specified bit, clearing a one bit to zero and setting a zero bit to one. In some processors, the value of the bit before modification is tested. Bit test examines the value of a specified bit.
Bit scan instructions search a bit string for the first bit that is set or cleared (depending on the processor).
- BTST Bit Test; Motorola 680x0, Motorola 68300; tests the value of a specified bit in a register or memory location (8 bit memory operands, 32 bit register operands); sets or clears flags
- BIT Bit Test; Intel 80x86; tests the value of a specified bit in a general register or memory location; sets or clears flags
- BCLR Bit Test and Clear; Motorola 680x0, Motorola 68300; tests the value of a specified bit in a register or memory location (8 bit memory operands, 32 bit register operands), then clears the specified bit to zero; sets or clears flags
- BTR Bit Test and Reset; Intel 80x86; tests the value of a specified bit in a general register or memory location, then clears (resets) the specified bit to one; sets or clears flags
- BSET Bit Test and Set; Motorola 680x0, Motorola 68300; tests the value of a specified bit in a register or memory location (8 bit memory operands, 32 bit register operands), then sets the specified bit to one; sets or clears flags
- BTS Bit Test and Set; Intel 80x86; tests the value of a specified bit in a general register or memory location, then sets the specified bit to one; sets or clears flags
- BCHG Bit Test and Change; Motorola 680x0, Motorola 68300; tests the value of a specified bit in a register or memory location (8 bit memory operands, 32 bit register operands), then either clears a one bit to zero or sets a zero bit to one; sets or clears flags
- BTC Bit Test and Complement; Intel 80x86; tests the value of a specified bit in a general register or memory location, then complements; sets or clears flags
- BSF Bit Scan Forward; Intel 80x86; scans a word (16 bits) or doubleword (32 bits) in memory or a general register from low-order to high-order (starting from bit index zero) for a one-bit and store the index of the first set bit into a register (if no set bit is found, the value of the destination register is undefined); sets or clears flags
- BSR Bit Scan Reverse; Intel 80x86; scans a word (16 bits) or doubleword (32 bits) in memory or a general register from high-order to low-order (starting from bit index 15 of a word or index 31 of a doubleword) for a one-bit and store the index of the first set bit into a register (if no set bit is found, the value of the destination register is undefined); sets or clears flags
bit field
Bit field instructions make modifications to bit fields (or operands treated as bit fields). Bit field insert inserts a value into a bit field. Bit field extract extracts a signed or unsigned value from a bit field. Bit field find first one finds the first bit that is set (one) in a bit field. Bit field test evaluates a bit field and sets or clears flags. Bit field test and setevaluates a bit field and set or clear flags then sets the bit field. Bit field test and clearevaluates a bit field and set or clear flags then clears the bit field. Bit field test and changeevaluates a bit field and set or clear flags then changes the bit field.
- BFINS Bit Field Insert; Motorola 680x0; inserts a bit field (1 to 32 bits) from a data register to a location in data register or memory located by field offset and field width; sets or clears flags
- BFEXTU Bit Field Extract Unsigned; Motorola 680x0; extracts an unsigned bit field (1 to 32 bits) in registers or memory located by field offset and field width and zero extends the field into a data register (32 bits); sets or clears flags
- BFEXTS Bit Field Extract Signed; Motorola 680x0; extracts a signed bit field (1 to 32 bits) in registers or memory located by field offset and field width and sign extends the field into a data register (32 bits); sets or clears flags
- BFFFO Bit Field Find First One; Motorola 680x0; searches a bit field (1 to 32 bits) in registers or memory located by field offset and field width for the most significant bit that is set to a value of one; set or clears flags
- BFTST Bit Field Test; Motorola 680x0; sets condition codes according to the value of a bit field (1 to 32 bits) in registers or memory located by field offset and field width
- BIT Bit Test; DEC VAX; performs a logical AND of the bit mask (first operand, register or memory) with the source (second operand, register or memory) without modifying either operand and tests the resulting bits for being all zero (BITB byte, BITW word, BITL longword); sets or clears flags
- BFSET Test Bit Field and Set; Motorola 680x0; sets condition codes according to the value of a bit field (1 to 32 bits) in registers or memory located by field offset and field width, then sets the field; sets or clear flags
- BIS Bit Set; DEC VAX; performs a logical inclusive OR of the bit mask (first operand, register or memory) with the source (second operand, register or memory), available in two operand (results stored in second operand) and three operand (results stored in third operand) (BISB2 bit set byte 2 operand, BISB3 bit set byte 3 operand, BISW2 bit set word 2 operand, BISW3 bit set word 3 operand, BISL2 bit set longword 2 operand, BISL3 bit set longword 3 operand); sets or clears flags
- BFCLR Test Bit Field and Clear; Motorola 680x0; ; sets condition codes according to the value of a bit field (1 to 32 bits) in registers or memory located by field offset and field width, then clears the field; sets or clear flags
- BIC Bit Clear; DEC VAX; performs a complimented logical AND of the bit mask (first operand, register or memory) with the source (second operand, register or memory), available in two operand (results stored in second operand) and three operand (results stored in third operand) (BICB2 bit clear byte 2 operand, BICB3 bit clear byte 3 operand, BICW2 bit clear word 2 operand, BICW3 bit clear word 3 operand, BICL2 bit clear longword 2 operand, BICL3 bit clear longword 3 operand); sets or clears flags
- BFCHG Test Bit Field and Change; Motorola 680x0; sets condition codes according to the value of a bit field (1 to 32 bits) in registers or memory located by field offset and field width, then complements the field; sets or clear flags
- SHLD Double Precision Shift Left; Intel 80x86; shifts the contents of a general purpose register (16 or 32 bits) to the left (towards most significant bit) by a specified amount (by 0 to 31 bits specified by an immediate operand or by 0-31 bits specified by the contents of the CL register) with the high-order bits being shifted into a general purpose register or memory location (the source register is unchanged); used to implement multiprecision shifts, “bit blts” (BIT BLock Transfers), or bit string extracts and inserts; sets or clear flags
- SHRD Double Precision Shift Right; Intel 80x86; shifts the contents of a general purpose register (16 or 32 bits) to the right (towards least significant bit) by a specified amount (by 0 to 31 bits specified by an immediate operand or by 0-31 bits specified by the contents of the CL register) with the low-order bits being shifted into a general purpose register or memory location (the source register is unchanged); used to implement multiprecision shifts, “bit blts” (BIT BLock Transfers), or bit string extracts and inserts; sets or clear flags
table operations
- TBLS Table Lookup and Interpolate (Signed, Rounded); Motorola 68300; signed lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) + {(ENTRY(n+1) - ENTRY(n)) * Dx[7:0]} / 256 into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) is subtracted from the next consecutive table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is subtracted from the second data register-based table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; rounding is selected by the ‘R’ instruction field, for a rounding adjustment of -1, 0, or +1; sets or clears flags
- TBLSN Table Lookup and Interpolate (Signed, Not Rounded); Motorola 68300; signed lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) * 256 + (ENTRY(n+1) - ENTRY(n)) * Dx[7:0] into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) multiplied by 256, then added to the value determined by (selected table entry subtracted from the next consecutive table entry, then multiplied by the interpolation fraction), and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is multiplied by 256, then added to the value determined by (first data register-based table entry subtracted from the second data register-based table entry, then multiplied by the interpolation fraction), and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; sets or clears flags
