seabornによる統計データ可視化(ポケモン種族値を例に)(1) (original) (raw)
この広告は、90日以上更新していないブログに表示しています。
データの可視化をまとめて学んでおこうと思って書きました。
はじめに
データ分析はデータの可視化から
機械学習や統計分析をするに当たって、データの可視化は
- 対象のデータに対して洞察を深める
- 処理の結果を評価する
- 成果を分かりやすく他人に説明する
など、様々な局面で重要になります。
KaggleのKenel (分析/処理の過程をまとめたもの) をみても対象のデータに対する洞察を行う過程が全体の半分以上を占めていることが少なくありません。データを正しく可視化することは、データ分析や機械学習全般の土台にあたる作業です。
今回は、データの統計的可視化でよく使われるライブラリ "Seaborn" を用いてよく使う可視化パターンについてまとめてみます。
環境とデータ
実行環境にはKaglleのKernelを使いますが、オープンソースライブラリJupyterを使えばほぼおなじことが可能です。 また、ちょうど最近GoogleのG-Suiteで 公開されたColaboratory というツールでも同じように動くと思います。
また、データにはkaggleで公開されている
- Pokemon with Stats (https://www.kaggle.com/abcsds/pokemon)
を使います。
これはポケモンのステータスのデータセットです。今回の場合、データの洞察そのものが目的ではなく可視化方法の整理が目的なので、前処理無しで使えてできるだけ平易なデータを用いました。(あと、みんなもうアヤメの花びらの長さや幅は飽きてると思うので)
準備
必要となるライブラリの読み込みます。
- numpy: 行列式を扱うためのライブラリ
- pandas: csv形式のような表データを扱うためのライブラリ
- matplotlib: グラフを描画する基本となるライブラリ(seabornはmatplotlibのラッパーとして動作)
- seaborn: 今回のメインとなる統計データをグラフ化するライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
pkmn = pd.read_csv('../input/Pokemon.csv')
| | # | Name | Type 1 | Type 2 | Total | HP | Attack | Defense | Sp. Atk | Sp. Def | Speed | Generation | Legendary | | | ---- | ---- | --------------------- | ------ | ------ | --- | ------ | ------- | ------- | ------- | ----- | ---------- | --------- | ----- | | 0 | 1 | Bulbasaur | Grass | Poison | 318 | 45 | 49 | 49 | 65 | 65 | 45 | 1 | False | | 1 | 2 | Ivysaur | Grass | Poison | 405 | 60 | 62 | 63 | 80 | 80 | 60 | 1 | False | | 2 | 3 | Venusaur | Grass | Poison | 525 | 80 | 82 | 83 | 100 | 100 | 80 | 1 | False | | 3 | 3 | VenusaurMega Venusaur | Grass | Poison | 625 | 80 | 100 | 123 | 122 | 120 | 80 | 1 | False | | 4 | 4 | Charmander | Fire | NaN | 309 | 39 | 52 | 43 | 60 | 50 | 65 | 1 | False |
ID、名前、タイプ1、タイプ2、ステータス合計、HP、攻撃力、防御力、特攻、特防、素早さ、初登場世代、伝説のポケモンであるか否かという構成になってることがわかります。
以下、Seabornでデータを可視化していきます。
SeabornはMatplotlibのラッパーライブラリで、Matplotlibに比べて直感的にグラフを描くことができます。
上記を見ると、大まかに「〜Grid」というクラスと、「〜plot」というメソッドに分かれているのがわかると思います。 〜plotは変数やオプションを与えて簡易にグラフを描画することができます。さらにグラフを精密に作り込みたいときは〜Gridクラスを使って枠を作り、.plotメソッドでデータ描画していくという生のmatplotlibに近い使い方が出来るようになっています。
また、各メソッドは大まかな適用対象/目的ごとに大分類されているようです。 以下では、グラフ描画メソッドを大分類ごとに使っていきます。(説明の流れ上、Axis Gridは一番最後に回しています)
1. Categorical plots
対象のデータが二つの変数を持ち、片方がカテゴリ別でもう片方が連続値を持つ場合の描画に用います。(countplotを除く) 以下では、各世代(タイトルナンバリング))ごとにHPの分布を可視化していきます。
sns.set_style("whitegrid")
sns.set_palette("husl")
sns.set_context("notebook")
plt.figure(figsize=(15, 8))
