Data analysis using R (original) (raw)
Last Updated : 29 Apr, 2026
Data analysis is the process of examining and interpreting data to extract meaningful insights that can guide decision-making. Using R, a statistical programming language, makes this process efficient and reproducible.
- Collect, clean and transform raw data into structured formats suitable for analysis.
- Explore patterns, relationships and trends using statistical and graphical methods in R.
- Visualize results effectively to communicate findings and support data-driven decisions.
Data Analysis
Importance of Data Analysis
Data analysis helps convert raw data into meaningful information that can support better understanding and decision-making. It allows individuals and organizations to examine data carefully and draw logical conclusions based on facts.
- **Improves Decision-Making: Provides clear information that supports better decisions based on facts instead of guessing.
- **Identifies Trends and Patterns: Shows common patterns or changes in data, such as which product sells more or when sales increase.
- **Improves Efficiency: Finds better ways to complete tasks and reduces time, cost and errors.
- **Supports Problem Solving: Identifies the cause of problems and suggests suitable solutions.
- **Enables Future Prediction: Uses past data to estimate what may happen in the future, such as predicting upcoming sales.
Steps for Data Analysis
Data analysis in R follows a structured approach to transform raw data into meaningful insights. Each step plays an important role in ensuring accurate and reliable results.

Steps of Data Analysis
1. Define the Problem Statement
The first step is to clearly identify the objective of the analysis. A well-defined problem helps determine what data is needed and what type of analysis should be performed.
- Identify the main question or objective.
- Determine the scope and expected outcome of the analysis.
- Decide the type of data and methods required.
2. Data Collection
After defining the problem, relevant data must be gathered from appropriate sources. Only data related to the objective should be collected.
- Import data from CSV, Excel, databases or online sources in R.
- Ensure the data is accurate and relevant to the problem.
- Organize the dataset properly for further processing.
3. Data Inspection
Before cleaning, it is important to understand the structure and content of the dataset. This helps identify potential issues.
- View sample records using head() or tail().
- Check structure and data types using str().
- Generate summary statistics using summary().
4. Data Preprocessing
Raw data often contains missing values, duplicates or inconsistencies. Preprocessing prepares the data for accurate analysis.
- Handle missing values and remove duplicates.
- Detect and manage outliers or incorrect entries.
- Convert variables into appropriate data types.
5. Exploratory Data Analysis (EDA)
After cleaning the data, analysis can begin to uncover patterns, trends and relationships. This step helps to understand the dataset and extract meaningful insights.
- Perform exploratory data analysis (EDA) using charts, plots and graphs to visualize patterns.
- Calculate descriptive statistics such as mean, median, mode, standard deviation and variance.
- Apply statistical tests or models to explore relationships and support conclusions.
6. Data Visualization
Visualization helps present findings in a clear and understandable manner. Graphs make patterns and trends easier to interpret.
- Create bar charts, histograms or scatter plots.
- Use visualization packages like ggplot2.
- Highlight key insights through graphical representation.
7. Interpretation and Reporting
The final step is to interpret the results and communicate findings effectively. Clear reporting supports informed decision-making.
- Summarize key findings and insights.
- Draw conclusions based on the analysis.
- Present results through reports, dashboards or presentations.
Performing Data Analysis Using Titanic Dataset
Here we will explore a real-world example of data analysis using the Titanic dataset. The Titanic dataset contains information about passengers aboard the RMS Titanic, including whether they survived, their age, gender, ticket class and more.
You can download the dataset from here.
Step 1: Importing the Dataset
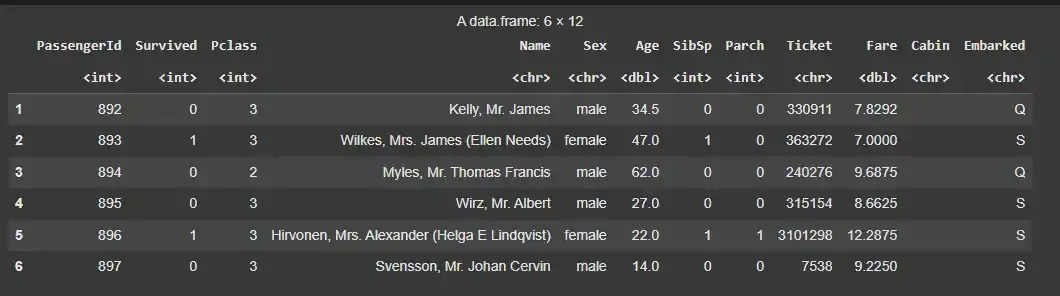
We will load the dataset into R. We will use the read.csv() function to load the dataset and examine the first few rows of the data.