- TBLU Table Lookup and Interpolate (Unsigned, Rounded); Motorola 68300; unsigned lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) + {(ENTRY(n+1) - ENTRY(n)) * Dx[7:0]} / 256 into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) is subtracted from the next consecutive table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is subtracted from the second data register-based table entry, then multiplied by the interpolation fraction, then divided by 256, then added to the first table entry, and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; rounding is selected by the ‘R’ instruction field, for a rounding adjustment of 0 or +1; sets or clears flags
- TBLUN Table Lookup and Interpolate (Unsigned, Not Rounded); Motorola 68300; unsigned lookup and interpolation of independent variable X from a compressed linear data table or between two register-based table entries of linear representations of dependent variable Y as a function of X; ENTRY(n) * 256 + (ENTRY(n+1) - ENTRY(n)) * Dx[7:0] into Dx; table version: data register low word contains the independent variable X, 8-bit integer part and 8-bit fractional part with assumed radix point located between bits 7 and 8, source effective address points to beginning of table in memory, integer part scaled to data size (byte, word, or longword) and used as offset from beginning of table, selected table entry (a linear representation of dependent variable Y) multiplied by 256, then added to the value determined by (selected table entry subtracted from the next consecutive table entry, then multiplied by the interpolation fraction), and then stored in the data register; register version: data register low byte contains the independent variable X 8-bit fractional part with assumed radix point located between bits 7 and 8, two data registers contain the byte, word, or longword table entries (a linear representation of dependent variable Y), first data register-based table entry is multiplied by 256, then added to the value determined by (first data register-based table entry subtracted from the second data register-based table entry, then multiplied by the interpolation fraction), and then stored in the destination (X) data register, the register interpolation mode may be used with several table lookup and interpolations to model multidimentional functions; sets or clears flags
high level language support
Many processors have instructions designed to support constructs common in high level languages. Ironically, a few high level language constructs have been based on specific hardware instructions on specific processors. One famous example is the computed GOTO (three possible branches based on whether the tested value is positive, zero, or negative), which is based on a hardware instruction in an early IBM processor (and if anyone can loan or give me a data book on the processor, I sure would appreciate it).
Most modern processors have some kind of loop instructions. These are some variation on the theme of testing for a condition and/or making a count with a short branch back to complete a loop if the exit condition fails.
Many modern processors have some kind of hardware support for temporary data storage (for the temporary variables used in subroutines and functions), combining special hardware instructions with argument and/or frame and/or stack pointers.
Bounds check instructions are used to check if an array reference is out of bounds.
- CMP2 Compare Register Against Bounds; Motorola 680x0, Motorola 68300; compares the contents of register (8, 16, or 32 bits) to a bounds pair (lower bound followed by upper bound), if both bounds are equal then this operation tests for a specific value; sets or clears flags
- BOUND Check Array Index Against Bounds; Intel 80x86; compares the contents of register (16 or 32 bits) to a bounds pair (lower bound followed by upper bound) in memory (source register contains address in memory of the first of two consecutive bounds), if the check fails, then an Interrupt 5 occurs; does not modify flags
- CHK Check Register Against Bounds; Motorola 680x0, Motorola 68300; compares a word (16-bits) or longword (32-bits) value in a data register to a lower bound of zero and a two’s complement upper bound specified in a data register or memory, a value of less than zero or greater than the upper bound results in a CHK instruction exception, vector number 6; sets or clears flags
- CHK2 Check Register Against Two Bounds; Motorola 680x0, Motorola 68300; compares a byte (8-bits), word (16-bits), or longword (32-bits) value in a data or address register to a bounds pair specified in memory, a value of less than the lower bound or greater than the upper bound results in a CHK instruction exception, vector number 6; sets or clears flags
- DBcc Test Condition, Decrement, and Branch; Motorola 680x0, Motorola 68300; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, starts by testing a designated condition, if the test is true then no additional action is taken and the program continues to the next instruction (exiting the loop), if the test is false then the designated data register is decremented, if the result is exactly -1 then the program continues to the next instruction (exiting the loop), otherwise the program makes a short (16 bit) branch to continue the loop: DBCC, DBCS, DBEQ, DBF, DBGE, DBGT, DBHI, DBLE, DBLS, DBLT, DBMI, DBNE, DBPL, DBT, DBVC, DBVS
- LOOP Loop While ECX Not Zero; Intel 80x86; used to implement DO loops, decrements the ECX or CX (count) register and then tests to see if it is zero, if the ECX or CX register is zero then the program continues to the next instruction (exiting the loop), otherwise the program makes a byte branch to contine the loop; does not modify flags
- LOOPE Loop While Equal; Intel 80x86; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, decrements the ECX or CX (count) register and then tests to see if it is zero, if the ECX or CX register is zero or the Zero Flag is clear (zero) then the program continues to the next instruction (to exit the loop), otherwise the program makes a byte branch (to continue the loop); equivalent to LOOPZ; does not modify flags
- LOOPNE Loop While Not Equal; Intel 80x86; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, decrements the ECX or CX (count) register and then tests to see if it is zero, if the ECX or CX register is zero or the Zero Flag is set (one) then the program continues to the next instruction (to exit the loop), otherwise the program makes a byte branch (to continue the loop); equivalent to LOOPNZ; does not modify flags
- LOOPNZ Loop While Not Zero; Intel 80x86; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, decrements the ECX or CX (count) register and then tests to see if it is zero, if the ECX or CX register is zero or the Zero Flag is set (one) then the program continues to the next instruction (to exit the loop), otherwise the program makes a byte branch (to continue the loop); equivalent to LOOPNE; does not modify flags
- LOOPZ Loop While Zero; Intel 80x86; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, decrements the ECX or CX (count) register and then tests to see if it is zero, if the ECX or CX register is zero or the Zero Flag is clear (zero) then the program continues to the next instruction (to exit the loop), otherwise the program makes a byte branch (to continue the loop); equivalent to LOOPE; does not modify flags
- JCXZ Jump if Count Register Zero; Intel 80x86; conditional jump if CX (count register) is zero; used to prevent entering loop if the count register starts at zero; does not modify flags
- JECXZ Jump if Extended Count Register Zero; Intel 80x86; conditional jump if ECX (count register) is zero; used to prevent entering loop if the count register starts at zero; does not modify flags
- LINK Link Stack; Motorola 680x0, Motorola 68300
- UNLK Unlink Stack; Motorola 680x0, Motorola 68300
program control
Program control instructions change or modify the flow of a program.
