Reinforcement learning from Human Feedback (original) (raw)
Last Updated : 14 Apr, 2026
Reinforcement Learning from Human Feedback (RLHF) is a training approach used to align machine learning models specially large language models with human preferences and values. Instead of relying solely on predefined rules or labelled data, RLHF learns from human feedback or ratings such as rankings or evaluations of model outputs to guide learning.
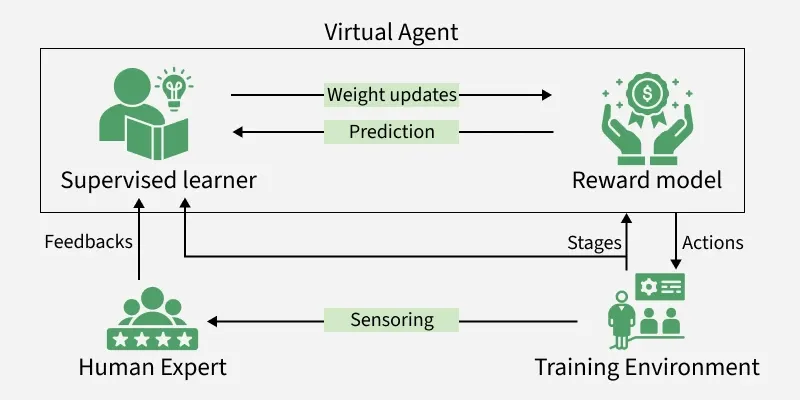
Workflow
It aligns AI behaviour with human values by using reinforcement learning guided by this feedback and helps the model generate responses that are not just accurate but also helpful, safe and aligned with human intent. It works in three stages:
1. Supervised Fine-Tuning (Initial Learning Phase)
This stage adapts a large pre-trained language model to specific tasks through supervised learning on examples selected by human experts. It prepares the model to respond in ways aligned with human instructions and establishes a foundation for subsequent human-in-the-loop refinement.
- Uses human-created prompt-response pairs as high-quality “teaching examples.”
- Fine-tuning sharpens the model’s ability to follow instructions and deliver relevant output.
- Reduces randomness and undesirable behavior compared to the original pre-trained model.
- Essential for grounding reinforcement learning in realistic initial behavior.
2. Reward Model Training (Human Feedback Integration)
Human evaluators rank or compare multiple completions produced by the model to provide better feedback which is unavailable in typical training data. This feedback trains a reward model that quantifies how desirable an output is which is crucial for guiding reinforcement learning.
- Human rankings capture subjective preferences like helpfulness, safety and factuality.
- The reward model translates complex human judgments into a numeric “reward” score.
- Acts as a scalable proxy for ongoing human evaluation during subsequent training.
- Enables continuous improvement without constant human labeling during RL optimization.
3. Policy Optimization (Reinforcement Learning Refinement)
Reinforcement learning algorithms fine-tune the model to generate responses that maximize rewards predicted by the reward model. This step improves alignment with human preferences by reinforcing desirable outputs.
In RLHF, the reward model provides feedback on how well responses match human expectations. Algorithms such as Proximal Policy Optimization (PPO) use this feedback to update the model in a stable and controlled manner.
- PPO limits large updates, ensuring stable and reliable training.
- Prevents the model from producing inconsistent or low-quality outputs.
- Enables gradual improvement through iterative learning.
This process helps the model generate responses that are more accurate, safe and aligned with human values.
RLHF in Autonomous Driving Systems
RLHF (Reinforcement Learning from Human Feedback) enhances autonomous driving systems by incorporating human feedback to improve decision-making beyond rule-based programming.
- The system is initially trained on large datasets and simulation-based reinforcement learning to learn traffic rules, navigation and obstacle avoidance.
- Human drivers and safety experts evaluate decisions such as lane changes, speed adjustments and responses to unexpected situations.
- Feedback is used to refine the reward function, improving safety, comfort and decision quality.
- Enables the system to handle complex real-world scenarios like unpredictable traffic conditions.
- Over time, the model becomes more context-aware, leading to safer and more reliable driving.
Applications of RLHF
- **Chatbots and Conversational AI: RLHF helps fine tune language models like ChatGPT to generate more helpful, polite and context aware responses based on human preferences.
- **Content Moderation: It enables AI systems to learn judgments from human reviewers improving the detection and handling of harmful or inappropriate content.
- **Recommendation Systems: By integrating user feedback RLHF refines recommendations to better reflect individual preferences and evolving user behavior.
- **Autonomous Vehicles: It can be used to train self driving cars to make safer and more human like driving decisions based on expert feedback.
Advantages
- **Enhanced Adaptability: RLHF enables AI systems to continuously learn and adapt to changing environments through iterative human feedback.
- **Human Centric Learning: By involving human evaluators it captures human intuition and expertise leading to more aligned and meaningful outputs.
- **Context Aware Decision Making: It improves the model’s ability to understand and respond to context which is important in areas like natural language processing.
- **Improved Generalization: Human guided learning helps models generalize better across tasks making them more versatile and effective in diverse scenarios.
Disadvantages
- **Bias Amplification: RLHF can unintentionally reinforce human biases if the feedback provided by evaluators is subjective or biased.
- **Imperfect Reward Modeling: The reward model may not fully capture human preferences, leading to incorrect or biased reward signals.
- **Limited Expertise: The quality of RLHF depends on expert feedback which may be scarce in specialized domains limiting the system’s effectiveness.
- **Complex Implementation: Integrating human feedback into the training loop is technically complex and requires careful system design and coordination.
- **Slow and Costly: It is resource intensive and time consuming due to repeated human evaluations and retraining making it less efficient for rapid adaptation.