ax = sns.stripplot(x=pkmn["Generation"], y =pkmn["HP"])
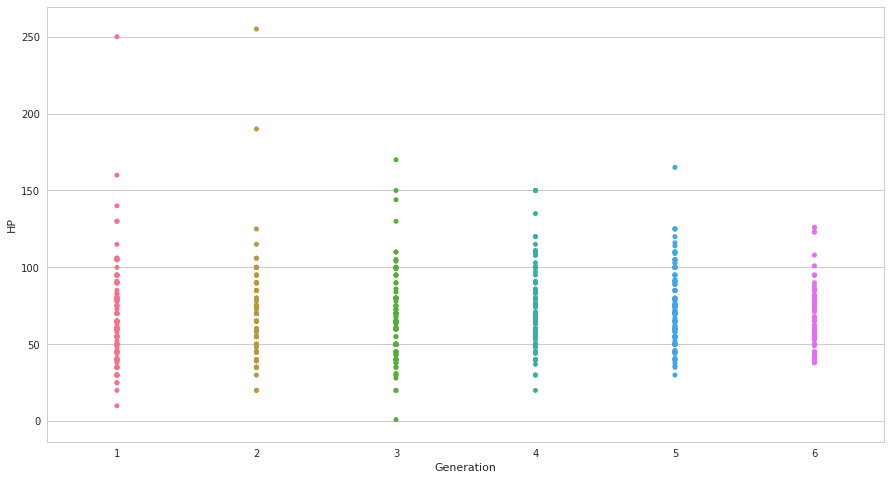
stripplotは素朴にstrip(細い端切れ)のように一直線上にデータをプロットします。
少数のサンプルに対して素朴なカテゴリごとのデータ分布を見るには良いですが、上でいう50 ~ 100の間など沢山の点が重なっている部分ではどのくらいの重なりがあるのか分かり辛いことが多いです。また、中央値等の所在も分かり辛いです。
これ単体で積極的に使うことは無いですが、他のグラフと組み合わせて使うことがあります。
第一世代と第二世代でHPが外れ値のように大きくなってるのは
| | # | Name | Type 1 | Type 2 | Total | HP | Attack | Defense | Sp. Atk | Sp. Def | Speed | Generation | Legendary | | | ---- | ---- | ------- | ------ | ----- | --- | ------ | ------- | ------- | ------- | ----- | ---------- | --------- | ----- | | 121 | 113 | Chansey | Normal | NaN | 450 | 250 | 5 | 5 | 35 | 105 | 50 | 1 | False | | 261 | 242 | Blissey | Normal | NaN | 540 | 255 | 10 | 10 | 75 | 135 | 55 | 2 | False |
ということでChansey(和名: ラッキー) とBlissey(和名: ハピナス)のようです。実際のデータ分析でも、このようにグラフから外れ値の有無/内容を確認していく作業は重要になります。
swarmplot
plt.figure(figsize=(15, 8))
ax = sns.swarmplot(x=pkmn["Generation"], y =pkmn["HP"])
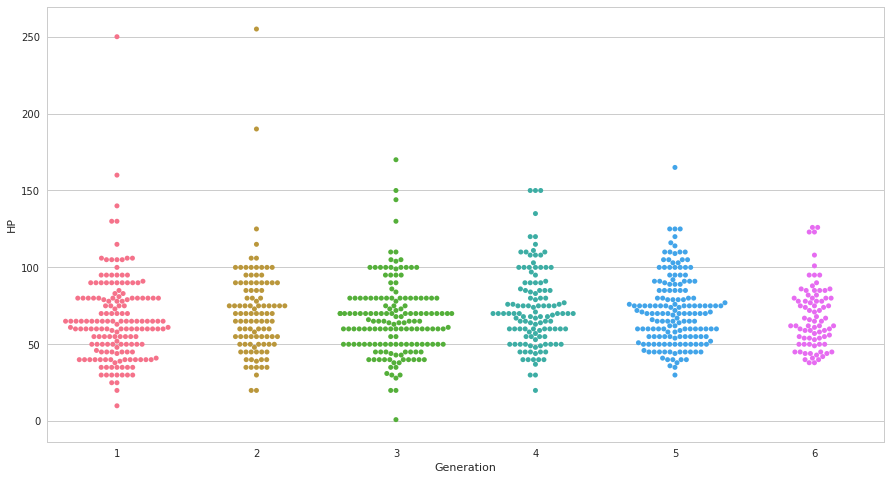
同じデータを可視化していきます。swarmplotはswarm(群れ)というだけあって、まるでバッファローの群れのようにパラメータの同じサンプルの分布具合が見て取れます。直感的に分布を見て取れるのが大きな利点です。
plt.figure(figsize=(15, 8))
ax = sns.boxplot(x=pkmn["Generation"], y =pkmn["HP"])
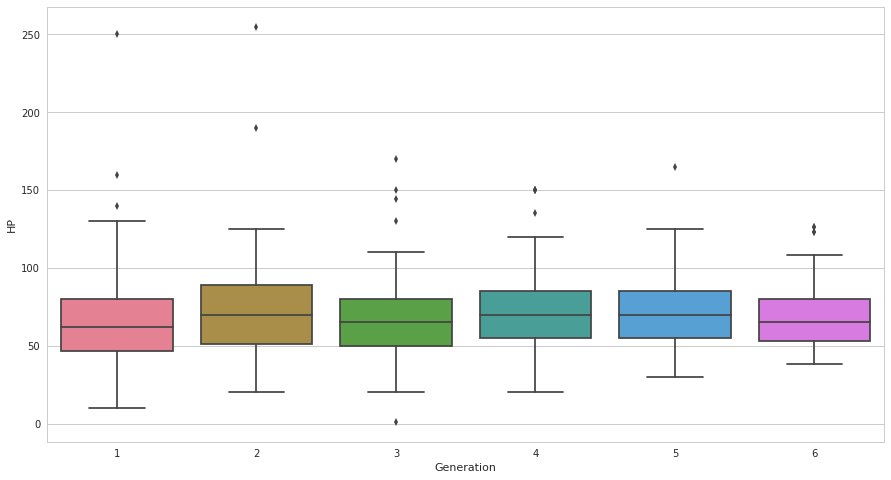