The most basic kind of program control is the unconditional branch or unconditional jump. Branch is usually an indication of a short change relative to the current program counter. Jump is usually an indication of a change in program counter that is not directly related to the current program counter (such as a jump to an absolute memory location or a jump using a dynamic or static table), and is often free of distance limits from the current program counter.
The pentultimate kind of program control is the conditional branch or conditional jump. This gives computers their ability to make decisions and implement both loops and algorithms beyond simple formulas.
Most computers have some kind of instructions for subroutine call and return from subroutines.
There are often instructions for saving and restoring part or all of the processor state before and after subroutine calls. Some kinds of subroutine or return instructions will include some kinds of save and restore of the processor state.
Even if there are no explicit hardware instructions for subroutine calls and returns, subroutines can be implemented using jumps (saving the return address in a register or memory location for the return jump). Even if there is no hardware support for saving the processor state as a group, most (if not all) of the processor state can be saved and restored one item at a time.
NOP, or no operation, takes up the space of the smallest possible instruction and causes no change in the processor state other than an advancement of the program counter and any time related changes. It can be used to synchronize timing (at least crudely). It is often used during development cycles to temporarily or permanently wipe out a series of instructions without having to reassemble the surrounding code.
Stop or halt instructions bring the processor to an orderly halt, remaining in an idle state until restarted by interrupt, trace, reset, or external action.
Reset instructions reset the processor. This may include any or all of: setting registers to an initial value, setting the program counter to a standard starting location (restarting the computer), clearing or setting interrupts, and sending a reset signal to external devices.
- BRA Branch; Motorola 680x0, Motorola 68300; short (16 bit) unconditional branch relative to the current program counter
- JMP Jump; Motorola 680x0, Motorola 68300; unconditional jump (any valid effective addressing mode other than data register)
- JMP Jump; Intel 80x86; unconditional jump (near [relative displacement from PC] or far; direct or indirect [based on contents of general purpose register, memory location, or indexed])
- JMP Jump; MIX; unconditional jump to location M; J-register loaded with the address of the instruction which would have been next if the jump had not been taken
- JSJ Jump, Save J-register; MIX; unconditional jump to location M; J-register unchanged
- Jcc Jump Conditionally; Intel 80x86; conditional jump (near [relative displacement from PC] or far; direct or indirect [based on contents of general purpose register, memory location, or indexed]) based on a tested condition: JA/JNBE, JAE/JNB, JB/JNAE, JBE/JNA, JC, JE/JZ, JNC, JNE/JNZ, JNP/JPO, JP/JPE, JG/JNLE, JGE/JNL, JL/JNGE, JLE/JNG, JNO, JNS, JO, JS
- Bcc Branch Conditionally; Motorola 680x0, Motorola 68300; short (16 bit) conditional branch relative to the current program counter based on a tested condition: BCC, BCS, BEQ, BGE, BGT, BHI, BLE, BLS, BLT, BMI, BNE, BPL, BVC, BVS
- JOV Jump on Overflow; MIX; conditional jump to location M if overflow toggle is on; if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken
- JNOV Jump on No Overflow; MIX; conditional jump to location M if overflow toggle is off; if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken
- Jcc Jump on Condition; MIX; conditional jump to location M based on comparison indicator; if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken; JL (less), JE (equal), JG (greater), JGE (greater-or-equal), JNE (unequal), JLE (less-or-equal)
- JAcc Jump on A-register; MIX; conditional jump to location M based on A-register (accumulator); if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken; JAN (negative), JAZ (zero), JAP (positive), JANN (nonnegative), JANZ (nonzero, JAMP (nonpositive)
- JXcc Jump on X-register; MIX; conditional jump to location M based on X-register (extension); if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken; JXN (negative), JXZ (zero), JXP (positive), JXNN (nonnegative), JXNZ (nonzero, JXMP (nonpositive)
- J_i_cc Jump on I-register; MIX; conditional jump to location M based on one of five I-registers (index); if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken; J_i_N (negative), J_i_Z (zero), J_i_P (positive), J_i_NN (nonnegative), J_i_NZ (nonzero, J_i_MP (nonpositive)
- DBcc Test Condition, Decrement, and Branch; Motorola 680x0, Motorola 68300; used to implement DO loops, WHILE loops, UNTIL loops, and similar constructs, starts by testing a designated condition, if the test is true then no additional action is taken and the program continues to the next instruction (exiting the loop), if the test is false then the designated data register is decremented, if the result is exactly -1 then the program continues to the next instruction (exiting the loop), otherwise the program makes a short (16 bit) branch (continueing the loop): DBCC, DBCS, DBEQ, DBF, DBGE, DBGT, DBHI, DBLE, DBLS, DBLT, DBMI, DBNE, DBPL, DBT, DBVC, DBVS
- Scc Set According to Condition; Motorola 680x0, Motorola 68300; tests a condition code, if the condition is true then sets a byte (8 bits) of a data register or memory location to TRUE (all ones), if the condition is false then sets a byte (8 bits) of a data register or memory location to FALSE (all zeros): SCC, SCS, SEQ, SF, SGE, SGT, SHI, SLE, SLS, SLT, SMI, SNE, SPL, ST, SVC, SVS
- SETcc Set Byte on Condition cc; Intel 80x86; tests a condition code, if the condition is true then sets a byte (8 bits) of a data register or memory location to TRUE (all ones), if the condition is false then sets a byte (8 bits) of a data register or memory location to FALSE (all zeros): SETA, SETAE, SETB, SETBE, SETC, SETE, SETG, SETGE, SETL, SETLE, SETNA, SETNAE, SETNB, SETNBE, SETNC, SETNE, SETNG, SETNGE, SETNL, SETNLE, SETNO, SETNP, SETNS, SETNZ, SETO, SETP, SETPE, SETPO, SETS, SETZ
