Bayesian Inference (original) (raw)
Last Updated : 21 Jun, 2025
Bayesian inference is a method of statistical inference in which Bayes' Theorem is applied to update the probability for a hypothesis as more evidence or information becomes available. It is widely used due to its ability to handle uncertainty, complex model systems and it can make predictions based on prior knowledge and observed data.
Bayesian inference is a way to draw conclusions from data using probability. Unlike traditional methods that focus on fixed data to estimate parameters, Bayesian inference allows us to bring in prior knowledge and then update it as we gather new data. This makes Bayesian inference valuable when we are dealing with uncertainty or incomplete information as it lets us adjust our understanding based on what we learn over time.
Bayes' Theorem is the foundation of Bayesian inference and it can be written as:
P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}
Where,
- P(A|B) is the posterior probability, the probability of the hypothesis A given the data B .
- P(B|A) is the likelihood, the probability of observing the data B given the hypothesis A.
- P(A) is the prior probability, the initial belief about the hypothesis before seeing the data.
- P(B) is the marginal likelihood, the probability of observing the data under all possible hypotheses.
Lets see the Bayesian updating visually,

Visual representation of Bayesian Updating
In the above graphical representation,
- **Prior Belief (Green Curve): This represents the initial understanding or assumptions before, seeing any new data. It is based on previous knowledge.
- **Evidence (Brown Curve): This the data we collect from experiments or real-world interactions and this act as the new information we want to incorporate.
- **Posterior Beliefs (Blue Curve): After considering the new evidence, the prior is updated to form posterior distribution which is a redefined belief that more accurately represents the state of knowledge.
Key Components of Bayesian Inference
- **Prior Probability (P(A)):The prior probability represents our beliefs or knowledge about a parameter before observing the data. For example, if we know that a coin is likely to be fair, we might assign a prior probability close to 0.5 to the hypothesis that the coin is fair.
- **Likelihood (P(B|A)): Likelihood reflects the probability of observing the data given a particular hypothesis. It is calculated based on the model or experiment that generates the data.
- **Posterior Probability (P(A|B)): The posterior probability is the updated probability of the hypothesis after observing the data. Bayesian inference updates this probability, which becomes the new belief based on both prior knowledge and new evidence.
- **Evidence(P(B)): The evidence represents the total probability of observing the data across all potential hypotheses. It serves to normalize the results, ensuring that the posterior probability sums to 1.
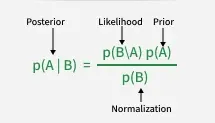
Annotated Breakdown of Bayes' Theorem
Features of Bayesian Inference
- **Handling Uncertainty: Bayesian inference helps incorporate uncertainty into prediction. As more data becomes available, we can update our beliefs about model parameters, improving the accuracy of future predictions.
- Prior Knowledge Integration: Bayesian inference is especially useful in cases where data is limited or hard to obtain. By incorporating prior knowledge, we can refine predictions and update them as new data is collected.
- **Probabilistic Modelling: Bayesian methods adopt a probabilistic approach to model's uncertainty. This is crucial for understanding complex systems and making predictions with a level of confidence, often represented in the form of confidence intervals.
- **Regularization: Bayesian inference naturally performs regularization through the use of priors which help in limiting the hypothesis space while still considering observed data.
Applications of Bayesian Inference
Lets see the applications of Bayesian Inference,
**1. Bayesian Linear Regression: Traditional linear regression estimate fixed parameters based on training data whereas the Bayesian linear regression gives us a probability distribution over possible parameter values which allows us to account for uncertainty in predictions. In the equation, we model the posterior of the coefficient \beta as:
P(\beta | X, y) = \frac{P(y | X, \beta) \cdot P(\beta)}{P(y | X)}
Where P(y | X, \beta) is the likelihood of the data, P(\beta) is the prior over the coefficients, and P(y | X) is the evidence.
**2. Bayesian Networks: These are the models that show how variables are related to each other with probabilities. They are useful for tasks like classification and clustering in machine learning.
**3. Naive Bayes Classifier: The Naive Bayes classifier is a simple but effective algorithm that works well for text classification tasks such as spam filtering and sentiment analysis. In the equation the likelihood for class C is calculated as:
P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)}
Where P(X|C) is the likelihood of the features X given the class C, and P(C) is the prior probability of class C.
**4. Markov Chain Monte Carlo: MCMC method helps us sample from complex probability distributions that are difficult to calculate directly.
Differences between Bayesian Inference and Frequential Approach
| Aspect | Bayesian Inference | Frequentist Approach |
|---|---|---|
| Prior Knowledge | Incorporates prior knowledge about the hypothesis and updates it as new data is collected. | Does not use prior knowledge, focus only on the data available. |
| Use of Data | Data and prior beliefs are used together. | Data alone is used to make inferences. |
| Hypothesis Testing | Uses posterior probability to test hypotheses. | Uses p-values and hypothesis tests. |
| Interpretation | Provides probabilistic estimates of hypotheses. | Provides confidence intervals and point estimates. |
| Computation | More intensive because of the need to update prior beliefs and compute posterior | Less computationally demanding as if focuses on sample data and parameter estimation. |
Advantages of Bayesian Inference
- **Flexibility: Bayesian models can adjust to new data over time, making them ideal for situations where data keeps changing or evolving.
- **Interpretability: Bayesian models provide clear probabilistic(like confidence intervals) estimates which helps in understanding band trusting the predictions.
- **Data Efficiency: Bayesian methods can perform well even when data is limited by prior knowledge to fill in the gaps which makes them efficient in data-scarce situations.
Challenges of Bayesian Inference
- **Computational Complexity: In some Bayesian methods can be computationally expensive in cases that are involved in MCMC or complex prior or have large datasets.
- **Choosing Priors: Results of a Bayesian model depends heavily on the prior knowledge we use and choosing the right prior can be tricky when we don't have much domain-specific information.
- **Scalability: Computing the posterior distributions can become more time-consuming as the datasets grows and this makes is challenging to make the models works efficiently on larger datasets.