boxplotはswarmplotほど直感的ではないですが、重要な統計情報がまとまっています。

中心線は平均ではなく中央値です。
それぞれのカテゴリ毎の絶対数に興味がなく、分布の偏りに対する興味が強い場合に使うと良さそうです。
plt.figure(figsize=(15, 8))
ax = sns.violinplot(x=pkmn["Generation"], y =pkmn["HP"])
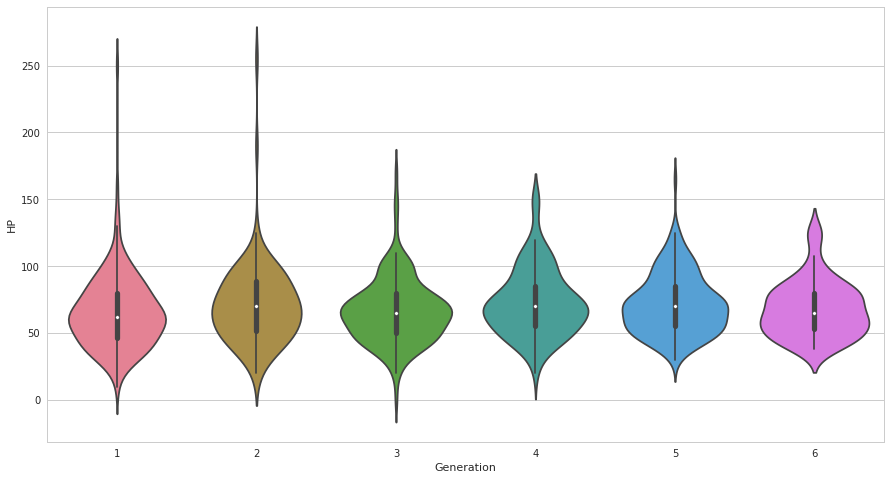
一見、変な形のグラフに見えますがよく見るとswarmplotの直感的な部分とboxplotの分布が定量的にが読みやすい長所を兼ね備えた優れたグラフです。名前の通りバイオリンのような形をしてます。
ただし、平滑化の過程で本来存在しない値のサンプルが存在するように見えてしまうことがあるので注意が必要です。 (例えば、[9,10,10,11,99,100,101]のような極端なデータを普通にviolinplotすると-50近辺までのサンプルが存在するかのようなグラフが描かれてしまいます)
また、Categorical plots全般ですが、hueパラメータに特定のフラグを与えることで、さらに系列を分割して比較することができます。
plt.figure(figsize=(15, 8))
ax = sns.violinplot(x=pkmn["Generation"], y =pkmn["HP"], hue=pkmn["Legendary"], split=True)
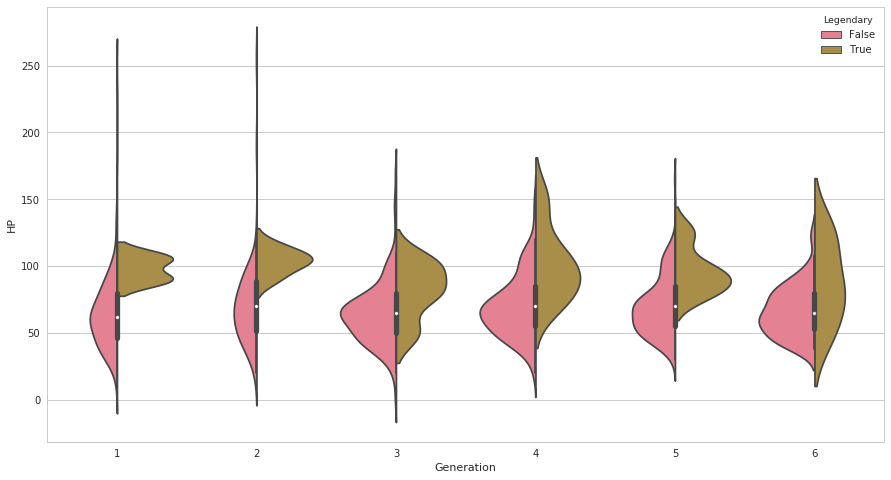
例として、普通のポケモンのHP分布(左側)と伝説のポケモンのHP分布(右側)を比べてみました。伝説のポケモンは基本的にHPが高く設定されているようです。
また、vionlinplotに限らずSeabornでは描くグラフは任意の他のグラフと同時に描画することができます。
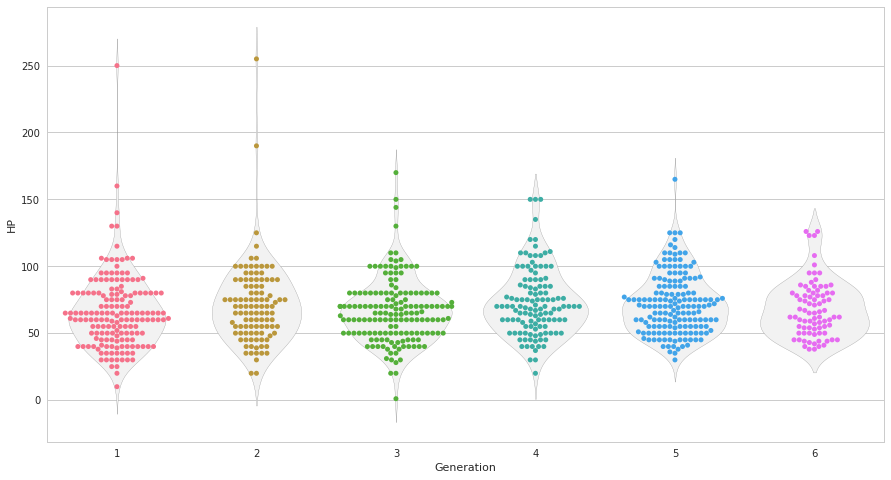
plt.figure(figsize=(15, 8))
ax = sns.violinplot(x=pkmn["Generation"], y =pkmn["HP"], inner=None, color="0.95", linewidth=0.3)
ax = sns.swarmplot(x=pkmn["Generation"], y =pkmn["HP"])
swarmplotとviolinplotを組み合わせました。見やすくするためにviolinplotの色や線の太さを調整しています。
lvplot
plt.figure(figsize=(15, 8))
ax = sns.lvplot(x=pkmn["Generation"], y =pkmn["HP"])