R `
titanic = read.csv("train.csv") head(titanic)
`
**Output:
Dataset
Step 2: Checking Data Types
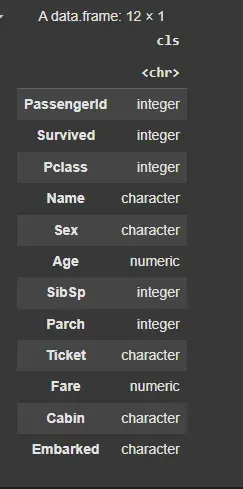
Next, we can check the class (data type) of each column using the sapply() function. This will help us understand how each column is represented in R.
R `
cls <- sapply(titanic, class) cls <- as.data.frame(cls) cls
`
**Output:
Data Types
Step 3: Converting Categorical Data
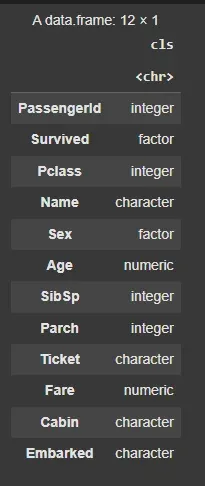
Columns like Survived and Sex are categorical, so we can convert them to factors for better analysis.
R `
titanic$Survived = factor(titanic$Survived, levels = c(0,1), labels = c("Not Survived", "Survived")) titanic$Sex = as.factor(titanic$Sex)
cls <- sapply(titanic, class) cls <- as.data.frame(cls) cls
`
**Output:
Converting Categorical Data
Step 4: Summary Statistics
To get an overview of the data, we can use the summary() function. This will provide key statistics for each column, such as the minimum, maximum, mean and median values.
R `
summary(titanic)
`
**Output:
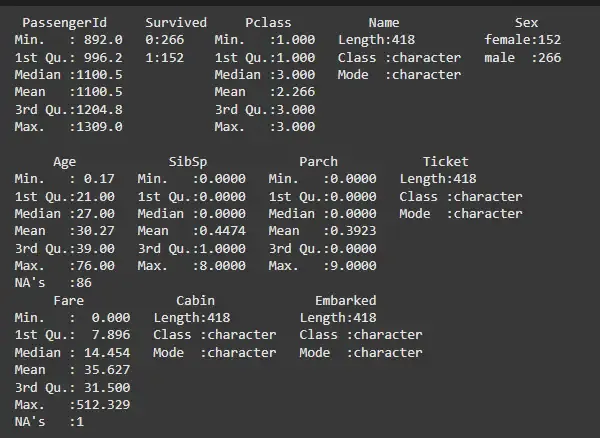
Summary Statistics
Step 5: Handling Missing Values
The dataset contains missing values (NA). To identify how many missing values are present, we can use the following code:
R `
sum(is.na(titanic))
`
**Output:
87
This indicates that there are 87 missing values in the dataset. We can either remove the rows containing missing values or fill them with the mean (for numerical columns) or mode (for categorical columns).
R `
dropnull_titanic = titanic[rowSums(is.na(titanic)) <= 0, ]
`
This will remove the rows with missing values, leaving us with a cleaner dataset.
Step 6: Analyzing Survival Rate
Here we divide the data into two groups, those who survived and those who did not.
R `
survivedlist = dropnull_titanic[dropnull_titanic$Survived == "Survived", ] notsurvivedlist = dropnull_titanic[dropnull_titanic$Survived == "Not Survived", ]
`
We can now analyze the number of survivors and non-survivors using a pie chart:
R `
mytable = table(dropnull_titanic$Survived)
lbls = paste(names(mytable), "\n", mytable, sep="")
pie(mytable, labels = lbls, main = "Pie Chart of Survived Column Data (with sample sizes)")
`
**Output:
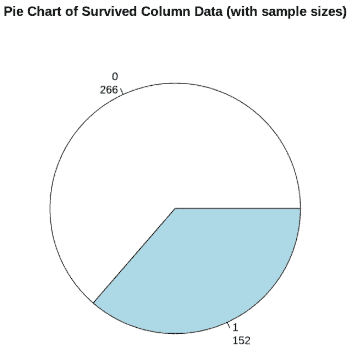
Survival Rate
This pie chart will show the distribution of survivors versus non-survivors, highlighting the imbalance in the dataset.
