Working of Lexical Analyzer in compiler (original) (raw)
Last Updated : 9 Jan, 2026
In the world of programming, a compiler is a tool that translates high-level code into machine-readable code. The first step in this process is handled by a component called the Lexical Analyzer.
A Lexical Analyzer, also known as a scanner, is responsible for reading the source code character by character and converting it into meaningful tokens. These tokens are then used by the next stage of the compiler for further processing.
For example, if we have the following line of code in C:
int num = 10;The **Lexical Analyzer breaks this into tokens such as:
int→ Keywordnum→ Identifier (variable name)=→ Operator10→ Numeric Constant;→ Special Symbol
By performing this conversion, the Lexical Analyzer helps simplify and structure the input for the next phase of compilation. It also removes whitespace, comments, and detects basic syntax errors such as invalid characters.
 **Types of token as following -
**Types of token as following -
- Identifier
- Keyword
- Operator
- Constants
- Special symbol(@, $, #)
Architecture of Lexical Analyzer
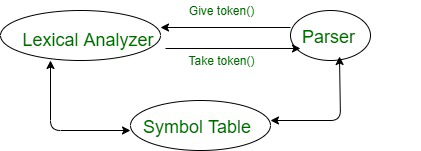
**Reading the Source Code: The lexical analyzer scans the entire source code and identifies different components like keywords, operators, variables, and symbols.
**Generating Tokens: Each identified component is converted into a token (a meaningful unit of code).
**Example: In int a = 5;, tokens generated are:
int→ Keyworda→ Identifier=→ Assignment Operator5→ Constant;→ Special Symbol
**Ignoring Extra Elements: The analyzer skips spaces and removes comments as they are not needed for execution.
Error Handling: If an invalid character or an unknown symbol is found, the analyzer reports errors along with the line number in the source file.
**Interaction with the Parser: The parser requests tokens from the lexical analyzer as needed. The lexical analyzer does not generate all tokens at once but provides them on request.
int main)(
}
x = y + z;
int x, y, z;
print("Goto GFG %d%d", a);
{
In the first phase, the compiler doesn't check the syntax. So, here this program as input to the lexical analyzer and convert it into the tokens. So, tokenization is one of the important functioning of lexical analyzer. The total number of token for this program is 26. Below given is the diagram of how it will count the token.  In this above diagram, you can check and count the number of tokens and can understand how tokenization works in lexical analyzer phase. This is how you can understand each phase in compiler with clarity and will get an idea of how compiler works internally and each phase of the compiler is the key step.
In this above diagram, you can check and count the number of tokens and can understand how tokenization works in lexical analyzer phase. This is how you can understand each phase in compiler with clarity and will get an idea of how compiler works internally and each phase of the compiler is the key step.
**Following are the some steps that how lexical analyzer work
**1. Input pre-processing: In this stage involves cleaning up, input takes and preparing lexical analysis this may include removing comments, white space and other non-input text from input text.
**2. Tokenization: This is a process of breaking the input text into sequence of a tokens.
**3. Token classification: Lexeme determines type of each token, it can be classified keyword, identifier, numbers, operators and separator.
**4. Token validation: Lexeme checks each token with valid according to rule of programming language.
**5. Output Generation: It is a final stage lexeme generate the outputs of the lexical analysis process, which is typically list of tokens.
Role of Lexical Analyzer
**Clean up the source code
Source code often contains extra characters that the compiler or interpreter doesn't need, like spaces, tabs, newlines, and comments. The lexical analyzer removes these to make the next stage of processing easier. Think of it like cleaning up your desk before starting a project.
**Keep track of errors
While cleaning up, the lexical analyzer might encounter invalid characters or sequences of characters that don't form a valid token. For example, it might find a character that's not allowed in the programming language. When this happens, it reports an error message and ideally pinpoints the location of the error in the original source code (e.g., line number and character position). This helps programmers find and fix mistakes.
**Figure out the basic building blocks (tokens)
This is the core job. The lexical analyzer scans the cleaned-up source code and groups characters together into meaningful units called _tokens. These tokens are the fundamental building blocks of the program. Examples of tokens include: The lexical analyzer doesn't understand the _meaning of these tokens; it just identifies what they are.
- **Keywords:
if,else,while,for,int,float, etc. (reserved words with special meanings) - **Identifiers: Variable names, function names, etc. (user-defined names)
- **Operators:
+,-,*,/,=,==,<,>, etc. (symbols that perform operations) - **Literals: Numbers (e.g.,
10,3.14), strings (e.g.,"hello"), boolean values (true,false), etc. (represent constant values) - **Punctuation:
;,,,(,),{,}, etc. (used for structure and grouping)
**Read the source code character by character
The lexical analyzer reads the source code one character at a time, grouping these characters into tokens. It's like reading a sentence word by word, but at a more fundamental level – character by character to form the words (tokens). This character-by-character reading allows it to recognize even complex tokens.