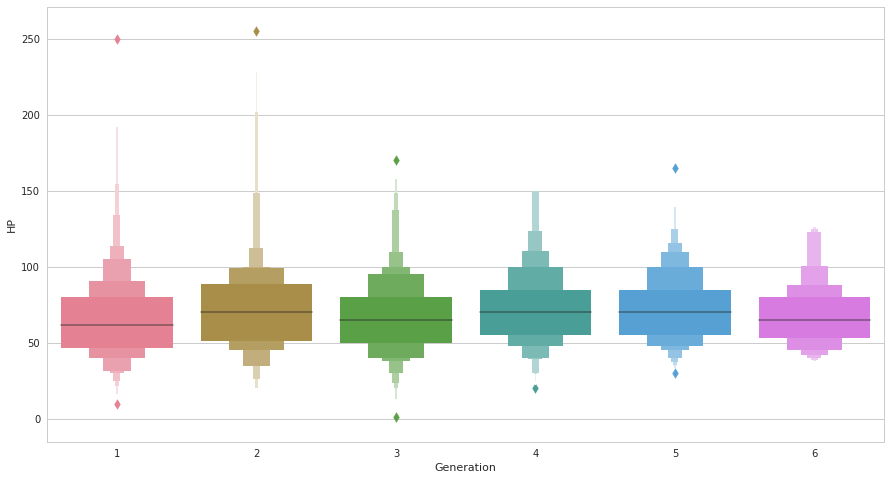
boxplotが比較的小規模なデータに対して手書きすることを前提に設計されており、大規模なデータセットに対して沢山の情報が抜け落ちてしまうという欠点を持っているのに対して、lvplotではより多くのletter value (要約値)を図に反映することができます。
実際、第3/1四分位数より上/下についても、細かに段階が付けられており大量のサンプルからなるデータの分布の特徴をboxplot以上に精密に読み取ることができます。
plt.figure(figsize=(15, 8))
ax = sns.pointplot(x=pkmn["Generation"], y =pkmn["HP"])

pointplotは極めてシンプルな図です。 点が打たれている箇所が平均値(mean)で、線が引かれているのが95%信頼区間です。 (boxplotやlvplotは中央値(median)と第x分位数です)
95%信頼区間の95という数字や平均値の求め方については引数により制御することができます。
このグラフは情報がシンプルなので、複数の系列を比較するのに向いています。 例えば、
plt.figure(figsize=(15, 8))
ax = sns.pointplot(x=pkmn["Generation"], y =pkmn["HP"], hue=( pkmn["Type 1"].isin(["Grass"]) | pkmn["Type 2"].isin(["Grass"])), dodge=True)
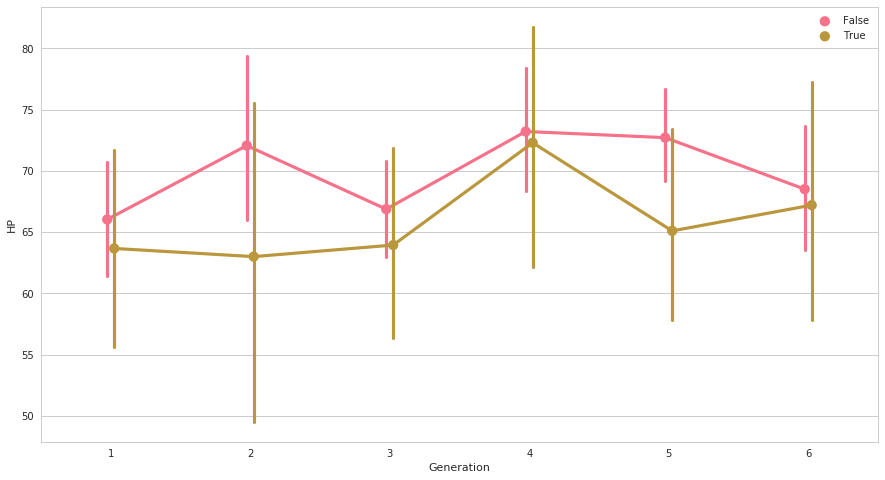
草タイプ以外(左)と草タイプ(右)のHPの分布を比較できました。シリーズ全般を通じて、草タイプのポケモンのHPの平均は低めという傾向が読み取れます。
平均や信頼区間を簡単に比較できるので、pointplotの系列比較はわりとよく使われている気がします。
plt.figure(figsize=(15, 8))
ax = sns.barplot(x=pkmn["Generation"], y =pkmn["HP"], capsize=.2)
barplotは文字通り棒グラフです。
棒グラフの値は各データの平均値で、縦線が信頼区間なので、可視化されている情報としてはpointplotと代わりありません。ただ、見ての通り0を起点として描かれるので値全体に占める信頼区間の大きさやカテゴリ毎の平均差異が全体のうちでどのくらいなのか、という部分はpointplotより見やすいかと思います。
(capsizeを指定すると信頼区間に横棒が生えます。見やすくなるのでオススメ)
このグラフももちろんhueを指定してさらに系列分割できます。
