What is Quantization (original) (raw)
Last Updated : 6 Nov, 2025
Quantization is a model optimization technique that reduces the precision of numerical values such as weights and activations in models to make them faster and more efficient. It helps lower memory usage, model size, and computational cost while maintaining almost the same level of accuracy.
Quantization
Need of Quantization
In Large Language Models which contain billions of parameters, quantization plays a crucial role. These parameters are typically stored as 32-bit (FP32) or 16-bit (FP16) values that require significant computational resources. Quantization converts them into lower-precision formats like 8-bit (INT8) or 4-bit (INT4) which allows faster inference and reduced hardware requirements making large models more practical for real-world deployment.
- **Reduced Model Size: Using smaller data types requires fewer bits per parameter, significantly lowering memory usage.
- **Faster Inference: Lower-precision computations (like INT8 or INT4) execute faster on CPUs, GPUs and specialized hardware.
- **Edge Deployment: Quantized models can efficiently run on low-power devices such as mobiles and embedded systems.
- **Lower Operational Costs: By cutting down on power and memory needs, quantization helps minimize overall infrastructure expenses.
How It Works
Quantization is all about making your model lighter and faster without hurting its accuracy too much. It does this by converting high-precision numbers like floats into lower-precision integers (like INT8).
The process revolves around two key parts:
- **Weight Quantization: Compresses the trained model’s parameters.
- **Activation Quantization: Compresses the outputs generated during inference.
Now lets see its working:
**1. Range Determination
Model figures out the range of values (minimum and maximum) that each weight or activation can take. In Static Quantization, this range is calculated beforehand using a calibration dataset. In Dynamic Quantization, the range is determined on the fly during inference.
**2. Scaling and Zero-Point Calculation
Once the range is known, the next step is to map floating-point values into an integer space (for example, from -1 to 1 → 0 to 255).
- **Scale (S): Defines how much to stretch or shrink the numbers.
S = \frac{x_{\text{max}} - x_{\text{min}}}{q_{\text{max}} - q_{\text{min}}}
- **Zero-Point (Z): The integer that represents “zero” in the float domain.
Z = q_{\text{min}} - \frac{x_{\text{min}}}{S}
where
- x_{\text{min}}, x_{\text{max}} : min and max of the floating-point range
- q_{\text{min}}, q_{\text{max}}: min and max of the integer range (e.g., -128 to 127 for INT8)
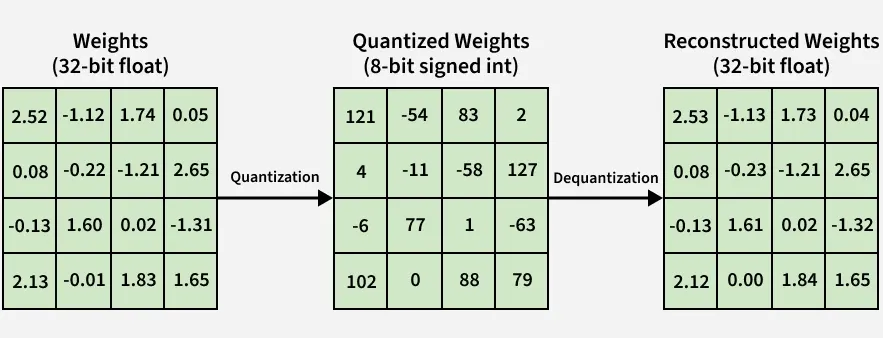
**3. Quantization and Dequantization
**Quantization: Converts floats to integers using
x_q = \text{round}\left(\frac{x}{S} + Z\right)
**Dequantization: Converts them back for interpretation using
x = S \times (x_q - Z)
where
- x: Original floating-point value
- S: Scale factor
- Z: Zero-point
- x_q: Quantized integer value
Types of Quantization
Types of Quantization refer to the different techniques used to reduce model size and computation needs while maintaining accuracy. Each type balances precision, speed and memory efficiency differently, depending on the target hardware and task requirements.
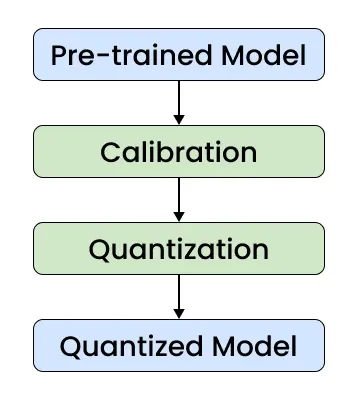
1. Post-Training Quantization (PTQ)
PTQ
- Quantization is applied after the model is fully trained, converting high-precision parameters (like FP32 weights and activations) into lower-bit formats such as INT8 to reduce computational load and memory usage.