Step 7: Visualizing Age Distribution of Survivors
We can also visualize the age distribution of the survivors:
R `
hist(survivedlist$Age, xlab = "Age", ylab = "Frequency", main = "Age Distribution of Survivors")
`
**Output:
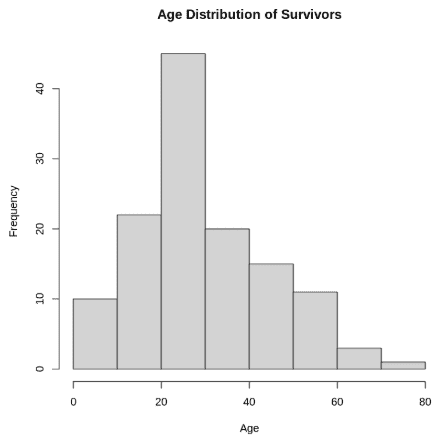
Age Distribution of Survivors
Step 8: Analyzing Gender Distribution
We can use a bar plot to analyze the distribution of survivors and non-survivors based on gender. This plot will help us understand the number of males and females who survived or did not survive, giving us insights into how gender might have influenced survival on the Titanic.
R `
barplot(table(notsurvivedlist$Sex), xlab = "Gender", ylab = "Frequency", main = "Gender Distribution of Non-Survivors")
`
**Output:
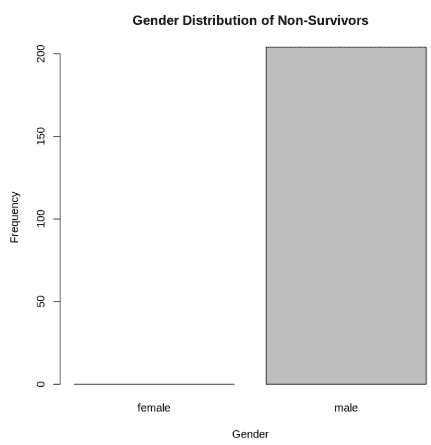
Analyzing Gender Distribution
Step 9: Analysis Class vs Survived
We can use a bar plot to analyze the distribution of survivors and non-survivors based on class. This plot will help us understand the number of passengers who survived or did not survive, giving us insights into how class might have influenced survival on the Titanic.
R `
install.packages("ggplot2") library(ggplot2)
ggplot(dropnull_titanic, aes(x = factor(Pclass), fill = Survived)) + geom_bar(position = "dodge") + labs(title = "Pclass vs Survived", x = "Pclass (1 = First, 2 = Second, 3 = Third)", y = "Count") + scale_fill_manual(values = c("red", "green"), labels = c("Not Survived", "Survived")) + theme_minimal() + theme(legend.title = element_blank())
`
**Output:
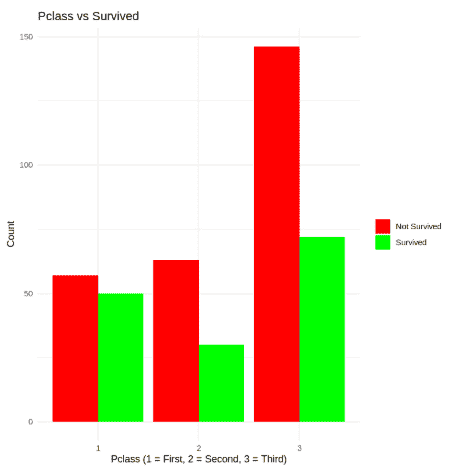
Class vs Survived
From our analysis, we can conclude that:
- **Age: Younger passengers had a better chance of survival.
- **Survival Rate: Females had a higher survival rate than males.
- **Class and Fare: First-class passengers had a higher survival rate, with some extreme fare outliers.
Applications
- **Business Intelligence: Studies sales data, customer behavior and daily operations to improve business strategies.
- **Healthcare: Examines patient records to understand treatment results and support medical studies.
- **Finance: Analyzes financial data to detect fraud, measure risk and support investment decisions.
- **Marketing: Reviews customer preferences and campaign results to improve marketing plans.
- **Scientific Research: Analyzes experimental data to discover new findings and support innovation.
Limitations
- **Data Quality Issues: Incorrect or incomplete data can produce wrong results.
- **Time and Resource Intensive: Collecting, cleaning and analyzing data requires time, effort and technical knowledge.
- **Bias Risk: If the data or method is biased, the conclusions may not be reliable.
- **Over-Reliance on Tools: Using tools without proper understanding can lead to incorrect interpretation.
- **Limited Context: Data may not fully explain human behavior or real-world situations.