Convolutional Neural Networks (CNNs) in R (original) (raw)
Last Updated : 11 Mar, 2026
Convolutional Neural Networks (CNNs) are deep learning models designed to analyze structured grid-like data such as images. They learn visual patterns directly from pixel values and identify features like edges, textures, shapes and objects. In R, CNN models can be built using libraries such as Keras and TensorFlow for tasks like image classification and object recognition.
- CNNs learn visual features automatically from images, starting with simple patterns like edges and textures and gradually learning more complex shapes and objects in deeper layers.
- Convolution operations capture spatial relationships between neighboring pixels, allowing the model to understand patterns and structures present in visual data.
- By sharing weights and focusing on local regions of an image, CNNs reduce the number of parameters and can recognize the same feature even if it appears in different positions.
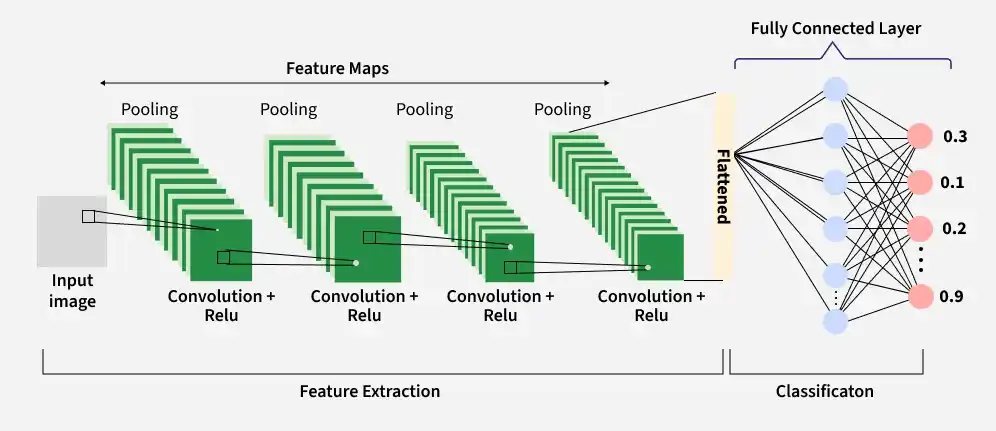
Convolutional Neural Networks
Key Components of Convolutional Neural Networks (CNN)
A Convolutional Neural Network (CNN) is composed of multiple layers, where each layer transforms the input data to extract increasingly complex features. These layers work together to learn patterns from images and perform tasks such as classification or object detection.
1. Input Layer
The input layer receives the raw image data and passes it to the network for further processing.
- Accepts image data in the form of a 3D volume (width × height × depth).
- Stores pixel intensity values of the image.
- Preserves the spatial structure of the image for feature extraction in later layers.
**Example: For an RGB image of size 32 × 32, the input volume becomes 32 × 32 × 3, where 3 represents the color channels (Red, Green, Blue).
2. Convolutional Layer
The convolutional layer extracts important visual patterns from the input using learnable filters.
- Applies small filters that slide across the input image.
- Performs element-wise multiplication between filter values and image patches.
- Generates feature maps that capture patterns such as edges, textures and shapes.
**Example: If 12 filters are applied to a 32 × 32 × 3 image, the output feature map volume may become 32 × 32 × 12.
3. Activation Layer
The activation layer introduces non-linearity into the network, allowing it to learn complex patterns.
- Applies an activation function to the output of the convolution layer.
- Enables the model to learn non-linear relationships in the data.
- Keeps the spatial dimensions of the feature maps unchanged.
**Example: Applying ReLU to a 32 × 32 × 12 feature map keeps the output size the same while transforming the values.
4. Pooling Layer
The pooling layer reduces the spatial size of feature maps to make the model more efficient.
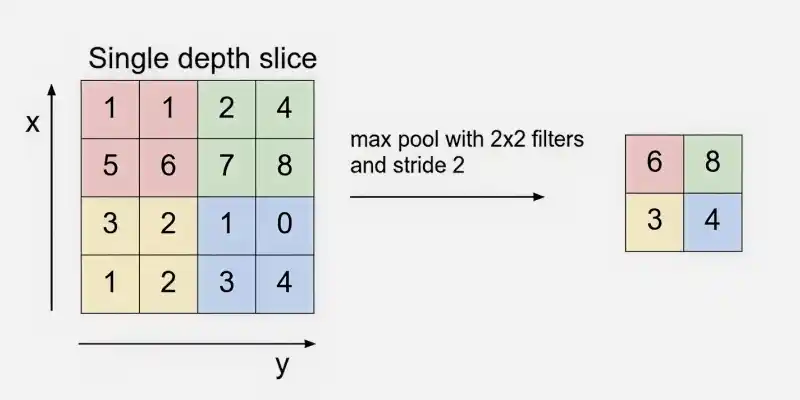
Max Pooling
- Downsamples the width and height of feature maps.
