Human evaluation strategies (original) (raw)
Last Updated : 9 May, 2026
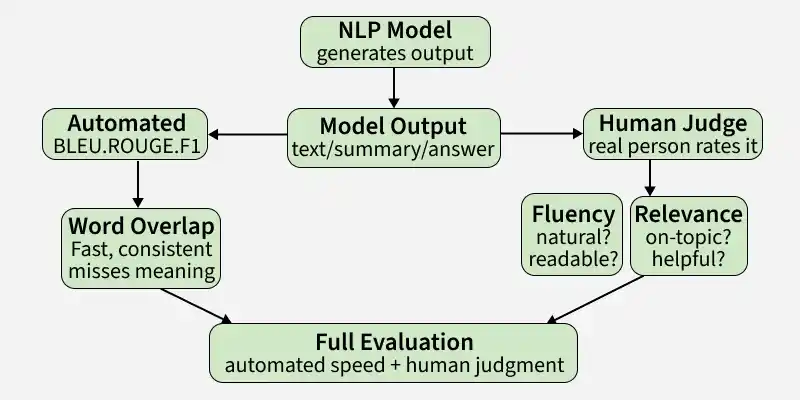
Human evaluation is the process by which people judge the quality of NLP model outputs. Unlike automated metrics, it captures qualities that are difficult to measure programmatically such as fluency, coherence and overall helpfulness.
Human Evaluation Strategies
- Judges assess outputs based on criteria like naturalness, relevance and factual accuracy
- Valuable for open-ended tasks like text generation, summarisation and dialogue
- Results reflect how an actual user would experience the model's output
Need for Human Evaluation
Automated metrics are fast and consistent, but they only measure surface level patterns not actual quality. They often miss what truly matters in a model's output.
- BLEU and ROUGE measure word overlap, so a correct paraphrase can still score very low
- Perplexity measures model confidence, not whether the output is useful or meaningful
- F1 and Accuracy work well for classification but break down on open ended, generative outputs
Types of Human Evaluation
1. Direct Assessment
Annotators rate a model output on a numeric scale (e.g. 1 to 5) for a specific quality.
- Simple to set up and widely used
- Works well for summarization, translation and dialogue
- Can be subjective different annotators may score the same output differently
2. Pairwise Comparison (A/B Evaluation)
Two model outputs are generated for the same input and shown side by side. The annotator simply picks which one is better or marks them as equal. This is more natural for humans because comparing two options is easier than assigning an absolute score.
- Easier than assigning absolute scores, humans are better at comparing than rating
- More consistent and reliable results than direct scoring
- Used by Hugging Face's Chatbot Arena, where real users vote on responses from two anonymous models in real time
- Widely used in RLHF (Reinforcement Learning from Human Feedback) to train better models
3. Ranking Evaluation
Annotators receive multiple outputs for the same input and rank them from best to worst.
- Useful when comparing three or more models simultaneously
- Gives richer signal than pairwise, you see the full order, not just who wins
- Requires more effort per annotation than pairwise comparison
- Common in machine translation shared tasks and LLM benchmarking competitions
Human Evaluation Criteria
The right criteria depend on the task, but these are the most commonly used
- **Fluency: Grammar, naturalness and readability of the output (Text generation, Translation)
- **Coherence: Logical flow and consistency of the response (Summarization, Dialogue)
- **Relevance: How well the output matches what was asked (Q/A, Search)
- **Factuality: Accuracy of information, free from hallucinations (Summarization, Q/A)
- **Helpfulness: Overall usefulness to a real user (Chatbots, Assistants)
When to Use Human vs Automated Evaluation
| Situation | Recommended Approach |
|---|---|
| Quick experiments during development | Automated metrics (BLEU, ROUGE, F1) |
| Final model comparison before release | Human evaluation (pairwise or rating) |
| Large scale evaluation on a budget | LLM as a judge calibrated with human data |
| Open ended generation tasks (chatbots) | Human evaluation or Chatbot Arena style |
| Classification / structured tasks | Automated metrics are usually sufficient |
Tips for Reliable Human Evaluation
- **Define clear guidelines: Give annotators precise rubrics with examples. Vague instructions lead to inconsistent and unreliable scores.
- **Use multiple annotators: A single person's judgment can be biased, so 2 to 3 annotators evaluate and their agreement is measured using Cohen's Kappa.
- **Keep tasks short and focused: Long annotation sessions cause fatigue and reduce quality. Break work into small, manageable batches.
- **Use a diverse dataset: Include edge cases, tricky inputs and varied topics, not just easy examples that every model handles well.
- **Always pilot test first: Run a small trial before scaling. Catch ambiguities in the rubric early, before they affect hundreds of annotations.
Advantages
- Captures qualities that automated metrics cannot, such as fluency, coherence and helpfulness
- Results closely reflect how a real user would experience the model output
- Flexible and applicable across all generative tasks like text, dialogue and summarization
- Provides richer and more meaningful feedback for model improvement
Limitations
- Time consuming and expensive to conduct at scale
- Results can be subjective and vary between different annotators
- Difficult to reproduce consistently across different evaluation setups
- Requires careful guideline design to ensure reliable and unbiased annotations