Difference Between FeedForward Neural Networks and Recurrent Neural Networks (original) (raw)
Last Updated : 1 Aug, 2025
Neural networks have become essential tools in solving complex machine learning tasks. Among them most widely used architectures are Feed-Forward Neural Networks (FNNs) and Recurrent Neural Networks (RNNs). While both are capable of learning patterns from data, they are structurally and functionally different.
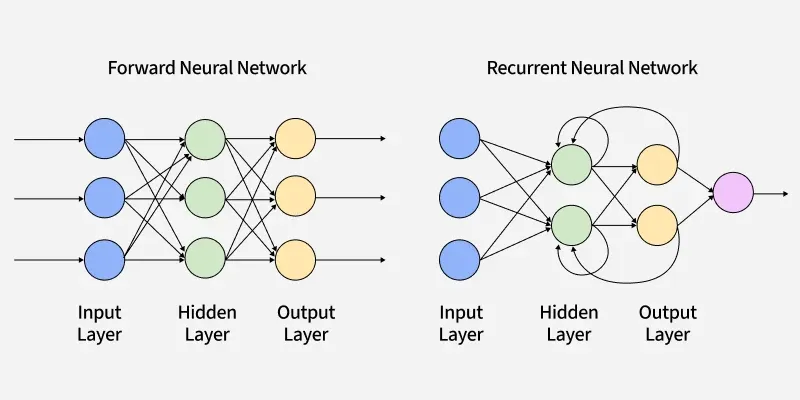
FNN vs RNN Architecture
Feed-Forward Neural Networks
Feed-forward neural networks is a type of neural network where the connections between nodes do not form cycles. It processes input data in one direction i.e from input to output, without any feedback loops.
- No memory of previous inputs.
- Best suited for static data (e.g., images).
- Simple and fast to train.
- Cannot handle sequences or time dependencies.
Basic Example:
Used in classification tasks like identifying handwritten digits using the MNIST dataset.
Recurrent Neural Networks
Recurrent neural networks add a missing element from feed-forward networks i.e memory. They can remember information from previous steps, making them ideal for sequential data where context matters.
- Has memory of previous inputs using hidden states.
- Ideal for sequential data like text, speech, time series.
- Can suffer from vanishing gradient problems.
- More complex and slower to train.
Basic Example:
Used in language modeling such as predicting the next word in a sentence.
Key Differences
| Feature | Feed-Forward Neural Network (FNN) | Recurrent Neural Network (RNN) |
|---|---|---|
| Data Flow | One-way (input → output) | Cyclic (can loop over previous states) |
| Memory | No memory | Has memory via hidden states |
| Best For | Static input (images, tabular data) | Sequential input (text, audio, time series) |
| Complexity | Lower | Higher |
| Training Time | Faster | Slower due to time dependencies |
| Gradient Issues | Less prone | Can suffer from vanishing/exploding gradients |
| Example Use Cases | Image classification, object detection | Sentiment analysis, speech recognition |
When to Use Each Architecture
**Feed-Forward Networks are ideal for:
- Image classification where each image is independent
- Medical diagnosis where patient symptoms don't depend on previous patients
- Credit scoring as current application doesn't depend on previous applications
- Any problem where inputs are independent
**RNNs are ideal for:
- Language translation where word order matters
- Stock price prediction as today's price depends on yesterday's
- Weather forecasting as tomorrow's weather depends on today's
- Speech recognition
Computational Considerations
**Feed-Forward Networks
- **Simple Structure: Feed-forward networks follow a straight path from input to output. This makes them easier to implement and tune.
- **Parallel Computation: Inputs can be processed in batches, enabling fast training using modern hardware.
- **Efficient Backpropagation: They use standard backpropagation which is stable and well-supported across frameworks.
- **Lower Resource Use: No memory of past inputs means less overhead during training and inference.
**Recurrent Neural Networks
- **Sequential Nature: RNNs process data step-by-step, this limits parallelism and slows down training.
- **Harder to Train: Training uses Backpropagation Through Time (BPTT) which can be unstable and slower.
- **Captures Temporal Patterns: They are suited for sequential data but require careful tuning to learn long-term dependencies.
- **Higher Compute Demand: Maintaining hidden states and learning over time steps makes RNNs more resource-intensive.
Limitations and Challenges
| Limitation | Feed-Forward Neural Network | Recurrent Neural Network (RNN) |
|---|---|---|
| **Input Handling | Cannot handle variable-length input sequences | Supports sequences but struggles with long ones |
| **Memory | No memory of previous inputs | Limited memory; forgets long-term context |
| **Temporal Modeling | Ineffective at capturing time-based patterns | Can model temporal patterns but with difficulty |
| **Performance Issues | Good parallelism, but lacks temporal context | Sequential nature slows training and inference |
| **Training Challenges | Relatively stable | Prone to vanishing gradient and unstable training |
Both architectures are fundamental building blocks in modern deep learning, often combined in approaches to use their respective strengths. Using these basics provides a solid foundation for exploring more advanced neural network architectures translation, speech-to-text conversion and robotic control.