- Helps reduce computational cost and memory usage.
- Retains the most important information while discarding less useful details.
**Example: Applying 2 × 2 Max Pooling with stride 2 on 32 × 32 × 12 reduces it to 16 × 16 × 12.
5. Flattening
Flattening converts the multi-dimensional feature maps into a one-dimensional vector.
- Transforms feature maps into a vector format.
- Allows the data to be used by dense layers for classification.
- Acts as a bridge between convolutional layers and fully connected layers.
**Example: Flattening a 16 × 16 × 12 feature map produces a vector of size 3072.
6. Fully Connected Layer
The fully connected layer combines extracted features to perform prediction.
- Connects every neuron from the previous layer to neurons in the current layer.
- Performs high-level reasoning using learned features.
- Often used near the end of the CNN architecture.
**Example: The 3072-length vector from the flattening layer is connected to neurons that compute classification scores.
7. Dropout Layer
The dropout layer is used as a regularization technique to reduce overfitting during training.
- Randomly disables a fraction of neurons during each training iteration.
- Forces the network to learn more robust and generalized features.
- Improves the model’s ability to perform well on unseen data.
**Example: A dropout rate of 0.5 randomly deactivates 50% of neurons during training to prevent the model from relying too heavily on specific neurons.
8. Output Layer
The output layer produces the final prediction of the CNN model.
- Converts the network output into probability values.
- Uses activation functions depending on the task.
- Provides the final classification or prediction result.
**Example: For a 10-class classification problem, the Softmax function outputs 10 probability values, each representing the likelihood of a class.
How CNN Works
A Convolutional Neural Network processes an image through multiple layers to gradually extract features and make a final prediction. The process begins with the raw image as input and passes through convolution, activation, pooling and fully connected layers before producing the final output.
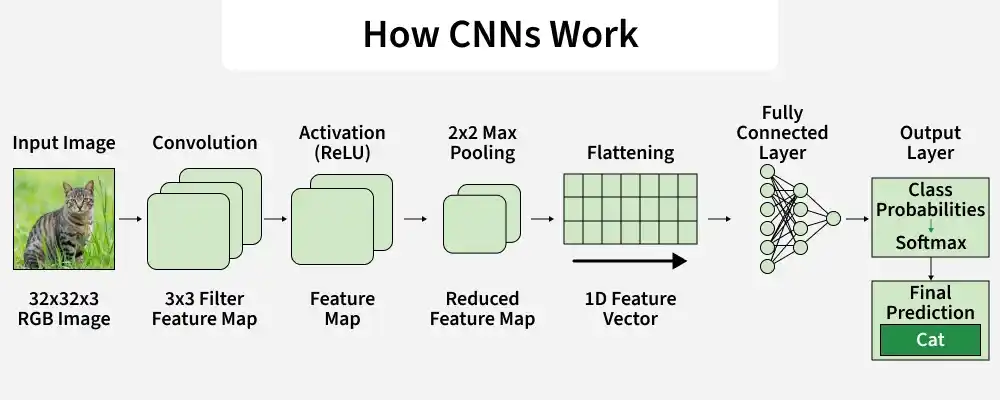
CNN working
**Step 1: The CNN receives the raw image as input in the form of a three-dimensional matrix representing width, height and color channels (RGB). This structure stores pixel intensity values while preserving the spatial arrangement of the image for feature learning.
**Step2: The convolution layer extracts important features from the input image using filters (kernels).
- A small matrix called a filter or kernel slides over the image.
- At each position, the filter performs element-wise multiplication with the corresponding image patch.
- The multiplied values are summed together to produce a single value in the output.
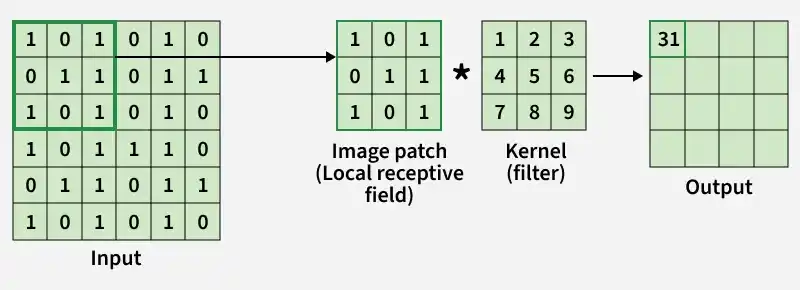
Convolution Operation
**Step 3: The convolution operation applies filters that move across the image using a defined stride to detect patterns. The output produced is called a feature map and multiple filters are used to capture different features such as edges, textures and shapes.