countplot
plt.figure(figsize=(15, 8))
ax = sns.countplot(x=pkmn["Generation"])
countplotはここまでのCategorical Plotと異なり、単純に指定されたカテゴリに含まれるデータがいくつあるかをカウントします。(yを代わりに指定することもできますが、横棒グラフになるだけです。xと同時には指定できません)
上記ではGenerationを指定したので、世代毎のデータ数(つまりポケモン数)が棒グラフになっています。 このプロットは下記のようにタイプ別の数え分けに使うことが多いと思います。
plt.figure(figsize=(15, 8))
ax = sns.countplot(x=pkmn["Generation"], hue=pkmn["Type 1"], palette="Set1" )
"Type 1" で分類してカウントしました。色は見分けが付きやすいパレットを選択しています。 (ポケモンは属性を二つ持つので、実際には"Type 2"も勘案する必要がありますがここでは気にしない)
2. Distribution plots
カテゴリラベルではなく何らかの数量であるデータ(1変数または2変数)を可視化するために用います。 APIリファレンスと順番が異なりますが、説明のわかりやすさのためkdeplot, rugplotを先に記載し、distplotを後に記載します。
kdeplot
plt.figure(figsize=(15, 8))
ax = sns.kdeplot(pkmn[pkmn["Legendary"]==False]["Total"])

変数列を1つ、または2つ受け取り、対象のデータを元にカーネル密度推定(KDE: Kernel Density Estimation)を行い、その結果をプロットします。(つまり、平たく言えば「変数の分布を確率分布に変換」します) 結果として確率密度関数が描かれることになるので、全体を積分した値は常に1となります。
ここでは伝説のポケモンを除くポケモンの、パラメータ値合計("Total")でplotしてみました。例えば、伝説でないポケモン全部から一体をランダムに選ぶと、このKDEで変換した確率密度関数で計算するとHP種族値が500ぴったりのポケモンを引く確率は約3.8%程度となります。
プロットの使い途としては、サンプルデータを確率密度関数に変換する時に分布の様子をみたり下記のようなパラメータを調整したりするために使うことが多いと思います。
KDEは以下のような式で算出される関数です。
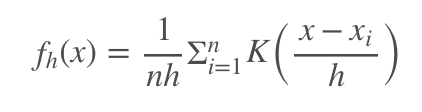
ただし、n: データ数, h: バンド幅, K: カーネル関数
