What is a Data Lakehouse ? (original) (raw)
Last Updated : 23 Jul, 2025
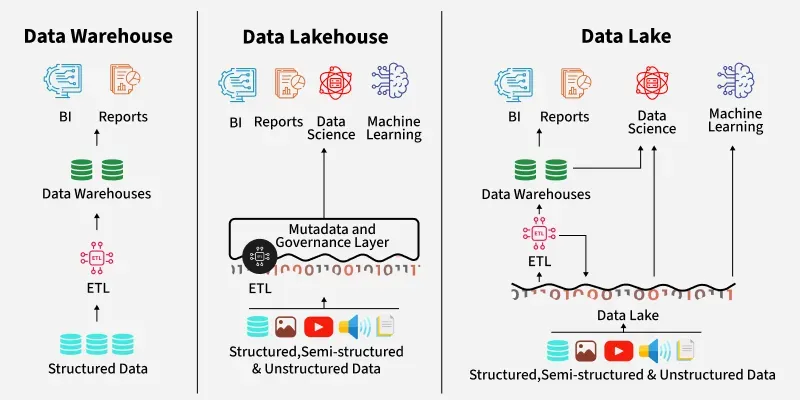
As Data continues to grow across industries, organizations are constantly in search of efficient, scalable and cost-effective solutions for managing and analyzing their data. Traditionally, enterprises have relied on two primary data architectures: **data warehouses, which offer structure and high-performance analytics but are often expensive and hard and **data lakes, which provide scalable, low-cost storage for all types of data but lack reliability and performance for analytics.
Data Lakehouse , Warehouse and Lakes
**Data lakehouse emerges as a hybrid approach that blends the best aspects of both, offering the flexibility and scalability of data lakes along with the reliability, performance, and management features of data warehouses.
The Evolution of Data Architectures
Let us look at how data architectures have evolved.
- **Data Warehouses were designed for structured data and business intelligence. They support SQL-based queries, ensure data integrity through ACID (Atomicity, Consistency, Isolation, Durability) transactions. They offer mature governance and security. However, warehouses can be inflexible when dealing with semi-structured or unstructured data like images or logs data.
- **Data Lakes are built on low-cost cloud object storage (like AWS S3) and can store data in its raw form. They allow data scientists and analysts to apply structure as needed. While this flexibility is valuable, data lakes typically lack built-in data management, reliability and optimized query engines which can lead to data quality issues and slower analytics.
As businesses began using both warehouses and lakes, problems like data duplication, latency and increased costs emerged. The lakehouse architecture was born to address these limitations by combining structured management with flexible storage.
**Data Lakehouse - The solution
A data lakehouse is a unified data platform that provides:
- Low-cost and scalable storage like a data lake
- ACID transaction support and schema enforcement like a warehouse
- Support for multiple data types (structured, semi-structured, unstructured)
- Compatibility with both SQL and machine learning workloads
It allows businesses to perform **real-time analytics, business intelligence (BI) and advanced analytics on the same data without moving it between disparate systems.
Lakehouse Architecture: A Layered Breakdown
The **data lakehouse architecture is composed of six distinct layers, each responsible for a key part of the data lifecycle from ingestion to consumption.
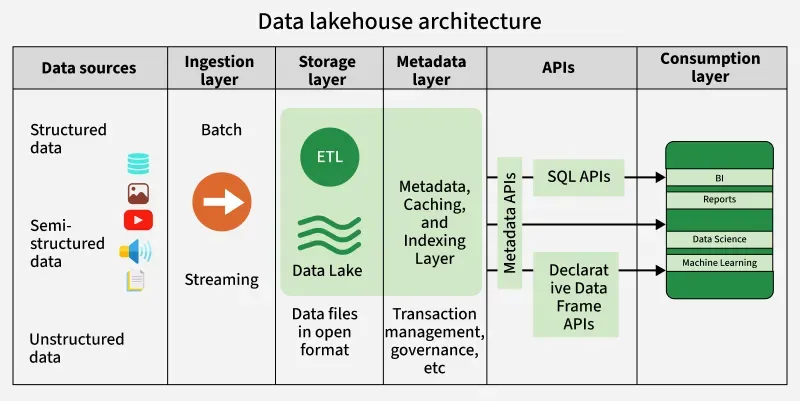
Lakehouse architecture
1. **Data Sources
The system ingests diverse types of data:
- **Structured data (databases and CSVs)
- **Semi-structured data (JSON, images and audio)
- **Unstructured data (documents, videos, logs)
This variety enables the lakehouse to support a wide range of analytical and operational use cases.