**Step4: After convolution, an activation function is applied to introduce non-linearity, allowing the model to learn complex patterns from the feature maps. The most commonly used activation function in CNNs is ReLU (Rectified Linear Unit).
**Step 5: Next, a pooling operation is applied the spatial dimensions of the feature maps while retaining important information.
**Step 6: In CNNs, convolution and pooling layers are repeated multiple times to learn deeper and more complex features. Early layers detect simple patterns like edges, while deeper layers capture textures, shapes and complex objects.
**Step 7: Next, flattening converts the multi-dimensional feature maps produced by convolution and pooling layers into a one-dimensional vector.
**Step 8: After flattening, the extracted features are passed to the fully connected layer, which performs high-level reasoning and produces the final prediction through the output layer.
- The fully connected layer connects neurons from the previous layer and combines learned features for classification.
- The output layer converts the final scores into probabilities using Sigmoid for binary classification or Softmax for multi-class classification.
Step By Step Implementation
Here we implement Convolutional Neural Network (CNN) in R using Keras and TensorFlow.
Step 1: Installing the required packages
Install and load the Keras library in R, which provides an interface for building deep learning models. The install_keras() function automatically installs the required TensorFlow backend and configures the Python environment needed to run neural networks.
R `
install.packages("keras") library(keras) install_keras()
library(tensorflow) tf$constant("Hello TensorFlow!")
`
**Output:
tf.Tensor(b'Hello TensorFlow!', shape=(), dtype=string)
Step 2: Loading and Preprocessing Datasets
Here we load the MNIST dataset and separate it into training and testing sets for building and evaluating the CNN model.
- **dataset_mnist(): Loads the MNIST dataset
- **mnist: Stores the dataset as a list containing both training and testing images with their labels.
- **x_train: Training images stored as a 3D array representing grayscale images.
- **y_train: Labels for training images indicating digits 0–9.
- **x_test: Test images with the same structure as x_train.
- **y_test: Labels for the test images used to evaluate the model. R `
Load the keras library
library(keras)
Load the MNIST dataset
mnist <- dataset_mnist()
Split into training and testing datasets
x_train <- mnist$train$x y_train <- mnist$train$y x_test <- mnist$test$x y_test <- mnist$test$y
`
Step 3: Preprocessing the Images
In this step, the images are reshaped to include a single channel (28 × 28 × 1) and normalized to the range [0, 1] to improve CNN training efficiency.
R `
Reshape the images to (28, 28, 1) and normalize pixel values to the range [0, 1]
x_train <- array_reshape(x_train, c(nrow(x_train), 28, 28, 1)) x_test <- array_reshape(x_test, c(nrow(x_test), 28, 28, 1))
x_train <- x_train / 255 x_test <- x_test / 255
`
Step 4: One-Hot Encoding the Labels
Here the class labels are converted into one-hot encoded vectors so the CNN can perform multi-class classification.
- **one_hot_encode(labels, num_classes): Converts class labels into a one-hot encoded matrix.
- **labels: Vector of integer class labels (e.g., 0–9).
- **num_classes: Total number of classes.
- **encoded_labels: Matrix initialized with zeros (rows = number of samples, columns = number of classes).
- **encoded_labels[i, labels[i] + 1] <- 1: Sets the correct class index to 1 for each label (R uses 1-based indexing R `
one_hot_encode <- function(labels, num_classes) {
Create a matrix of zeros
encoded_labels <- matrix(0, nrow = length(labels), ncol = num_classes)
Set the appropriate index to 1 for each label
for (i in seq_along(labels)) { encoded_labels[i, labels[i] + 1] <- 1 }
return(encoded_labels) }
Apply the custom one-hot encoding function
y_train <- one_hot_encode(y_train, 10) y_test <- one_hot_encode(y_test, 10)
`
Step 5: Verifying Data Structure
We check the dimensions and structure of the preprocessed images and one-hot encoded labels to ensure they are ready for training the CNN.
R `
Check dimensions and type of data
str(x_train) str(y_train)
`
**Output:
num [1:60000, 1:28, 1:28, 1] 0 0 0 0 0 0 0 0 0 0 ...
num [1:60000, 1:10] 0 1 0 0 0 0 0 0 0 0 ...
Step 6: Building the CNN Model
Define the CNN architecture by stacking convolutional, pooling, flattening and fully connected layers to extract features and perform classification.
- **layer_conv_2d(): Adds convolutional layers to detect features such as edges, textures and shapes.
- **layer_max_pooling_2d(): Reduces spatial dimensions and controls overfitting by keeping important features.
- **layer_flatten(): Converts multi-dimensional feature maps into a 1D vector for fully connected layers.