- The two primary techniques are Static Quantization which is pre-calibrated with representative data and Dynamic Quantization where activations are quantized on the fly during inference.
- Enables faster inference and smaller model size without retraining, making it ideal for deploying large language models on edge devices or latency-sensitive environments.
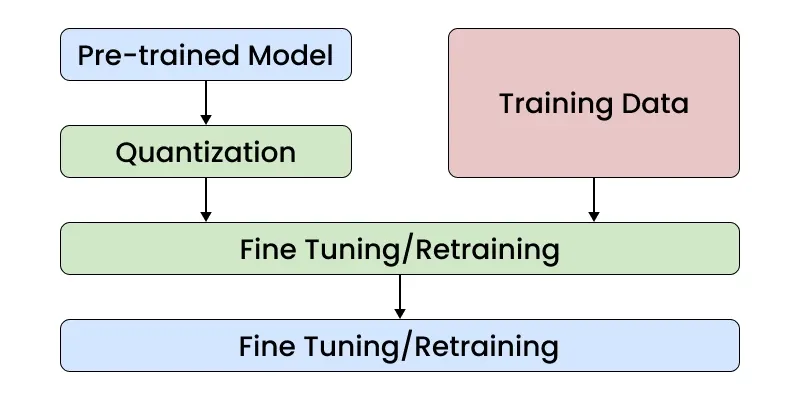
2. Quantization-Aware Training (QAT)
QAT
- The model is trained with quantization in mind, simulating low-precision operations during training.
- Helps the model adapt to quantization effects and minimize accuracy loss.
- Delivers higher accuracy than Post-Training Quantization (PTQ) by learning to handle reduced precision.
Quantization Technique
Lets see various Quantization Techniques that we can use:
**1. QLoRA (Quantized Low-Rank Adaptation)
- QLoRA combines Low-Rank Adaptation (LoRA) with quantization to fine-tune large models efficiently.
- Uses NF4 (NormalFloat 4-bit) and Double Quantization (DQ) for additional memory reduction.
- Enables running massive models on single GPUs without major accuracy loss.
**2. GPTQ (General Pre-Trained Transformer Quantization)
- Performs layer-wise quantization while minimizing Mean Squared Error (MSE) between original and quantized outputs.
- Uses INT4/FP16 mixed precision — weights in INT4, activations in FP16 for balance between speed and precision.
- Ideal for GPU inference, offering high precision and efficient memory use.
**3. Uniform Quantization
- Divides continuous floating-point ranges into equal intervals, mapping each to a discrete integer level.
- Maintains a linear float–integer relationship for predictable, efficient computations.
- Ideal for edge devices and AI accelerators requiring fast, low-power inference.
**4. Non-Uniform Quantization
- Uses unequal interval sizes to allocate higher precision where it matters most.
- Assigns smaller intervals to frequently occurring or performance-critical values.
- Preserves accuracy while reducing size ideal for non-linear or skewed weight distributions.
**5. Min-Max Quantization
- Defines the quantization range using the minimum and maximum of weights or activations.
- Linearly scales data into a fixed integer range (e.g., INT8) for efficient computation.
- Simple and effective but sensitive to outliers. It also often requires calibration or clipping to maintain accuracy.
**6. Logarithmic Quantization
- Uses a logarithmic scale instead of a linear one to handle wide variations in weight or activation magnitudes.
- Provides finer precision for small values and efficient compression for larger ones.
- Ensures better dynamic range coverage, ideal for deep networks with diverse parameter scales.
Quantization in ML, DL and LLMs
Quantization plays a slightly different role across Machine Learning (ML), Deep Learning (DL) and Large Language Models (LLMs). While the core idea remains the same i.e reducing precision to save resources but the impact vary depending on the model type.
| Aspect | Quantization in ML | Quantization in DL | Quantization in LLMs |
|---|---|---|---|
| **Purpose | Simplify models for faster inference and deployment | Reduce model size and computation during training and inference | Make large-scale models efficient for inference and deployment |
| **Data Type Precision | Usually converts float to integer (e.g FP32 → INT16) | Converts weights and activations to lower precision (e.g FP32 → INT8) | Converts billions of parameters to 8-bit or 4-bit precision (e.g FP16 → INT4) |
| **Impact on Accuracy | Minor or negligible | Slight accuracy drop if not calibrated well | Accuracy may drop slightly but can be managed with fine-tuning |
| **Use Case | Small or traditional ML models like regression or decision trees. | Neural networks and CNNs for vision or speech tasks | Transformer-based models like GPT, LLaMA or BERT |
| **Goal | Reduce latency and improve inference speed | Optimize GPU/TPU usage and training efficiency | Enable deployment on limited hardware like consumer GPUs or edge devices. |
Step-By-Step Implementation
Here we load a lightweight language model in 4-bit quantized mode (QLoRA) to reduce memory usage. Then, we ask it questions and generate natural text answers directly from the quantized model.