- BSR Branch to Subroutine; Motorola 680x0, Motorola 68300; pushes the address of the next instruction following the subroutine call onto the system stack, decrements the system stack pointer, and changes program flow to a location (8, 16, or 32 bits) relative to the current program counter
- JSR Jump to Subroutine; Motorola 680x0, Motorola 68300; pushes the address of the next instruction following the subroutine call onto the system stack, decrements the system stack pointer, and changes program flow to the address specified (any valid effective addressing mode other than data register)
- CALL Call Procedure; Intel 80x86; pushes the address of the next instruction following the subroutine call onto the system stack, decrements the system stack pointer, and changes program flow to the address specified (near [relative displacement from PC] or far; direct or indirect [based on contents of general purpose register or memory location])
- RTS Return from Subroutine; Motorola 680x0, Motorola 68300; fetches the return address from the top of the system stack, increments the system stack pointer, and changes program flow to the return address
- RET Return From Procedure; Intel 80x86; fetches the return address from the top of the system stack, increments the system stack pointer, and changes program flow to the return address; optional immediate operand added to the new top-of-stack pointer, effectively removing any arguments that the calling program pushed on the stack before the execution of the corresponding CALL instruction; possible change to lesser privilege
- RTR Return and Restore Condition Codes; Motorola 680x0, Motorola 68300; transfers the value at the top of the system stack into the condition code register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer, and changes program flow to the return address
- IRET Return From Interrupt; Intel 80x86; transfers the value at the top of the system stack into the flags register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer, and changes program flow to the return address; optional immediate operand added to the new top-of-stack pointer, effectively removing any arguments that the calling program pushed on the stack before the execution of the corresponding CALL instruction; possible change to lesser privilege
- RTD Return and Deallocate; Motorola 680x0, Motorola 68300; fetches the return address from the top of the system stack, increments the system stack pointer by the specified displacement value (effectively deallocating temporary storage space from the stack), and changes program flow to the return address
- RTE Return from Exception; Motorola 680x0, Motorola 68300; transfers the value at the top of the system stack into the status register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer by a displacement value designated by format mode (effectively deallocating temporary storage space from the stack, the amount of space varying by type of exception that occurred), and changes program flow to the return address; privileged instruction (supervisor state)
- MOVEM Move Multiple; Motorola 680x0, Motorola 68300; move contents of a list of registers to memory or restore from memory to a list of registers
- LM Load Multiple; IBM 360/370; RS format; moves a series of full words (32 bits) of data from memory to a series of general purpose registers; main storage to register only; does not affect condition code
- STM STore Multiple; IBM 360/370; RS format; moves contents of a series of general purpose registers to a series of full words (32 bits) in memory; register to main storage only; does not affect condition code
- PUSHA Push All Registers; Intel 80x86; move contents all 16-bit general purpose registers to memory pointed to by stack pointer (in the order AX, CX, DX, BX, original SP, BP, SI, and DI ); does not affect flags
- PUSHAD Push All Registers; Intel 80386; move contents all 32-bit general purpose registers to memory pointed to by stack pointer (in the order EAX, ECX, EDX, EBX, original ESP, EBP, ESI, and EDI ); does not affect flags
- POPA Pop All Registers; Intel 80x86; move memory pointed to by stack pointer to all 16-bit general purpose registers (except for SP); does not affect flags
- POPAD Pop All Registers; Intel 80386; move memory pointed to by stack pointer to all 32-bit general purpose registers (except for ESP); does not affect flags
- STJ Store jump-register; MIX; move word or partial word field of data; jump register to main storage only
- NOP No Operation; Motorola 680x0, Motorola 68300; no change in processor state other than an advance of the program counter
- NOP No Operation; MIX; no change in processor state other than an advance of the program counter
- STOP Stop; Motorola 680x0, Motorola 68300; loads an immediate operand into the program status register (both user and supervisor portions), advances program counter to next instruction, and stops the processor from fetching and executing instructions; privileged instruction (supervisor state)
- HLT Halt; MIX; stop machine, computer restarts on next instruction
- LPSTOP Low Power Stop; Motorola 68300; loads an immediate operand into the program status register (both user and supervisor portions), advances program counter to next instruction, and stops the processor from fetchhing and executing instructions, the new interrupt mask is copied to the external bus interface (EBI), internal clocks are stopped, the processor remains stopped until a trace, higher interrupt than new mask, or reset exception occurs; privileged instruction (supervisor state)
condition codes
Condition codes are the list of possible conditions that can be tested during conditional instructions. Typical conditional instructions include: conditional branches, conditional jumps, and conditional subroutine calls. Some processors have a few additional data related conditional instructions, and some processors make every instruction conditional. Not all condition codes available for a processor will be implemented for every conditional instruction.