- **layer_dense() and layer_dropout(): Fully connected layers perform classification, with dropout used to prevent overfitting.
- **Output layer (softmax): Produces probabilities for each of the 10 digit classes. R `
Initialize the model
model <- keras_model_sequential()
Add convolutional layers
model %>% layer_conv_2d(filters = 32, kernel_size = c(3, 3), activation = 'relu', input_shape = c(28, 28, 1)) %>% layer_max_pooling_2d(pool_size = c(2, 2)) %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), activation = 'relu') %>% layer_max_pooling_2d(pool_size = c(2, 2)) %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), activation = 'relu') %>% layer_max_pooling_2d(pool_size = c(2, 2)) %>%
Flatten the output from convolutional layers
layer_flatten() %>%
Add fully connected layers
layer_dense(units = 128, activation = 'relu') %>% layer_dropout(rate = 0.5) %>% layer_dense(units = 10, activation = 'softmax') # Output layer for 10 classes
`
Step 7: Compiling and Training the CNN
Here we compile the CNN with an optimizer, loss function and metrics, then train it on the dataset while monitoring validation performance.
- **optimizer_adam(): Uses the Adam optimizer, which adapts the learning rate for faster and efficient training.
- **categorical_crossentropy: Loss function for multi-class classification with one-hot encoded labels.
- **c('accuracy'): Metric used to evaluate model performance during training.
- **epochs: Number of times the entire dataset is passed through the model.
- **batch_size: Number of samples processed before updating the model weights.
- **validation_split: Training data reserved for validation to monitor performance on unseen data. R `
model %>% compile( optimizer = optimizer_adam(), loss = 'categorical_crossentropy', metrics = c('accuracy') )
history <- model %>% fit( x_train, y_train, epochs = 10, batch_size = 64, validation_split = 0.2 )
`
Step 8: Evaluating the CNN Model
Trained CNN is evaluated on the test dataset to measure its final performance in terms of loss and accuracy on unseen data.
R `
score <- model %>% evaluate(x_test, y_test) print(score)
Print evaluation results
cat('Test loss:', score$loss, '\n') cat('Test accuracy:', score$accuracy, '\n')
`
**Output:
loss accuracy
0.05012181 0.98710001
Test loss: 0.05012181
Test accuracy: 0.9871
Step 9: Visualizing Training History
Here we plot the training and validation accuracy and loss over epochs to monitor the model’s learning progress and detect overfitting or underfitting.
R `
Plot training & validation accuracy values
plot(history$metrics$accuracy, type = 'l', col = 'blue', ylim = c(0, 1), xlab = 'Epoch', ylab = 'Accuracy', main = 'Model Accuracy') lines(history$metrics$val_accuracy, type = 'l', col = 'red') legend("bottomright", legend = c("Training Accuracy", "Validation Accuracy"), col = c("blue", "red"), lty = 1)
Plot training & validation loss values
plot(history$metrics$loss, type = 'l', col = 'blue', ylim = c(0, max(history$metrics$loss, history$metrics$val_loss)), xlab = 'Epoch', ylab = 'Loss', main = 'Model Loss') lines(history$metrics$val_loss, type = 'l', col = 'red') legend("topright", legend = c("Training Loss", "Validation Loss"), col = c("blue", "red"), lty = 1)
`
**Output:
Download full code from here
Applications
- **Image Classification: Automatically categorizes images into predefined classes such as handwritten digits, animals or objects.
- **Object Detection: Identifies and localizes multiple objects within an image, used in self-driving cars and surveillance.
- **Facial Recognition: Detects and recognizes faces for authentication and security systems.
- **Medical Imaging: Assists in diagnosing diseases by analyzing X-rays, MRIs or CT scans.
- **Natural Language Processing (NLP): Extracts features from text when represented as images or embeddings, e.g., sentiment analysis.
- **Video Analysis: Recognizes actions or events in videos for applications like sports analytics and video surveillance.
- **Autonomous Vehicles: Detects lanes, obstacles and traffic signs for navigation and safety.
Advantages
- CNNs automatically learn hierarchical features from raw data without manual feature engineering.
- CNNs achieve high accuracy in image and visual data analysis tasks.
- They are effective in handling variations and noise in input images.
- CNNs can be scaled to large datasets and complex architectures for advanced applications.
- They are versatile and can be applied to images, videos and even text when represented as grid-like data.
Limitations
- CNNs require a large amount of labeled data for effective training.
- They are computationally intensive, needing high-performance GPUs for large models.
- CNNs can be prone to overfitting if the dataset is small or not diverse.
- They are often considered black-box models, making interpretation and explainability difficult.
- Performance can drop on images with distortions or unseen variations not present in the training data.