2. **Ingestion Layer
Data flows into the system via both**batch and streaming pipelines.Technologies like Apache Kafka or cloud-native tools feed real-time or scheduled data into the lakehouse. The ingestion process ensures raw data lands in the storage layer efficiently and reliably.
3. **Storage Layer
The storage foundation is a **data lake that holds raw and processed data in open formats. ETL (Extract, Transform, Load) processes clean and organize this data for downstream use. This layer provides the flexibility and cost efficiency typical of cloud object stores like Amazon S3, Azure Data Lake Storage or Google Cloud Storage.
4. **Metadata Layer
This important layer adds structure and management to the raw data. It includes:
- Metadata catalogs for table definitions
- Indexing and caching for performance optimization
- Transaction management for ACID guarantees
Governance, auditing and schema enforcement are also handled here using engines like Delta Lake or Apache Iceberg.
5. **APIs
To access and process data, the lakehouse exposes two types of APIs:
- **SQL APIs for business intelligence, reporting, and ad-hoc analysis
- **Declarative DataFrame APIs for data engineering and machine learning workflows (e.g., PySpark, Pandas-like interfaces)
These APIs interact with the metadata layer to ensure consistent, governed data access.
6. **Consumption Layer
This is where insights are extracted and delivered. The same underlying data supports various consumer needs:
- **Business Intelligence (BI) dashboards
- **Reports for operational metrics
- **Data Science experiments and prototyping
- **Machine Learning model training and inference
By enabling all these use cases from a single platform, the lakehouse reduces redundancy and latency in data workflows.
Core Principles and Features
1. **Unified Storage Layer: Lakehouses are typically built on top of cloud object storage (S3, Azure Data Lake Storage, Google Cloud Storage). This base layer allows for massive scalability and lower costs while remaining unbiased.
2. **Transaction Support (ACID): They implement transactional capabilities via storage engines like Delta Lake, Apache Iceberg or Apache Hudi. These systems track metadata and maintain data consistency, which is crucial for concurrent reads and writes, time travel and rollback operations.
3. **Schema Evolution: Lakehouses enforce schemas at write time to maintain data quality and allow evolution over time. For example, if a new column is added to a dataset, the engine can adapt without breaking existing queries or pipelines.
4. **Decoupled Compute and Storage: Compute engines (Apache Spark, Trino, Databricks SQL) operate independently of the storage layer. This separation enhances scalability and cost-efficiency, enabling users to scale compute resources based on specific workloads.
5. **Unified Metadata and Governance: Data cataloging, access control, lineage tracking, and data quality checks are integrated across the system. Unified metadata layers allow different teams (BI analysts, data engineers, and ML practitioners) to collaborate seamlessly.
6. **Support for Diverse Workloads: Lakehouses serve both **batch and streaming pipelines and support **SQL-based analytics as well as **machine learning workflows making them highly versatile for modern data applications.
Key Technologies used in Lakehouse
A data lakehouse is not a single product but a mix of technologies. Several open-source and commercial tools work together to deliver its capabilities:
- **Delta Lake (by Databricks): Provides ACID transactions, schema enforcement and time travel atop Spark and cloud storage. It’s one of the first engines purpose-built for lakehouses.
- **Apache Iceberg: A table format designed for large-scale analytics. It enables SQL-based access, versioned snapshots and schema evolution without compromising performance.
- **Apache Hudi: Optimized for streaming data ingestion and real-time data updates. It supports incremental data pipelines, making it ideal for fast-changing datasets.
- **Databricks Lakehouse Platform: A fully managed offering that combines storage, compute, metadata and governance with native integrations for Spark, Delta Lake, and MLflow.
- **Microsoft Fabric Lakehouse: Integrates a native lakehouse into the Microsoft analytics stack, seamlessly connecting with Power BI, Synapse and Azure Data Lake services.
These technologies ensure that a lakehouse can scale flexibly, operate reliably, and support diverse workloads while maintaining openness and interoperability.
Lakehouse vs Data Lake vs Data Warehouse
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| Storage Cost | Low | High | Low |
| Data Types | All (raw) | Mostly structured | All |
| Query Speed | Low | High | High |
| ACID Transactions | No | Yes | Yes |
| ML Workload Support | Yes | Limited | Yes |
| Governance | Basic | Strong | Strong |
| Use Cases | Data science, archiving | BI, reporting | BI + Data Science + Streaming |
The lakehouse thus emerges as a **middle ground, combining the agility of data lakes with the reliability and performance of data warehouses.