Zero is mathematically neither positive nor negative, but for processor condition codes, most processors treat zero as either a positive or a negative numbers. Processors that treat zero as a positive number include the Motorola 680x0 and Motorola 68300.
- A above; Intel 80x86; unsigned conditional transfer; equivalent to NBE; (not carry flag and not zero flag)
- AE above or equal; Intel 80x86; unsigned conditional transfer; equivalent to NB; (not carry flag
- B below; Intel 80x86; unsigned conditional transfer; equivalent to NAE; (carry flag)
- BE below or equal; Intel 80x86; unsigned conditional transfer; equivalent to NA; (carry flag or zero flag)
- C carry; Intel 80x86; unsigned conditional transfer; (carry flag)
- CC Carry Clear; Motorola 680x0, Motorola 68300; not carry flag
- CS Carry Set; Motorola 680x0, Motorola 68300; carry flag
- E equal; Intel 80x86; unsigned conditional transfer; equivalent to Z; (zero flag)
- EQ Equal; Motorola 680x0, Motorola 68300; zero flag
- F False (never true); Motorola 680x0, Motorola 68300; never
- G greater; Intel 80x86; signed conditional transfer; equivalent to NLE; (not ((sign flag xor overflow flag) or zero flag))
- GE Greater or Equal; Motorola 680x0, Motorola 68300; (negative flag and overflow flag) or (not negative flag and not overflow flag)
- GE greater or equal; Intel 80x86; signed conditional transfer; equivalent to NL; (not (sign flag xor overflow flag))
- GT Greater Than; Motorola 680x0, Motorola 68300; (negative flag and overflow flag and not zero flag) or (not negative flag and not overflow flag and not zero flag)
- HI High; Motorola 680x0, Motorola 68300; not carry flag and not zero flag
- L less; Intel 80x86; signed conditional transfer; equivalent to NGE; (sign flag xor overflow flag)
- LE Less or Equal; Motorola 680x0, Motorola 68300; (zero flag) or (negative flag and not overflow flag) or (not negative flag and overflow flag)
- LE less or equal; Intel 80x86; signed conditional transfer; equivalent to NG; ((sign flag xor overflow flag) or zero flag)
- LS Low or Same; Motorola 680x0, Motorola 68300; carry flag or zero flag
- LT Less Than; Motorola 680x0, Motorola 68300; (negative flag and not overflow flag) or (not negative flag and overflow flag)
- MI Minus; Motorola 680x0, Motorola 68300; negative flag
- NA not above; Intel 80x86; unsigned conditional transfer; equivalent to BE; (carry flag or zero flag)
- NAE not above nor equal; Intel 80x86; unsigned conditional transfer; equivalent to B; (carry flag)
- NB not below; Intel 80x86; unsigned conditional transfer; equivalent to AE; (not carry flag)
- NBE not below nor equal; Intel 80x86; unsigned conditional transfer; equivalent to A; (not carry flag and not zero flag)
- NC not carry; Intel 80x86; unsigned conditional transfer; (not carry flag)
- NE Not Equal; Motorola 680x0, Motorola 68300; not zero flag
- NE not equal; Intel 80x86; unsigned conditional transfer; equivalent to NZ; (not zero flag)
- NG not greater; Intel 80x86; signed conditional transfer; equivalent to LE; ((sign flag xor overflow flag) or zero flag)
- NGE not greater nor equal; Intel 80x86; signed conditional transfer; equivalent to L; (sign flag xor overflow flag)
- NL not less; Intel 80x86; signed conditional transfer; equivalent to GE; (not (sign flag xor overflow flag))
- NLE not less nor equal; Intel 80x86; signed conditional transfer; equivalent to G; (not ((sign flag xor overflow flag) or zero flag))
- NO not overflow; Intel 80x86; signed conditional transfer; (not overflow flag)
- NP not parity; Intel 80x86; unsigned conditional transfer; equivalent to PO; (not parity flag)
- NS not sign (positive or zero); Intel 80x86; signed conditional transfer; (not sign flag)
- NZ not zero; Intel 80x86; unsigned conditional transfer; equivalent to NE; (not zero flag)
- O overflow; Intel 80x86; signed conditional transfer; (overflow flag)
- P parity; Intel 80x86; unsigned conditional transfer; equivalent to PE; (parity flag)
- PE parity; Intel 80x86; unsigned conditional transfer; equivalent to P; (parity flag)
- PL Plus; Motorola 680x0, Motorola 68300; not negative flag
- PO parity odd; Intel 80x86; unsigned conditional transfer; equivalent to NP; (not parity flag)
- S sign (negative); Intel 80x86; signed conditional transfer; (sign flag)
- T True (always true); Motorola 680x0, Motorola 68300; always
- VC Overflow Clear; Motorola 680x0, Motorola 68300; not overflow flag
- VS Overflow Set; Motorola 680x0, Motorola 68300; overflow flag
- Z zero; Intel 80x86; unsigned conditional transfer; equivalent to E; (zero flag)
input/output
Input/Output (I/O) instructions are used to input data from peripherals, output data to peripherals, or read/write input/output controls. Early computers used special hardware to handle I/O devices. The trend in modern computers is to map I/O devices in memory, allowing the direct use of any instruction that operates on memory for handling I/O.
- IN Input; MIX; initiate transfer of information from the input device specified into consecutive locations starting with M, block size implied by unit
- OUT Output; MIX; initiate transfer of information from consecutive locations starting with M to the output device specified, block size implied by unit
- IOC Input-Output Control; MIX; initiate I/O control operation to be performed by designated device
- JRED Jump Ready; MIX; Jump if specified unit is ready (completed previous IN, OUT, or IOC operation); if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken
- JBUS Jump Busy; MIX; Jump if specified unit is not ready (not yet completed previous IN, OUT, or IOC operation); if jump occurs, J-register loaded with the address of the instruction which would have been next if the jump had not been taken
MIX devices
Information on the devices for the hypothetical MIX processor’s input/output instructions.
| unit number | peripheral | block size | control |
|---|---|---|---|
| t | Tape unit no. i (0  i 7) i 7) |
100 words | M=0, tape rewound;M < 0, skip back M records;M > 0, skip forward M records |
| d | Disk or drum unit no. d (8 d 15) |
100 words | position device according to X-register (extension) |
| 16 | Card reader | 16 words | |
| 17 | Card punch | 16 words | |
| 18 | Printer | 24 words | IOC 0(18) skips printer to top of following page |
| 19 | Typewriter and paper tape | 14 words | paper tape reader: rewind tape |
system control
System control instructions control some basic element of the system or processor state.