バンド幅hhを小さい値にするほど分布の細かい特徴が反映されやすく、逆に大きくするほど平滑になります。(標準では自動的にバンド幅を選択するアルゴリズムが選択されています)
# バンド幅を10と指定した場合
plt.figure(figsize=(15, 8))
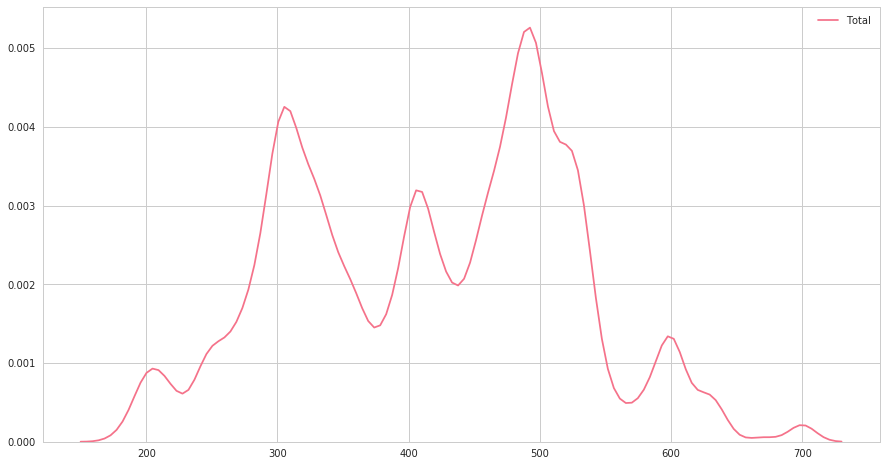
ax = sns.kdeplot(pkmn[pkmn["Legendary"]==False]["Total"], bw="10")
kdeplotでは、1変数ではなく2変数を指定することもできます。
plt.figure(figsize=(10, 10))
ax = sns.kdeplot(pkmn["Attack"], pkmn["Sp. Atk"], shade=True)
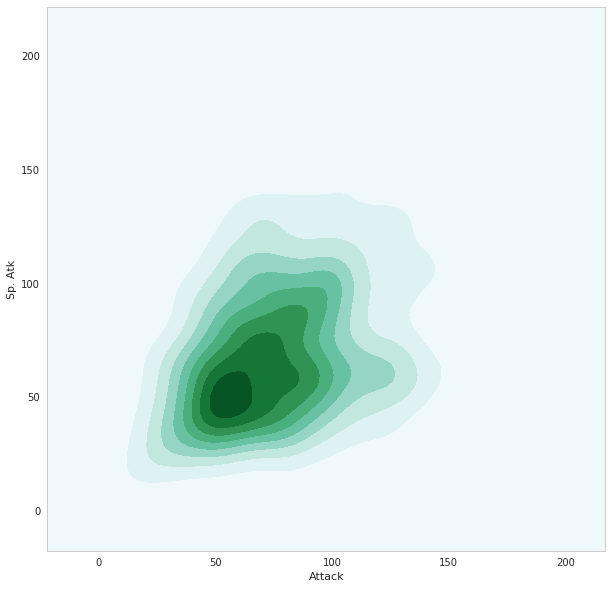
攻撃力と特殊攻撃力を2変数としてみました。色の濃い所が確率密度の高いところです。(shadeを指定しないと等高線表示になります)
この場合、値が大きい方に行くに従ってSpかAtkのどちらかに分かれていき(相関が弱くなっていき)、全体が三角形に近い形になっている様子を見て取ることができます。
plt.figure(figsize=(15, 8))
ax = sns.rugplot(pkmn[pkmn["Legendary"]==False]["Total"])
rugplotはカテゴリが一つしかないときのstripplotと同じようなもので、各データを単に一本一本の棒で描画していきます。
kdeの最初の例と同じく伝説以外のポケモンのステータス合計値をデータとしました。
rugplotは単体でつかうことはあまりないと思います。後述のdistplotなどと合わせて補助的にデータの分布を可視化するたに使うことが多いと思います。
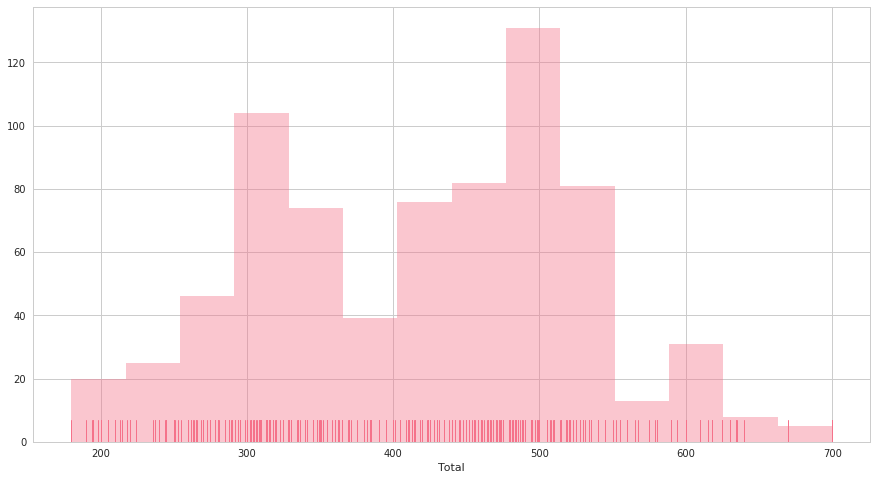
plt.figure(figsize=(15, 8))
ax = sns.distplot(pkmn[pkmn["Legendary"]==False]["Total"])

distplotは指定した1変数の分布を可視化します。ここでは伝説のポケモンを除くポケモンの、パラメータ値合計("Total")でplotしてみました。
distplotはごくシンプルに指定された変数のヒストグラムを描画し、合わせてkdeやrugを一緒に描画してくれます。 kdeやrug, ヒストグラムはそれぞれオプションでon / offできます。
plt.figure(figsize=(15, 8))
ax = sns.distplot(pkmn[pkmn["Legendary"]==False]["Total"], kde=False, rug=True)