Step 1: Importing Required Libraries
- **torch: Here we will import pytorch for tensor operations and model inference.
- **transformers: Transformer library provides model and tokenizer APIs from Hugging Face.
- **BitsAndBytesConfig: Enables 4-bit quantization using the bitsandbytes backend (core of QLoRA). Python `
import torch from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
`
Step 2: Selecting a LLM
TinyLlama is a 1.1B parameter model.
Python `
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
`
Step 3: Defining the Quantization Configuration
- **load_in_4bit: loads model weights in 4-bit precision.
- **bnb_4bit_use_double_quant applies nested quantization for extra compression.
- **bnb_4bit_quant_type uses NormalFloat4 which provides high accuracy in QLoRA setups.
- **bnb_4bit_compute_dtype performs computations in FP16 for faster inference. Python `
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
`
Step 4: Loading the Model and Tokenizer
- **Tokenizer: Converts text into numerical tokens for the model.
- **model: Loads pre-trained weights using the quantization settings above.
- **device_map: Automatically distributes model layers to available GPU(s) or CPU. Python `
tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=bnb_config, device_map="auto" )
`
**Output:

Load Quantized Model
Step 5: Creating a Function to Ask Questions
- **Chat-style Prompting: Uses TinyLlama’s special chat tokens to structure input. These tokens help the model understand roles and respond appropriately.
- **do_sample: Enables probabilistic sampling for natural, diverse text.
- **top_p: Uses nucleus sampling to choose from the most likely next tokens.
- **temperature: Controls randomness (lower = more deterministic).
- **repetition_penalty: Prevents repeating phrases or tokens.
- **pad_token_id: Ensures the model stops correctly during generation. Python `
def ask_question(question, max_new_tokens=128): prompt = f"<|system|>\nYou are a helpful assistant.<|user|>\n{question}<|assistant|>\n" inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate( **inputs, max_new_tokens=max_new_tokens, do_sample=True, top_p=0.9, temperature=0.7, repetition_penalty=1.1, pad_token_id=tokenizer.eos_token_id ) response = tokenizer.decode(outputs[0], skip_special_tokens=True) if "<|assistant|>" in response: response = response.split("<|assistant|>")[-1].strip() return response
`
Step 6: Testing the Quantized Model
- The loop iterates through a list of sample questions.
- Each question is passed to the ask_question() function. Python `
questions = [ "What are the advantages of using 4-bit quantization in large language models?" ]
for q in questions: print("\nQuestion:", q) print("Answer:", ask_question(q))
`
**Output:

Output
You can download the complete code file from here.
Applications of Quantization
- **Embedded Systems: Quantization is widely used in embedded systems for real-time inference tasks such as anomaly detection in industrial IoT systems, facial recognition in surveillance systems or voice processing in smart speakers.
- **Healthcare Devices: AI models in portable medical devices such as wearable health monitors or diagnostic tools, uses quantization to ensure fast and efficient operation.
- **Model Optimization for Inference: It speeds up inference by reducing computational load. This makes models like GPT and BERT more responsive during real-time interactions.
- **Edge and Mobile Deployment: By lowering precision to INT8 or INT4, large models can run efficiently on edge devices, smartphones and IoT hardware with limited resources.
- **Latency Reduction: It speeds up matrix multiplications and attention mechanisms. This enhances user experience in chatbots and virtual assistants.
- **Cost-Effective Scaling: Companies use quantized LLMs to lower cloud inference costs while keeping similar accuracy to full-precision models.
Benefits of Quantization
- **Memory Efficiency: Quantized models have a much smaller memory footprint. For example, an INT8 model can be 4 times smaller than an FP32 model which is significant for deploying models on devices with limited memory.
- **Inference Speed: Quantized models run faster on hardware with specialized support for low-precision operations such as NVIDIA TensorRT or Google TPU, resulting in reduced inference time and improved user experience on mobile applications.
- **Power Efficiency: Quantization significantly reduces power consumption during inference which is vital for edge devices like smart cameras, drones or wearables.
Challenges
- **Accuracy Drop: Lowering precision from FP32 to INT8 may cause quantization errors, reducing model accuracy in complex reasoning tasks.
- **Architecture Sensitivity: Transformer-based LLMs often show instability when quantized aggressively due to sensitive attention layers.
- **Calibration Difficulty: Determining correct activation and weight ranges is challenging and can lead to distorted outputs if done poorly.
- **Training Overhead: Quantization-Aware Training (QAT) improves accuracy but demands heavy computation and large datasets.
- **Hardware Constraints: Some devices lack efficient low-bit arithmetic support, limiting deployment of advanced quantization schemes like INT4.