Many system control instructions are privileged, meaning that only certain trusted routines are allowed to use them. This is implemented by having privilege states. The most simple version is two states: user and supervisor states. The user state can’t run any privileged instructions, while the supervisor state can run all instructions. Some processors have more than two privilege states, allowing greater granularity of freedom to increasingly trusted operations.
The most basic kind of system control instructions are those that modify the condition codes or user portion of a status register.
Closely related are instructions that modify an entire status word or status register. The more powerful version is a privileged instruction and includes access to portions of the status register that can control or modify other processes.
Machine control instructions directly affect the entire processor. Stop or halt instructions bring the processor to an orderly halt, remaining in an idle state until restarted by interrupt, trace, reset, or external action.
Reset instructions reset the processor. This may include any or all of: setting registers to an initial value, setting the program counter to a standard starting location (restarting the computer), clearing or setting interrupts, and sending a reset signal to external devices.
Trap generating instructions generate a system trap. This includes a transition to a privileged state and turns control over to a routine with supervisor permission. This allows user processes to communicate with and make requests of the operating system. Note that it is common for some parts of an operating system to run in normal user mode so as to limit potential damage if something goes wrong.
Memory management instructions control memory and how memory is mapped and accessed by user and system routines. These instructions are almost always privileged and vary greatly from processor to processor (although the general capabilities and effects are pretty standard).
- MOVE , CCR Move to Condition Codes Register; Motorola 680x0, Motorola 68300; moves data from data register, memory, or immediate data to user condition codes register
- MOVE CCR, Move from Condition Codes Register; Motorola 680x0, Motorola 68300; moves data from user condition codes register to data register or memory
- ANDI #data, CCR And Immediate to Condition Codes Register; Motorola 680x0, Motorola 68300; logical AND of the immediate data with the user condition codes register
- ORI #data, CCR Or Immediate to Condition Codes Register; Motorola 680x0, Motorola 68300; logical inclusive OR of the immediate data with the user condition codes register
- EORI #data, CCR Exclusive Or Immediate to Condition Codes Register; Motorola 680x0, Motorola 68300; logical exclusive OR of the immediate data with the user condition codes register
- MOVE , SR Move to Status Register; Motorola 680x0, Motorola 68300; moves data from data register, memory, or immediate data to entire status register; privileged instruction (supervisor state)
- MOVE SR, Move from Status Register; Motorola 680x0, Motorola 68300; moves data from entire status register to data register or memory; privileged instruction (supervisor state)
- ANDI #data, SR And Immediate to Status Register; Motorola 680x0, Motorola 68300; logical AND of the immediate data with the entire status register; privileged instruction (supervisor state)
- ORI #data, SR Or Immediate to Status Register; Motorola 680x0, Motorola 68300; logical inclusive OR of the immediate data with the entire status register; privileged instruction (supervisor state)
- EORI #data, SR Exclusive Or Immediate to Status Register; Motorola 680x0, Motorola 68300; logical exclusive OR of the immediate data with the entire status register; privileged instruction (supervisor state)
- MOVE USP Move User Stack Pointer; Motorola 680x0, Motorola 68300; moves the contents of the user stack pointer to or from the specified address register; privileged instruction (supervisor state)
- MOVEC Move Control Register; Motorola 680x0, Motorola 68300; moves the contents of the specified address or data register to the specified control register or moves the contents of the specified control register to the specified data or address register (zero filled to 32 bits), control registers: Source Function Code (SFC) register, Destination Function Code (DFC) register, Cache Control Register (CACR), User Stack Pointer (USP), Vector Base Register (VBR), Cache Address Register (CAAR), Master Stack Pointer (MSP), Interrupt Stack Pointer (ISP); privileged instruction (supervisor state)
- MOVES Move Address Space; Motorola 680x0, Motorola 68300; moves information between address spaces (allowing data communication across process boundaries), either moving data (8, 16, or 32 bits) from a specified address or data register to a memory location in the address space specified by the destination fucntion code (DFC) register or moves date (8, 16, or 32 bits) from a memory location in the address space specified by the source function code (SFC) register to the specified data or address register; does not modify flags; privileged instruction (supervisor state)
- STOP Stop; Motorola 680x0, Motorola 68300; loads an immediate operand into the program status register (both user and supervisor portions), advances program counter to next instruction, and stops the processor from fetchhing and executing instructions; privileged instruction (supervisor state)
- LPSTOP Low Power Stop; Motorola 68300; loads an immediate operand into the program status register (both user and supervisor portions), advances program counter to next instruction, and stops the processor from fetchhing and executing instructions, the new interrupt mask is copied to the external bus interface (EBI), internal clocks are stopped, the processor remains stopped until a trace, higher interrupt than new mask, or reset exception occurs; privileged instruction (supervisor state)
- RTE Return from Exception; Motorola 680x0, Motorola 68300; transfers the value at the top of the system stack into the status register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer by a displacement value designated by format mode (effectively deallocating temporary storage space from the stack, the amount of space varying by type of exception that occurred), and changes program flow to the return address; privileged instruction (supervisor state)
coprocessor and multiprocessor operations
Multiprocessor instructions are used to coordinate activity between multiple processors.
Some multiprocessor instructions are designed to allow the processors to communicate with each other. A test and set instruction is used to implement flags or semaphores between processors. A compare and swap instruction is used to implement more sophsticated communications between multiple processors (such as counters or queue pointers) or secure updates of shared system control data structures in a multi-processing environment. Interlocked instructions are used to update counters, flags, and semaphores while locking out any other processors or devices from changing or reading the memory location while it is being updated.
- TAS Test and Set an Operand; Motorola 680x0; tests the current value of the operand at the effective address in memory or a data register (obviously, data register operands aren’t multiprocessor, but the instruction still works) and sets or clears the N (negative) and Z (zero) condition codes accordingly, then sets the high order bit of the operand to one; this operation uses a read-modify-write memory cycle that completes the operation without interruption; sets or clears flags
- CAS Compare and Swap with Operand; Motorola 680x0; Compares the operand at an effective address in memory to a compare operand in a data register, if the operands are equal, the update operand is transferred from a data register to the original effective address, if the operands are unequal, the operand at the effective address is transferred to the data register that contained the compare operand; this operation uses a read-modify-write memory cycle that completes the operation without interruption; sets or clears flags
- CAS2 Dual Operand Compare and Swap; Motorola 680x0; Compares the operand at an effective address in memory to a compare operand in a data register, if the operands are equal, compares the operand at a second effective address in memory to a second compare operand in a data register, if the second operand is also equal, the update operands are transferred from a data register to the pair of original effective addresses, if either pair of operands are unequal, the operands at the pair of effective addresses are transferred to the data registers that contained the compare operands; this operation uses a read-modify-write memory cycle that completes the operation without interruption; sets or clears flags
- ADAWI Add Aligned Word Interlocked; DEC VAX; adds (16 bit integer) a source operand from a register or memory to a memory location that is word aligned while interlocking the memory location so that no other processor or device can read or write to the interlocked memory location, used to maintain operating system resource usage counts; and sets or clears flags
trap generating
Trap generating instructions generate an exception that transfer control from software (usually application programs) to the operating system.
Operating system traps provide a mechanism to change to higher privilege levels (if they exist on the processor) and usually include a mechanism for identifying what kind of trap has occurred. This allows application programs to make requests of the operating system and may provide a hardware mechanism for switching from a user mode to a superviser, kernel, or other higher privilege level for the operating system response to the request.
A breakpoint instruction is used with external debugging hardware. The breakpoint instruction replaces an ordinary instruction (or the first part of an instruction) and relies on external debugging hardware to supply the missing instruction (or part of an instruction).
Various check instructions will test for conditions, trapping if the test fails. One common example is a check against bounds or limits.
Most processors have one or more illegal instructions. These are usually instructions that haven’t been implemented yet or instructions that have been dropped from a processor line. Many processors generate a trap or exception upon encountering an illegal instruction. Some processors will execute illegal instructions, which can lead to undocumented operations. Undocumented operations tend to change from one batch of processors to another and are highly unreliable. Some processors reserve an opcode that is guaranteed to always be illegal and always generate a trap or exception.
- TRAP Trap; Motorola 680x0, Motorola 68300; generates a trap exception with a trap vector (32 plus an immediate value in the range of 0 to 15); does not modify flags
- TRAPcc Trap on Condition; Motorola 680x0, Motorola 68300; if the tested condition is ture, generates a trap exception with vector 7, with optional word (16-bits) or longword (32-bits) immediate operand being available for the software trap handler: TRAPCC, TRAPCS, TRAPEQ, TRAPF, TRAPGE, TRAPGT, TRAPHI, TRAPLE, TRAPLS, TRAPLT, TRAPMI, TRAPNE, TRAPPL, TRAPT, TRAPVC, TRAPVS
- Axxx A-line Trap; Motorola 680x0, Motorola 68300; generates an a-line trap with the 12 bit value in the byte and a half of the instruction word used as a vector into a trap table; reserved for use by computer hardware manufacturers to provide software routines or implement supporting hardware features (used in the Macintosh to provide operating system calls); does not modify flags
- BKPT Breakpoint; Motorola 680x0, Motorola 68300; asserts a breakpoint acknowledge bus cycle with an immediate breakpoint vector (0 to 7) on address lines A2-A4 (not to be confused with address registers), if external hardware terminates the cycle, the data (one instruction word) on the bus is inserted into the instruction pipe, otherwise generates an illegal instruction exception; does not modify flags
- CHK Check Register Against Bounds; Motorola 680x0, Motorola 68300; compares a word (16-bits) or longword (32-bits) value in a data register to a lower bound of zero and a two’s complement upper bound specified in a data register or memory, a value of less than zero or greater than the upper bound results in a CHK instruction exception, vector number 6; sets or clears flags
- CHK2 Check Register Against Two Bounds; Motorola 680x0, Motorola 68300; compares a byte (8-bits), word (16-bits), or longword (32-bits) value in a data or address register to a bounds pair specified in memory, a value of less than the lower bound or greater than the upper bound results in a CHK instruction exception, vector number 6; sets or clears flags
- ILLEGAL Take Illegal Instruction Trap; Motorola 680x0, Motorola 68300; generates an illegal instruction exception, vector 4; does not modify flags
- TRAPV Trap; Motorola 680x0, Motorola 68300; if the overflow condition is set, generates a TRAPV exception, vector 7; does not modify flags
- INT Interrupt; Intel 80x86; pushes flags register and return address on stack and then generates a software call to the interrupt handler designated by the immediate operand (0 to 255) as in index into the Interrupt Descriptor Table (IDT), in Protected Mode the IDT is an array of eight-byte descriptors, in Real Address Mode the IDT is an array of doubleword (32 bit) pointers, the first 32 entries are reserved to Intel (matching hardware interrupts and exceptions), the base address of the IDT is the contents of the IDTR
- INTO Interrupt if Overflow; Intel 80x86; if the Overflow flag is set, pushes flags register and return address on stack and then generates a software call to the fourth (4) interrupt handler in the Interrupt Descriptor Table (IDT), in Protected Mode the IDT is an array of eight-byte descriptors, in Real Address Mode the IDT is an array of doubleword (32 bit) pointers, the first 32 entries are reserved to Intel (matching hardware interrupts and exceptions), the base address of the IDT is the contents of the IDTR
- IRET Return From Interrupt; Intel 80x86; transfers the value at the top of the system stack into the flags register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer, and changes program flow to the return address; optional immediate operand added to the new top-of-stack pointer, effectively removing any arguments that the calling program pushed on the stack before the execution of the corresponding CALL instruction; possible change to lesser privilege
- RTE Return from Exception; Motorola 680x0, Motorola 68300; transfers the value at the top of the system stack into the status register, increments the system stack pointer, fetches the return address from the top of the system stack, increments the system stack pointer by a displacement value designated by format mode (effectively deallocating temporary storage space from the stack, the amount of space varying by type of exception that occurred), and changes program flow to the return address; privileged instruction (supervisor state)
further reading: books:
If you want your book reviewed, please send a copy to: Milo, POB 1361, Tustin, CA 92781, USA.
Price listings are for courtesy purposes only and may be changed by the referenced businesses at any time without notice.
further reading: books: general
Structured Computer Organization, 4th edition; by Andrew S. Tanenbaum; Prentice Hall; October 1998; ISBN 0130959901; Paperback; 669 pages; $95.00; used by CS 308-273A (Principles of Assembly Languages) at McGill University School of Computer Science
Computers: An Introduction to Hardware and Software Design; by Larry L. Wear, James R. Pinkert (Contributor), William G. Lane (Contributor); McGraw-Hill Higher Education; February 1991; ISBN 0070686742; Hardcover; 544 pages; $98.60; used by CS 308-273A (Principles of Assembly Languages) at McGill University School of Computer Science
further reading: books: Motorola 680x0

68000 Family Assembly Language/Book and Disk (PWS Series in Engineering); by Alan Clements, B.Sc.; PWS Pub Co; August 1994; ISBN 0534932754; Hardcover; 720 pages; $98.95; used by CS 308-273A (Principles of Assembly Languages) at McGill University School of Computer Science
Assembly Language and Systems Programming for the M68000 Family, 2nd edition; by William Ford, William Topp; Jones & Bartlett Pub; November 1996; ISBN 0763703575; Hardcover; 890 pages; $78.95; used by CIS 260 (Honors: Machine Organization and Microcomputers) at University of Delaware Department of Department of Computer & Information Sciences
 Macintosh Assembly System, version 2.0; by William Ford, William Topp; Jones & Bartlett Pub; January 1992; ISBN 0763705950; Textbook Binding; $37.50; used by CIS 260 (Honors: Machine Organization and Microcomputers) at University of Delaware Department of Department of Computer & Information Sciences
Macintosh Assembly System, version 2.0; by William Ford, William Topp; Jones & Bartlett Pub; January 1992; ISBN 0763705950; Textbook Binding; $37.50; used by CIS 260 (Honors: Machine Organization and Microcomputers) at University of Delaware Department of Department of Computer & Information Sciences
further reading: books: Motorola 68300
The Motorola Mc68332 Microcontroller: Product Design, Assembly Language Programming, and Interfacing; by Thomas L. Harman; Prentice Hall; March 1991; ISBN 0136031277; Paperback; 512 pages; $41.25; used by EE 380 (Introduction to Microprocessors) at University of Alberta Department of Electrical and Computer Engineering
further reading: books: IBM System 360/370
 Assembler Language Programming The IBM System/360 and 370; 2nd edition; by George W. Struble (University of Oregon); Addison-Wesley Publishing Company; 1975, 1969; ISBN 0-201-07322-6; hardcover; 477 pages; special order
Assembler Language Programming The IBM System/360 and 370; 2nd edition; by George W. Struble (University of Oregon); Addison-Wesley Publishing Company; 1975, 1969; ISBN 0-201-07322-6; hardcover; 477 pages; special order
further reading: books: DEC VAX
 VAX-11 Assembly Language Programming; by Sara Baase (San Diego State University); Prentice-Hall, Inc.; 1983; ISBN 0-13-940957-2; hardcover; 407 pages; special order
VAX-11 Assembly Language Programming; by Sara Baase (San Diego State University); Prentice-Hall, Inc.; 1983; ISBN 0-13-940957-2; hardcover; 407 pages; special order

If you want your book reviewed, please send a copy to: Milo, POB 1361, Tustin, CA 92781, USA.
related software
Price listings are for courtesy purposes only and may be changed by the referenced businesses at any time without notice.
We are working on providing a second source.

Metrowerks CodeWarrior Discover Programming for Mac 5.0; C, C++, Java, and Pascal; PowerMac; $49.95
further reading: web sites
further reading: web sites: general
ProgramFiles.com — Programming — Assembly Language: a collection of assemblers, cross-assemblers, editors, debuggers, simulators, disassemblers, inspectors, shells, and other programs for assembly languages: 68000, 8085, MC68HC11, 80x86, 8748, and 8749
further reading: web sites: Motorola 680x0
Meet the 68000: Jack Powell’s May 1985 Digital Antic article introducing the 68000 as used in the Atari ST computers; although dated, still a valid introduction and overview of the 68000 processor
glossary of terms, symbols, and expressions: A. Clements’ gloassary of 68000 terms, symbols, and expressions
assembly language presentation: A. Clements’ presentation of the basics of 68000 assembly language programming with a simple programming example
Microprocessor Systems 1 (3D1) Notes: Michael Brady’s class notes on the basics of microprocessor systems using the 68000 as an example
Motorola M680x0 Macro Preprocessor: an SDSU student’s macro preprocessor for 680x0 assembly language
68000 Assembly Language Glossary: a UCI student’s guide to Motorola 680x0 terminology
further reading: web sites: other
Shopping for assembly language programming products; just a list of books
A web site on dozens of operating systems simply can’t be maintained by one person. This is a cooperative effort. If you spot an error in fact, grammar, syntax, or spelling, or a broken link, or have additional information, commentary, or constructive criticism, please e-mail Milo. If you have any extra copies of docs, manuals, or other materials that can assist in accuracy and completeness, please send them to Milo, PO Box 1361, Tustin, CA, USA, 92781.
Click here for our privacy policy.
home page
one level up
peer level
This web site handcrafted on Macintosh  computers using Tom Bender’s Tex-Edit Plus
computers using Tom Bender’s Tex-Edit Plus  and served using FreeBSD
and served using FreeBSD  .
.

Names and logos of various OSs are trademarks of their respective owners.
Copyright © 2000, 2001, 2002, 2004 Milo
Last Updated: March 31, 2004
Created: July 9, 2000